시각적인 Python 예제로 ReLU 이해
Source: Dev.to
ReLU를 시각적으로 이해하기 (Python 예제)
ReLU(Rectified Linear Unit)는 딥러닝에서 가장 널리 사용되는 활성화 함수 중 하나입니다. 이 글에서는 시각적인 예제와 Python 코드를 활용한 실험을 통해 ReLU가 어떻게 동작하는지 직관적으로 살펴보겠습니다.
1. ReLU란 무엇인가?
ReLU는 입력값이 0보다 작으면 0을, 0보다 크면 그대로 값을 반환하는 아주 간단한 함수입니다.
[ \text{ReLU}(x) = \max(0, x) ]
- 장점
- 계산이 매우 빠름
- 기울기 소실(vanishing gradient) 문제를 완화
- 단점
- 입력이 0 이하일 때 뉴런이 완전히 비활성화돼 “죽은 뉴런(dead neuron)” 문제가 발생할 수 있음
2. ReLU 시각화
아래 코드는 numpy와 matplotlib을 이용해 ReLU 함수와 그 미분(기울기)을 그래프로 그립니다.
import numpy as np
import matplotlib.pyplot as plt
# 입력 범위 정의
x = np.linspace(-5, 5, 400)
# ReLU 함수
def relu(x):
return np.maximum(0, x)
# ReLU의 미분 (기울기)
def relu_grad(x):
return np.where(x > 0, 1, 0)
y = relu(x)
dy = relu_grad(x)
# 그래프 그리기
plt.figure(figsize=(8, 4))
# ReLU 함수
plt.subplot(1, 2, 1)
plt.plot(x, y, label='ReLU(x)')
plt.title('ReLU 함수')
plt.xlabel('x')
plt.ylabel('ReLU(x)')
plt.grid(True)
plt.legend()
# ReLU 기울기
plt.subplot(1, 2, 2)
plt.plot(x, dy, label='ReLU\'(x)', color='orange')
plt.title('ReLU 기울기')
plt.xlabel('x')
plt.ylabel('Gradient')
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()핵심 포인트
x < 0구간에서는 출력이 0이며, 기울기도 0입니다.x > 0구간에서는 출력이 입력과 동일하고, 기울기는 1입니다.
3. 다층 신경망에 적용해 보기
다음 예제는 간단한 2‑layer MLP에 ReLU와 시그모이드 활성화 함수를 각각 적용했을 때의 출력 차이를 비교합니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
# 입력 데이터 (배치 5, 특성 3)
x = torch.randn(5, 3)
# Linear 레이어
linear = nn.Linear(3, 4)
# ReLU 적용
out_relu = F.relu(linear(x))
# 시그모이드 적용
out_sigmoid = torch.sigmoid(linear(x))
print("ReLU 출력:\n", out_relu)
print("\n시그모이드 출력:\n", out_sigmoid)결과 해석
- ReLU: 음수 입력은 0으로 차단되고, 양수 입력은 그대로 전달됩니다. 따라서 출력이 **희소(sparse)**해지는 경향이 있습니다.
- 시그모이드: 모든 입력이 (0, 1) 구간으로 압축되므로, 출력값이 전체적으로 작아지고 기울기 소실이 발생할 가능성이 높습니다.
4. Leaky ReLU와 Parametric ReLU
ReLU의 “죽은 뉴런” 문제를 완화하기 위해 Leaky ReLU와 **Parametric ReLU (PReLU)**가 제안되었습니다.
# Leaky ReLU (α = 0.01)
leaky = F.leaky_relu(linear(x), negative_slope=0.01)
# PReLU (학습 가능한 α)
prelu = nn.PReLU()
out_prelu = prelu(linear(x))
print("Leaky ReLU 출력:\n", leaky)
print("\nPReLU 출력:\n", out_prelu)- Leaky ReLU:
x < 0구간에서도 작은 기울기(보통 0.01)를 유지합니다. - PReLU: 음수 구간의 기울기
α를 학습 과정에서 자동으로 최적화합니다.
5. 실전 팁
| 상황 | 권장 활성화 함수 |
|---|---|
| 일반적인 CNN / MLP | ReLU |
| 음수 입력도 어느 정도 활용하고 싶을 때 | Leaky ReLU / PReLU |
| 출력이 0~1 사이에 있어야 하는 경우 (예: 확률) | 시그모이드 |
| 양쪽 모두 0을 중심으로 대칭이 필요할 때 | tanh |
- 초기화: ReLU 계열 함수를 사용할 때는 He 초기화(
nn.init.kaiming_normal_)를 적용하면 학습이 더 안정적입니다. - 배치 정규화:
BatchNorm과 함께 사용하면 죽은 뉴런 현상을 크게 감소시킬 수 있습니다.
6. 마무리
ReLU는 단순함과 효율성 덕분에 현재 대부분의 딥러닝 모델에서 기본 선택이 되고 있습니다. 하지만 상황에 따라 Leaky ReLU, PReLU 등 변형을 적용해 보는 것이 모델 성능을 더욱 끌어올릴 수 있는 좋은 방법입니다.
요약
- ReLU는
max(0, x)형태의 비선형 함수이며, 양수 구간에서는 기울기가 1, 음수 구간에서는 0입니다.- 시각화와 간단한 코드 예제로 동작 원리를 쉽게 이해할 수 있습니다.
- 변형 함수(Leaky ReLU, PReLU)를 활용하면 “죽은 뉴런” 문제를 완화할 수 있습니다.
이 글이 ReLU와 그 변형들을 이해하는 데 도움이 되었길 바랍니다! 🎉
ReLU 활성화 함수 사용
이전 기사들에서는 역전파와 그래프를 이용해 값을 정확히 예측했습니다. 모든 예제는 Softplus 활성화 함수를 사용했습니다.
이제 가장 널리 쓰이는 선택 중 하나인 ReLU (Rectified Linear Unit) 활성화 함수로 전환해 보겠습니다. 이는 딥러닝 및 합성곱 신경망에서 특히 인기가 높습니다.
정의
[ \text{ReLU}(x)=\max(0,;x) ]
출력 범위는 **0부터 ∞**까지입니다.
가정된 파라미터 값
w1 = 1.70 b1 = -0.85
w2 = 12.6 b2 = 0.00
w3 = -40.8 b3 = -16
w4 = 2.70우리는 0에서 1까지의 복용량 값을 사용할 것입니다.
Step 1 – First Linear Transformation ((w_1, b_1)) + ReLU
| 투여량 | 선형 항 (w_1·x + b_1) | ReLU 출력 |
|---|---|---|
| 0.0 | (0·1.70 + (-0.85) = -0.85) | 0 |
| 0.2 | (0.2·1.70 + (-0.85) = -0.51) | 0 |
| 0.6 | (0.6·1.70 + (-0.85) = 0.17) | 0.17 |
| 1.0 | (1·1.70 + (-0.85) = 0.85) | 0.85 |
투여량이 증가함에 따라, 선형 항이 양수가 될 때까지 ReLU 출력은 0을 유지하고, 그 이후에는 직선 형태로 따라갑니다 – “굽은 파란 선”이라고 부를 수 있습니다.
Demo code
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 1, 100)
w1, b1 = 1.70, -0.85
z1 = w1 * x + b1
relu1 = np.maximum(0, z1)
plt.plot(x, relu1, label="ReLU(w1·x + b1)")
plt.xlabel("Dosage")
plt.ylabel("Activation")
plt.title("ReLU Activation")
plt.legend()
plt.show()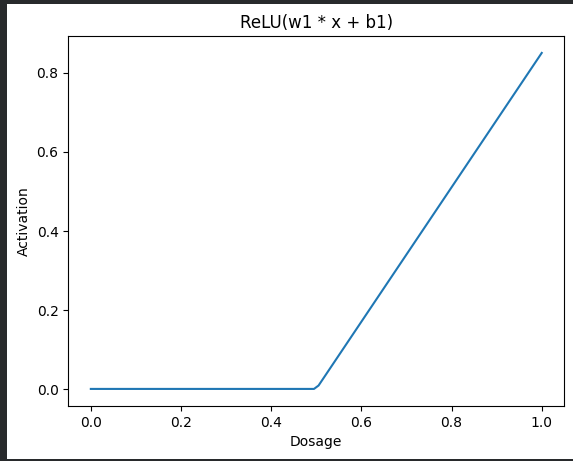
Step 2 – ReLU 출력에 (w_3 = -40.8) 곱하기
굽은 파란 선에 ‑40.8을 곱하면 선이 아래쪽으로 뒤집히고 크기가 조정됩니다.
데모 코드
w3 = -40.8
scaled_blue = relu1 * w3
plt.plot(x, scaled_blue, label="ReLU × w3")
plt.xlabel("Dosage")
plt.ylabel("Value")
plt.title("ReLU Output × w3")
plt.legend()
plt.show()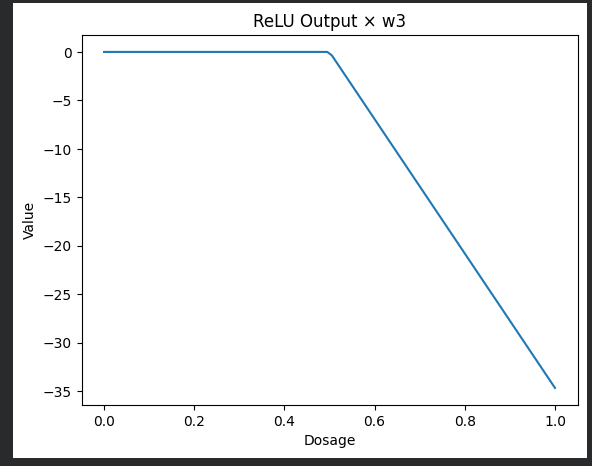
단계 3 – 하단 노드 ((w_2, b_2))
(b_2 = 0)이므로, 변환식 (w_2·x + b_2)는 직선 형태의 주황색 선을 생성합니다.
데모 코드
w2, b2 = 12.6, 0.0
z2 = w2 * x + b2
plt.plot(x, z2, color="orange", label="w2·x + b2")
plt.xlabel("Dosage")
plt.ylabel("Value")
plt.title("Bottom Node")
plt.legend()
plt.show()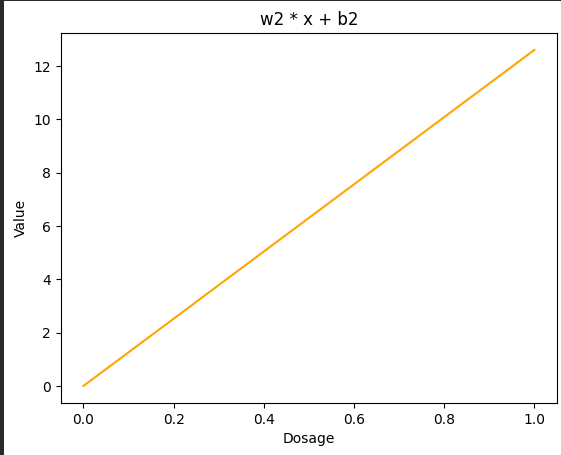
4단계 – 하단 노드를 (w_4 = 2.70) 로 곱하기
데모 코드
w4 = 2.70
scaled_orange = z2 * w4
plt.plot(x, scaled_orange, color="orange", label="(w2·x + b2) × w4")
plt.xlabel("Dosage")
plt.ylabel("Value")
plt.title("Scaled Bottom Node")
plt.legend()
plt.show()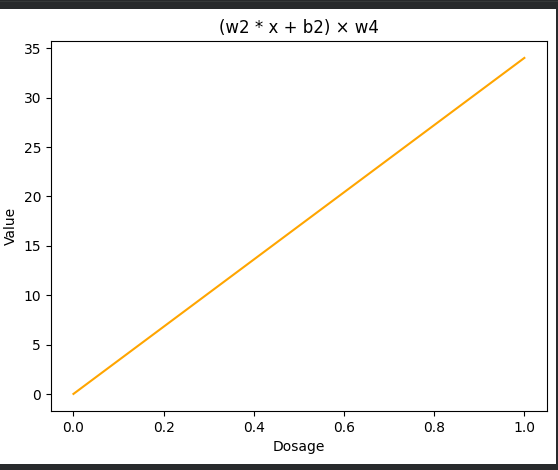
Step 5 – 두 경로를 합치기
구부러진 파란 선과 직선인 주황 선을 합하면 녹색 쐐기 모양 곡선이 생성됩니다.
Demo code
combined = scaled_blue + scaled_orange
plt.plot(x, combined, color="green", label="Combined Signal")
plt.xlabel("Dosage")
plt.ylabel("Value")
plt.title("Combined Signal")
plt.legend()
plt.show()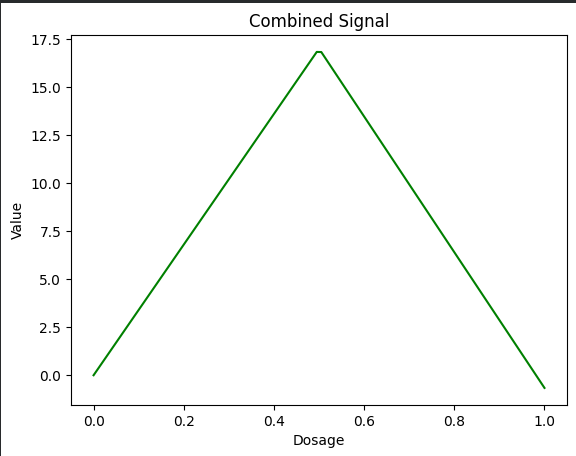
Step 6 – Add Bias (b_3 = -16)
마지막으로, 바이어스 항을 사용해 결합된 신호를 아래쪽으로 이동시킵니다.
데모 코드
b3 = -16
combined_bias = combined + b3
plt.plot(x, combined_bias, color="green", label="Combined + b3")
plt.xlabel("Dosage")
plt.ylabel("Value")
plt.title("Combined Signal + Bias")
plt.legend()
plt.show()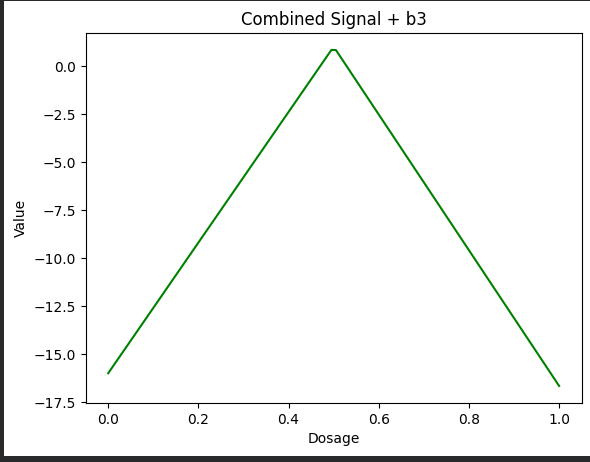
요약
Softplus를 ReLU로 교체하고 선형‑변환‑스케일‑추가 단계를 따라가면, 각 단계에서 시각화할 수 있는 구간별 선형 모델을 얻을 수 있습니다. 위의 코드 스니펫은 그대로 실행하여 모든 플롯을 재현할 수 있습니다.
Source:
Step 7 – Apply ReLU Again
이제 초록색 쐐기 위에 ReLU를 적용합니다. 이는 모든 음수 값을 0으로 변환하고 양수 값은 그대로 유지합니다.
Demo code
final_output = np.maximum(0, combined_bias)
plt.plot(x, final_output, color="green")
plt.xlabel("Dosage")
plt.ylabel("Activation")
plt.title("Final ReLU Output")
plt.show()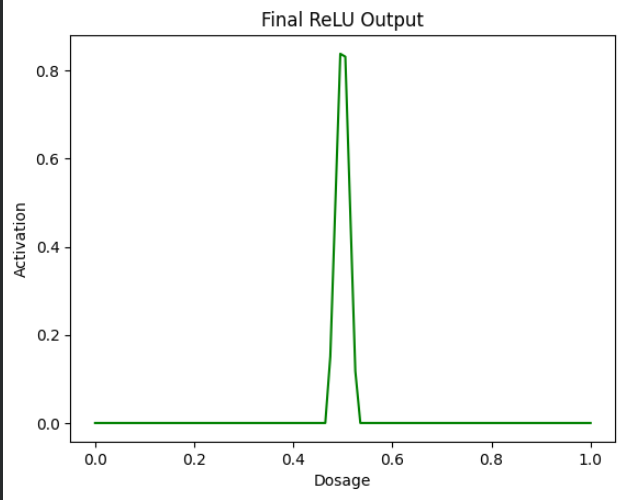
이것이 최종 결과이며, ReLU를 사용해 곡선을 그려 실제 상황에 더 현실감 있게 만들었습니다.
다음 글들에서는 신경망에 대해 더 자세히 살펴볼 예정입니다.
Colab 노트북에서 예제를 직접 실행해 볼 수 있습니다.
도구, 라이브러리 또는 전체 리포지토리를 더 쉽게 설치하는 방법을 찾고 계신가요?
Installerpedia를 사용해 보세요 – 커뮤니티 기반의 구조화된 설치 플랫폼으로, 최소한의 번거로움과 명확하고 신뢰할 수 있는 가이드를 통해 거의 모든 것을 설치할 수 있습니다.
ipm install repo-name
🔗 Installerpedia 여기서 확인하세요: https://hexmos.com/freedevtools/installerpedia/