🍵 Linear Regression 零基础入门——茶的零知识类比
Source: Dev.to
机器学习可能让人望而生畏——梯度、代价函数、正则化、过拟合……听起来像外语。
所以我们先把这些术语抛开。
想象你经营一个 茶摊。每天你记录:
- 温度
- 卖出的茶杯数
你的目标是什么? 👉 预测明天的茶叶销量。
仅凭这个目标,你就能学会以下所有内容:
- Linear Regression
- Cost Function
- Gradient Descent
- Over‑fitting
- Regularization
- Regularized Cost Function
让我们开始吧。
⭐ 场景 1:什么是线性回归?
根据温度预测茶叶销量
你注意到:
| 温度 (°C) | 售出茶杯数 |
|---|---|
| 10 | 100 |
| 15 | 80 |
| 25 | 40 |
存在一个模式:温度越低 → 茶卖得越多。
线性回归尝试绘制一条直线,以最佳地表示这种关系:
[ \hat{y}=mx+c ]
- (x) = 温度
- (\hat{y}) = 预测的茶叶销量
- (m) = 斜率(每升高一度茶叶销量下降多少)
- (c) = 基准茶需求
就是这样——一条简单的直线,用来预测明天的茶叶销量。
⭐ 场景 2:成本函数
衡量预测错误程度
今天的温度:20 °C
你的模型预测:60 杯
实际值:50 杯
误差 = 10 杯
成本函数为你的整体错误程度提供一个分数:
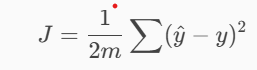
为什么要平方?
因为错误 30 杯 远比错误 3 杯 严重,模型应该学习到这一点。
成本越低 → 模型越好。
⭐ 场景 3:Gradient Descent
逐步改进的艺术
想象你正在尝试一种新的茶配方:
- 添加更多糖 → 太甜
- 少加一点 → 太淡
- 慢慢调整直到完美
这就是梯度下降。
模型会逐步调整:
- 斜率 ((m))
- 截距 ((c))
一步一步地降低代价函数。
把代价函数想象成一座 hill。你站在山上的某个位置。你的目标是走下去,达到 lowest point。那个最低点 = 最佳模型。
⭐ 场景 4:过拟合
当你的模型过度努力并学习“噪声”
假设你每天记录过多细节:
- 温度
- 湿度
- 降雨
- 风
- 节日
- 板球比赛得分
- 交通
- 你邻居的狗叫声
- 顾客衬衫的颜色
- 天空的云量
你的模型试图使用所有信息,即使是不重要的东西。
这会导致过拟合:
- 模型在训练数据上表现很好
- 但在新数据上表现糟糕
它是记忆而不是理解一般模式。
⭐ 场景 5:我们如何解决过拟合?
- ✔ 删除无用特征 – 忽略“狗叫”等噪声。
- ✔ 收集更多数据 – 更多示例 → 更清晰的模式。
- ✔ 应用正则化 – 最强有力的解决方案。
⭐ 场景 6:什么是正则化?
添加惩罚以防模型过度思考
在你的茶摊上,如果茶师使用 太多配料,茶会变得:
- 令人困惑
- 浓烈
- 昂贵
- 不可预测
于是你对他说:
“少用点配料。如果你用太多,我会削减你的奖金。”
这个惩罚迫使他制作 简单且一致的茶。
正则化对机器学习模型也做同样的事。它说:
“如果你的模型变得太复杂,我会提高你的成本。”
这迫使模型只保留 重要特征。
⭐ 场景 7:正则化线性回归
(详细解释)
正则化会修改原始的代价函数:
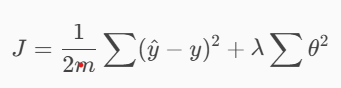
其中:
- (\theta) = 模型参数(每个特征的权重)
- (\lambda) = 正则化强度((\lambda) 越大,惩罚越强)
🟦 这个惩罚有什么作用?
想象你跟踪 10 个特征:
- 温度
- 湿度
- 风速
- 降雨
- 节日
- 星期几
- 道路交通
- 板球比赛得分
- 当地噪声水平
- 狗叫频率
你的模型试图解释 所有 这些特征。有些权重会变得很大:
| 特征 | 权重 |
|---|---|
| 温度 | 1.2 |
| 节日 | 2.8 |
| 交通 | 3.1 |
| 狗叫 | 1.5 |
| 噪声水平 | 2.4 |
权重过大 = 模型认为这些特征极其重要,即使其中很多其实是随机噪声。
正则化会加入惩罚,使这些权重收缩:
- 温度 → 仍然重要
- 节日 → 略有降低
- 狗叫 → 向 0 收缩
- 噪声 → 向 0 收缩
这会让你的模型 更简洁、更具泛化能力,也更准确。
⭐ 场景 8:正则化如何解决过拟合
(深度真实场景)
正则化前:过度思考模型
你的模型会注意到所有随机细节:
有一天下雨 且 印度赢得了一场比赛 且 正在举办节日 且 天气寒冷 且 交通稀少…… 那天茶叶销量很高。
于是你的模型会认为:
- “降雨使茶叶销量提升 6 %”
- “板球比赛结果使销量提升 8 %”
- “狗叫声使销量下降 2 %”
- “交通状况使销量提升 4 %”
- …等等。
这是一种 记忆巧合——典型的过拟合。
正则化后:
正则项迫使模型只保留真正具有预测性的特征(例如温度),并将噪声特征(狗叫声、板球比分等)压向零。得到的模型能够很好地推广到新的一天,提供更可靠的销量预测。
正则化:成熟模型
正则化会压缩无用的权重:
- Dog barking → 0
- Cricket match → 0
- Noise → 0
- Traffic → 微小
- Festival → 中等
- Temperature → 保持强劲
- Rain → 中等
模型学习到:
“Sales mainly depend on Temperature + Rain + Festival days. Everything else is noise.”
“销售主要取决于 温度 + 雨量 + 节假日。其他的都是噪声。”
为什么正则化有帮助
- 减少对随机细节的依赖
- 鼓励简单规则
- 提升对未来数据的泛化能力
这就是正则化在真实机器学习中必不可少的原因。
🎯 FINAL TL;DR(适合初学者)
| Concept | Meaning | Tea‑Stall Analogy |
|---|---|---|
| Linear Regression | 最佳直线拟合 | 根据温度预测茶叶销量 |
| Cost Function | 衡量错误程度 | 预测值与实际茶叶销量的差距 |
| Gradient Descent | 优化技术 | 调整茶叶配方直至完美 |
| Overfitting | 模型记住噪声 | 记录狗叫声和板球比赛的细节 |
| Regularization | 对复杂度的惩罚 | 强迫茶师使用更少的配料 |
| Regularized Cost | 正常成本 + 惩罚 | 防止对预测“思考过度” |