Google DeepMind, 로컬 AI를 4배 빠르게 실행하는 DiffusionGemma 모델 출시
출처: Ars Technica
로컬 효율성을 위한 다양한 경로
확산이 훨씬 빠른데 왜 구글은 이를 대규모 클라우드 기반 Gemini 모델에 사용하지 않을까요? 구글은 이렇게 실험해봤습니다, 하지만 텍스트 확산에는 몇 가지 단점이 있습니다. 오류율이 더 높다는 점이 그 중 하나죠. 이미지 확산 모델에서는 하나의 잘못 예측된 픽셀이 이미지 전체를 쓸모 없게 만들지는 않지만, 언어는 이산적입니다. 텍스트에서 동등한 오류가 발생하면 토큰 블록 전체가 의미를 잃고 더 나은 출력을 얻기 위해 처음부터 다시 시작해야 할 수 있습니다. 또한 원하는 출력이 몇 개 안 되는 토큰일 때 확산 모델은 많은 병렬 작업을 수행해야 합니다. 예를 들어 다섯 개 토큰을 생성하려면, 자동 회귀 모델은 시작부터 끝까지 단 5단계만에 만들 수 있지만, 확산 모델은 그보다 훨씬 많은 단계를 거쳐야 합니다.
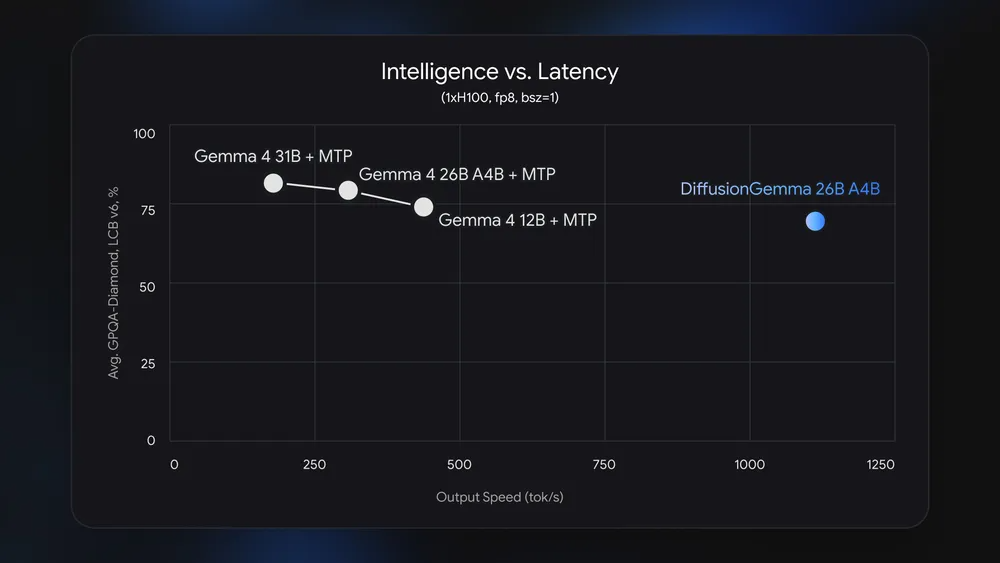
DiffusionGemma는 다른 Gemma 모델과 비슷한 성능을 보이지만, 훨씬 빠릅니다.
출처:
Google
DiffusionGemma는 다른 Gemma 모델과 비슷한 성능을 보이지만, 훨씬 빠릅니다.
출처:
Google
클라우드에서는 자동 회귀 모델이 여러 사용자의 대규모 연산 작업을 배치(batch)하여 항상 토큰을 생성하고, 이러한 시스템에 사용되는 고대역폭 메모리(HBM)는 데이터를 훨씬 효율적으로 이동시킵니다. 반면 로컬 AI는 메모리 대역폭이 낮고 유휴 시간이 발생해 연산 사이클이 낭비됩니다. 확산 모델은 사용 가능한 연산 자원을 보다 효율적으로 활용할 수 있지만, 이것이 유일한 방법은 아닙니다. 구글은 최근 멀티 토큰 예측(Multi-Token Prediction, MTP) 초안 작성기 도 도입했으며, 이는 낭비되는 연산 사이클을 활용해 가능한 토큰을 예측함으로써 속도를 높입니다. 그러나 확산은 MTP 버전의 Gemma보다도 더 빠릅니다.
구글은 DiffusionGemma가 실험적인 모델이라고 강조하지만, 다른 4세대 Gemma 모델과 동일한 Apache 2.0 라이선스로 제공됩니다. 모델 가중치는 오늘 바로 **Hugging Face**에서 다운로드할 수 있습니다. 구글은 Nvidia와 협력해 DiffusionGemma가 고성능 RTX GPU(양자화)와 H100 또는 DGX Spark 플랫폼과 같은 엔터프라이즈 시스템을 포함한 다양한 환경에 최적화되도록 했다고 밝혔습니다.