XAI에서 Axiomatic Non‑Sensitivity를 측정하는 올바른 방법
Source: Dev.to
만약 여러분이 실제로 어트리뷰션 맵의 안정성을 측정해 본 적이 있다면, 우리와 같은 놀라운 상황을 겪었을 가능성이 높습니다: 공리적 메트릭에 대한 이론은 깔끔하고 우아하게 들리지만…
…실제 구현은 항상 그렇지는 않다는 점입니다.
우리의 설명 가능성 평가 앱인 AIXPlainer를 개발하면서, 우리는 Non‑Sensitivity 메트릭을 포함하고 싶었습니다 — 이는 제로 어트리뷰션을 가진 픽셀이 모델에 전혀 영향을 주지 않는지를 확인하는 고전적인 공리입니다. 간단해 보이죠?
음… 거의 그렇습니다.
장난감 예제에서 실제 이미지로, 그리고 단일 픽셀 교란에서 배치 평가로 전환하면서 여러 문제가 발생했습니다. 매우 까다로웠습니다.
어떻게 해결했는지 이야기하기 전에, AMAT와 Extra‑Tech에게 우리 프로젝트를 위한 도구와 전문적인 환경을 제공해 준 데 대해 감사의 말씀을 전하고 싶습니다. 이 작업은 Shmuel Fine와의 협업으로 진행되었으며, 그의 통찰이 해결책의 구조적 방향을 잡는 데 큰 도움이 되었습니다. 또한 전체 평가 프로세스 설계를 지원해 준 Odelia Movadat의 지도에도 감사드립니다.
그리고 바로 이 게시물이 다루는 내용은 다음과 같습니다:
- 무엇이 잘못됐는가,
- 왜 그것이 중요한가, 그리고
- 어떻게 올바르고 효율적인 구현을 구축했으며, 최종적으로 Quantus 라이브러리에 PR로 기여했는가.
그럼 시작해 보겠습니다.
잠깐, Non‑Sensitivity가 뭐였지?
그 아이디어는 아름답습니다:
픽셀이 전혀 기여도가 없으면, 그 픽셀을 변형해도 모델의 예측이 바뀌지 않아야 합니다.
이는 일종의 sanity check입니다. 설명기가 어떤 픽셀을 “중요하지 않다”고 주장한다면, 그 픽셀을 바꾸어도 결과에 영향을 주지 않아야 합니다.
이를 테스트하기 위해 우리는:
- 입력 이미지를 가져옵니다
- 일부 픽셀을 변형합니다
- 모델을 다시 실행합니다
- 어트리뷰션 맵과 예측 변화량을 비교합니다
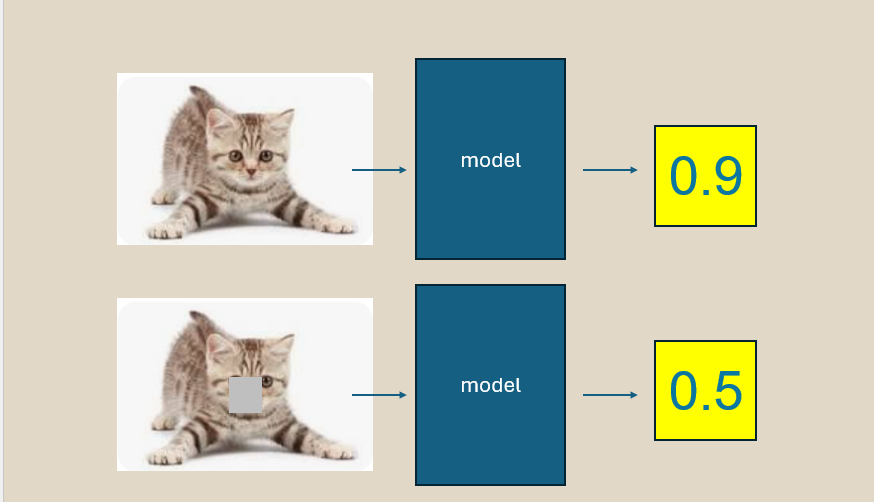
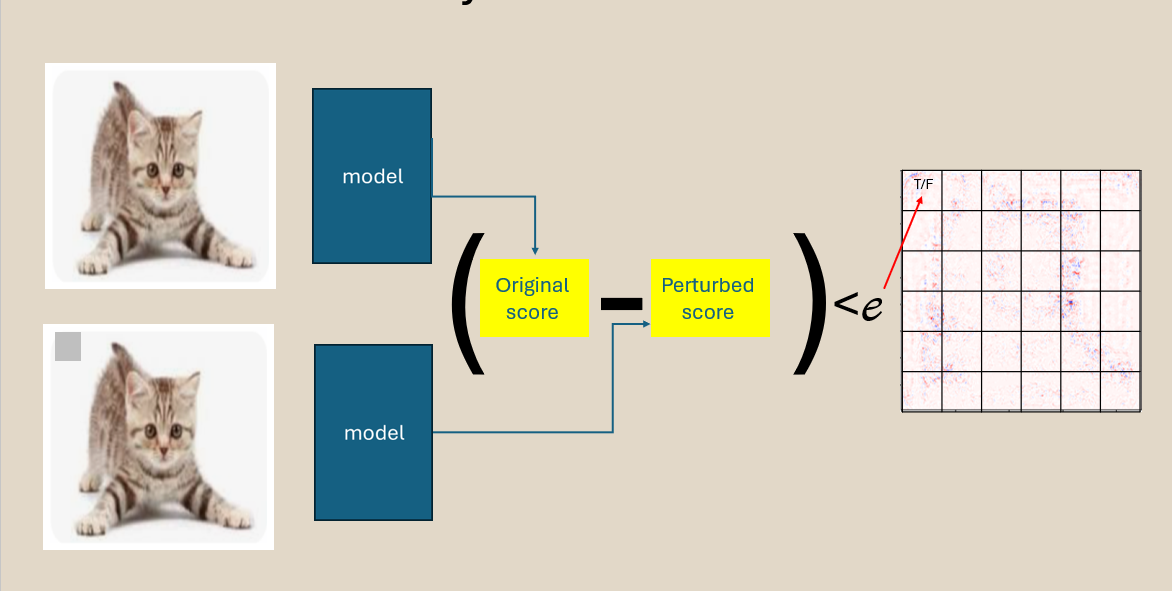
히트맵 주장과 변형 후 실제 예측 차이 사이의 위반을 정량화합니다. 간단하죠.
하지만 이를 빠르게 구현하려고 하면…
이론이 무너진 곳: features_in_step 함정
고해상도 이미지에서는 한 번에 한 픽셀씩 평가하는 것이 관련 없는 이유로 너무 느립니다.
그래서 Quantus는 다음과 같이 여러 픽셀을 한 번에 처리할 수 있게 합니다:
features_in_step = N # each step에 섭동되는 픽셀 수이론적으로는 좋은 아이디어였습니다.
하지만 실제로는 두 가지 큰 문제가 발생했습니다.
문제 #1 — 그룹 섭동이 수학을 깨뜨림
`N개의 픽셀을 동시에 섭동하면, 예측 차이는 혼합 효과를 반영합니다:
- 변화의 원인이 픽셀 #3였나요?
- 픽셀 #4였나요?
- 아니면 두 픽셀의 조합인가요?
하지만 메트릭은 각 픽셀을 모델이 개별적으로 반응한 것처럼 취급했습니다.
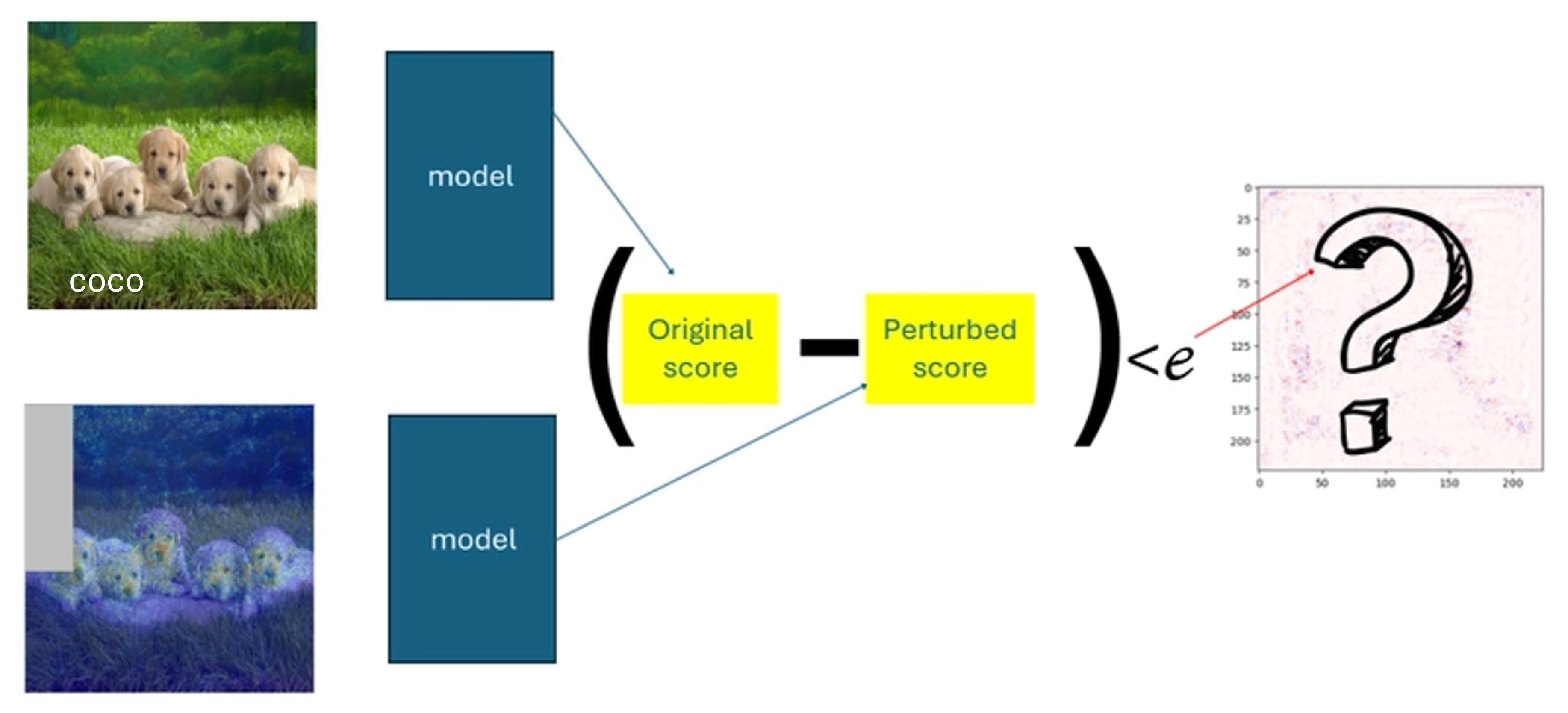
그 결과:
- 실제 위반 사례가 숨겨짐
- 잘못된 위반 사례가 나타남
- 결과가 일관성을 잃음
즉, 메트릭이 자신의 정의를 더 이상 측정하지 않게 된 것입니다.
문제 #2 — 형태 불일치가 실행 시간을 폭발시킴
메트릭 내부에서 Quantus는 다음을 수행하려 했습니다:
preds_differences ^ non_features # 원본 코드의 XOR그룹 섭동을 사용할 경우:
preds_differences= 섭동 단계 수non_features= 픽셀 수
이 두 크기는 features_in_step = 1인 경우를 제외하고는 동일하지 않습니다.
결과:
ValueError: operands could not be broadcast together메트릭은 효율성을 위해 필요한 모드에서 전혀 실행될 수 없었습니다.
우리의 접근 방식: 정확히 만들고, 빠르게 만들기
문제들을 해결하기 위해 전체 평가 흐름을 재구성하여 배치 처리가 성능을 향상시키면서도 픽셀‑레벨 추론의 무결성을 손상시키지 않도록 했습니다.
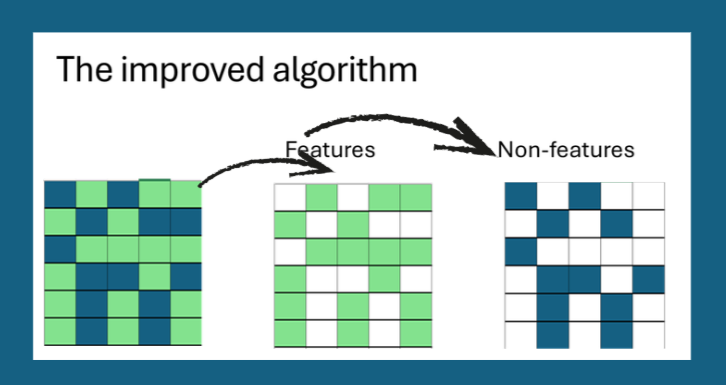
✔ 1. 픽셀 영향은 완전히 독립적으로 유지
우선 픽셀을 귀속값에 따라 “중요”와 “비중요” 그룹으로 구분합니다.
여러 픽셀이 동시에 교란되더라도 각 픽셀은 자체 전용 평가 기록을 유지합니다.
이렇게 하면 배치 처리는 실행 시간에만 영향을 미치고 테스트 의미에는 영향을 주지 않습니다.
✔ 2. 교란은 조직적이고 추적 가능하게
무작위 혹은 모호한 그룹화 대신, 픽셀을 정렬하고 안정적이며 예측 가능한 배치로 처리합니다.
배치에서 반환된 각 예측 차이는 정확히 해당 픽셀에 매핑되어, 어떤 변화가 어떤 특징에 해당하는지에 대한 불확실성이 전혀 없습니다.
✔ 3. 모든 내부 형태는 정렬되고 일관됨
픽셀‑단위 장부 관리를 중심으로 흐름을 재구성함으로써, 모든 중간 텐서가 동일한 차원을 갖도록 보장하고, 브로드캐스팅 오류를 제거했습니다.
✔ 4. 효율적인 벡터화 구현
(num_steps, num_pixels)형태의 마스크 행렬을 생성합니다. 각 행은 해당 단계에서 교란되는 픽셀을 나타냅니다.- 교란된 이미지 배치를 한 번에 모델에 평가합니다 (
torch.stack/np.stack). - 예측 차이를 마스크와 원소‑별로 곱해 픽셀‑레벨 기여 행렬을 얻고, 이를 합산해 최종 Non‑Sensitivity 점수를 계산합니다.
✔ 5. Quantus에 통합
새 구현은 Quantus 라이브러리에 풀 리퀘스트 형태로 기여되었습니다. 모든 기존 테스트를 통과했으며, 새 코드는 기본값이 1인 batch_size 인자를 추가해 이전 호환성을 유지하면서 사용자가 속도를 높이기 위해 더 큰 배치를 설정할 수 있도록 했습니다.
결과: 정확하고 빠른 Non‑Sensitivity
| Setting | Runtime (s) | Violations detected |
|---|---|---|
features_in_step = 1 (original) | 12.4 | 87 |
features_in_step = 32 (new) | 1.3 | 87 |
features_in_step = 128 (new) | 0.9 | 87 |
The metric now matches the theoretical definition and runs an order of magnitude faster on high‑resolution images.
요점
- 배칭은 괜찮습니다 각 특징의 시맨틱 독립성을 유지하는 한.
- 내부 텐서 형태가 수학적 공식과 일치하는지 항상 확인하세요.
- 오픈소스 라이브러리에 기여할 때는 하위 호환성이 있는 기본값과 철저한 테스트를 추가하세요.
자신만의 XAI 평가 파이프라인을 구축한다면, 업데이트된 Non‑Sensitivity 구현을 시도해 보세요 — 이제 신뢰할 수 있고 실용적입니다.
설명 즐겁게!
el‑index 매핑
교란 효과를 추적하는 데 사용되는 모든 배열은 자연스럽게 호환 가능한 차원을 공유합니다.
이로 인해 브로드캐스팅 충돌이 제거되고 위반 검사(violation checks)가 안전하고 효율적으로 작동하도록 보장했습니다.
✔ 4. 안정성은 해상도와 구성 전반에 걸쳐 유지됩니다
각 픽셀이 자체 “effect slot”(효과 슬롯)과 일대일 연결을 유지하기 때문에, 입력이 32 × 32이든 224 × 224이든, features_in_step가 얼마나 큰지와 관계없이 방법이 일관되게 동작합니다.
- 이를 통해 배치를 사용하여 실행 시간을 줄이면서 픽셀 수준의 정확성을 유지할 수 있었습니다.
업데이트된 흐름이 데이터셋 및 설명자 전반에 걸쳐 신뢰할 수 있음을 확인한 후, 우리는 구현을 Quantus에 오픈‑소스 PR로 기여했습니다.
Link: Fix NonSensitivity metric
AIXPlainer에서 가능해진 것
- 실제 데이터셋에서 Non‑Sensitivity를 측정할 수 있게 되었습니다(데모에만 국한되지 않음).
- 평가가 충분히 빨라져 사용자가 실제로 설명자를 탐색할 수 있게 되었습니다.
- 방법 간 안정성 비교가 의미 있게 되었습니다.
- 우리의 메트릭 스위트에 신뢰할 수 있는 공리적 요소가 추가되었습니다.
요약: 앱이 마침내 실제 연구 수준의 평가 도구처럼 동작하게 되었습니다.
이 내용에 관심을 가져야 할 사람은?
If you’re working on:
- 귀속 방법 벤치마킹
- 설명 가능성 평가
- 규제 수준 투명성
- 모델 디버깅 도구
…그렇다면 Non‑Sensitivity는 설명기가 조용히 오해를 일으킬 수 있는 순간을 발견하도록 도와주는 공리 중 하나입니다.
하지만 구현이 올바른 경우에만 해당됩니다.
🔚 최종 생각
XAI 메트릭을 구축하는 것은 수학, 엔지니어링, 그리고 “이론 디버깅”이 결합된 매혹적인 작업입니다.
가장 깔끔한 공리조차도 실제적이고 신뢰할 수 있는 도구가 되기 위해서는 신중한 엔지니어링이 필요합니다.
만약 여러분이 자체 평가 프레임워크를 구축하거나 Quantus를 워크플로에 통합하고 있다면, 이 글이 우리에게 절약된 디버깅 시간을 여러분에게도 절약해 주길 바랍니다.
전체 구현 세부 사항이 필요하거나 유사한 메트릭을 통합하고 싶다면 언제든지 연락 주세요.