Anthropic, Fable 5 모델이 다루기엔 위험한 주제라고 밝힘
출처: Ars Technica
Anthropic은 화요일에 Claude Fable 5를 공개했습니다(공식 발표). 이는 “Mythos‑class” 모델 중 첫 번째로, 이전의 Opus 시리즈보다 전반적인 능력이 뛰어나다고 주장합니다. 하지만 이번 모델 출시와 동시에 사이버보안, 생물학, 화학 등과 같은 주제에 대한 질문에 답하지 못하도록 하는 안전장치가 적용되었습니다. Anthropic은 이러한 분야가 악의적인 행위자에게 “도구”가 될 위험이 있다고 공개적으로 우려해 왔습니다(관련 기사).
Anthropic에 따르면 Fable 5는 “Mythos 5와 동일한 기본 모델” 위에서 동작하지만, 현재는 신뢰할 수 있는 사이버 방어자 그룹에게만 제한적으로 제공됩니다. 이 그룹은 기존의 Project Glasswing(https://www.anthropic.com/glasswing)에서 신뢰성을 검증받았습니다. Mythos 5와 달리, 공개된 Fable 5는 특정 민감 주제에 대한 질의가 들어오면 이전 버전인 Claude Opus 4.8 모델로 전달하고, 그 과정에서 사용자에게 경고를 표시하도록 설계되었습니다.
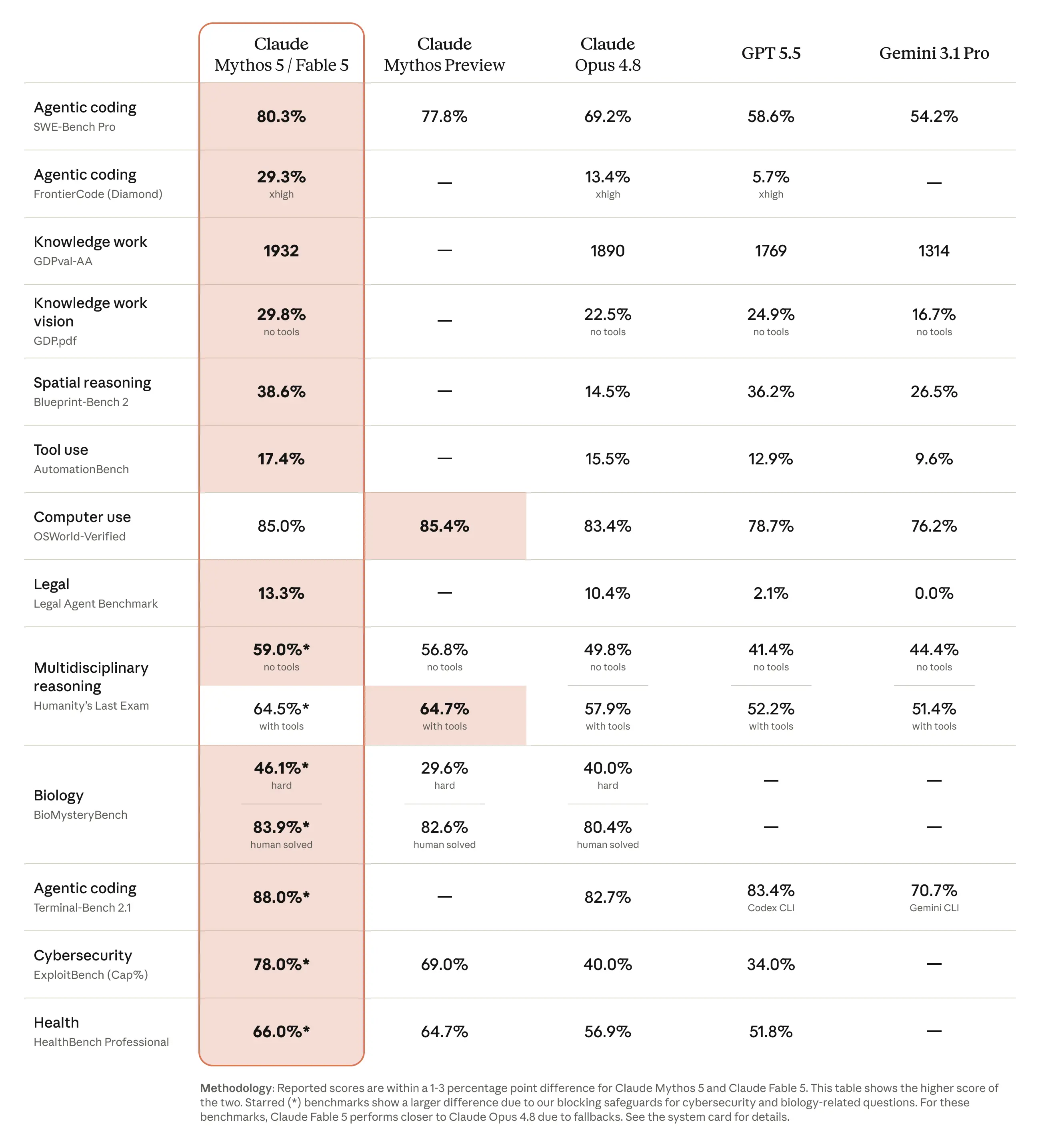
다수의 벤치마크 개선 중, 사이버보안 관련 성능이 특히 크게 향상되었습니다.
크레딧: Anthropic
Anthropic은 이러한 안전장치를 “이상적인 수준보다 더 엄격하게” 조정했으며, 그 결과 시스템이 가끔 무해한 요청조차 거부할 수 있다고 밝혔습니다. 이는 일반 사용자에게는 다소 답답하게 느껴질 수 있지만, 테스트에서는 전체 세션의 5% 미만에서만 발생했으며, “다른 경로로는 얻을 수 없던 심각한 피해를 악의적인 행위자가 입히는 상황”을 방지하는 데 큰 의미가 있다고 설명했습니다.
나는 그걸 허락할 수 없어, 데이브
Fable 5의 주제 기반 안전장치는 분류기 시스템(https://www.anthropic.com/research/next-generation-constitutional-classifiers)을 기반으로, 금지된 프롬프트 주제와 잠재적인 탈옥 시도를 폭넓게 탐지하도록 설계되었습니다. 1,000시간 이상의 레드팀 테스트와 버그 바운티 프로그램을 통해 외부 팀은 Fable 5에 대한 보편적인 탈옥 방법을 찾지 못했다고 Anthropic은 전합니다. 또한 새로운 모델은 이전 Claude Opus 시리즈보다 자동 탈옥 시도에 훨씬 더 강인하게 저항했습니다.
Anthropic은 특히 Mythos 5가 **“에이전트형 해킹”**을 수행할 수 있는 능력—다중 단계 사이버 공격을 이전 모델보다 훨씬 수월하게 실행하는 것—에 대해 우려하고 있습니다. 그러나 영국 AI Security Institute의 최근 테스트 결과에 따르면, Mythos Preview는 OpenAI GPT‑5.5와 비슷한 수준의 Capture the Flag 과제 수행 능력을 보였으며, 이는 “특정 모델에만 국한된 획기적인 성능”이 아니라는 점을 시사합니다(https://arstechnica.com/ai/2026/05/amid-mythos-hyped-cybersecurity-prowess-researchers-find-gpt-5-5-is-just-as-good/).