프라이빗 데이터를 사용해 질문에 답변하는 AI Chatbot 구축 (RAG Overview)
발행: (2026년 1월 16일 오전 11:55 GMT+9)
5 분 소요
원문: Dev.to
Source: Dev.to
Introduction
대부분의 AI 챗봇은 잘 작동합니다—하지만 구체적인 질문을 하면 문제가 생깁니다.
대형 언어 모델은 여러분의 사적 문서나 내부 지식에 접근할 수 없습니다. 컨텍스트가 부족하면 추측으로 빈칸을 메우게 되며, 이로 인해 환각(hallucination)과 신뢰할 수 없는 답변이 나오게 됩니다.
이 글에서는 Retrieval‑Augmented Generation (RAG)을 적용해 사적 데이터를 활용해 질문에 답하는 AI 챗봇을 만드는 과정을 살펴보고, 왜 이 접근 방식이 프롬프트‑만 사용한 챗봇보다 더 신뢰할 수 있는지 설명합니다.
Why Prompt‑Only Chatbots Break Down
- 그대로 사용되는 LLMs:
- 여러분의 내부 또는 사적 데이터를 알지 못함
- 최신 정보를 접근할 수 없음
- 불확실할 때도 답변을 생성함
이는 다음과 같은 경우에 큰 문제로 작용합니다:
- 내부 도구
- 문서 어시스턴트
- 고객 지원 봇
- 지식 기반 애플리케이션
프롬프트 엔지니어링만으로는 해결되지 않습니다. 모델은 여전히 필요한 컨텍스트가 부족하기 때문입니다.
What Retrieval‑Augmented Generation (RAG) Actually Does
Retrieval‑Augmented Generation (RAG) 은 챗봇이 질문에 답하는 방식을 바꿉니다.
- 데이터 소스에서 관련 정보를 검색함
- 그 정보를 프롬프트에 삽입함
- 검색된 컨텍스트에 근거해 응답을 생성함
쉽게 생각해 보면:
- 프롬프트‑만 사용하는 챗봇은 폐쇄형 시험을 보는 것과 같습니다.
- RAG 시스템은 개방형 시험을 보는 것과 같습니다.
그 결과 더 정확하고 일관된 응답을 얻을 수 있습니다.
High‑Level Architecture
전형적인 RAG 챗봇은 다음 요소들로 구성됩니다:
- 사용자 질의
- 검색 레이어(검색 또는 벡터 유사도)
- 관련 문서 청크
- 최종 답변을 생성하는 LLM
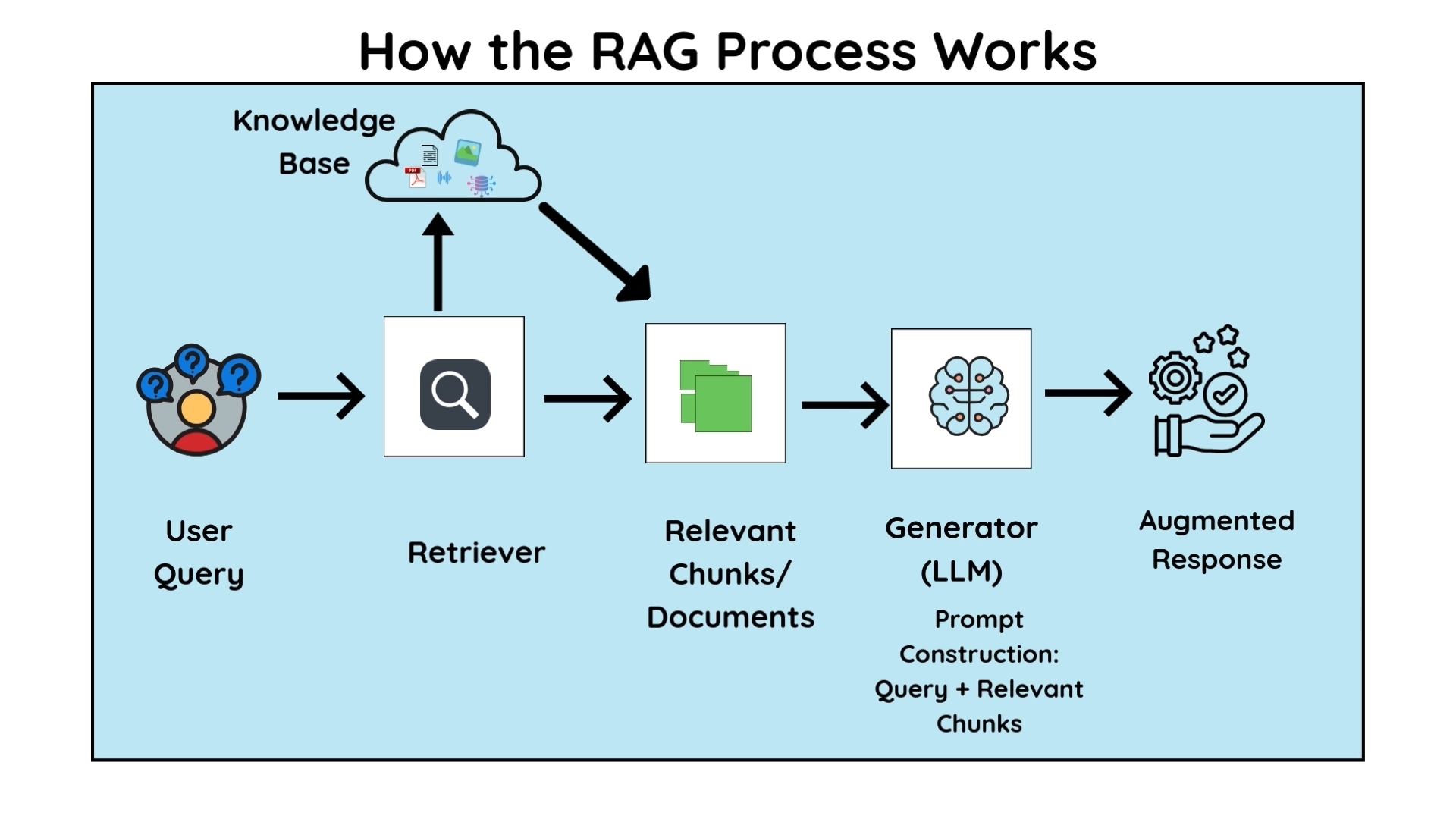
이 분리가 중요한 이유
- 검색은 정확성을 담당
- 언어 모델은 자연어 생성을 담당
When RAG Is the Right Approach
RAG가 적합한 경우:
- 데이터가 사적이거나 내부에 존재할 때
- 정확성이 창의성보다 중요할 때
- 지식 베이스가 시간이 지나면서 변할 때
주요 활용 사례:
- 내부 문서 어시스턴트
- 고객 지원 챗봇
- 지식 베이스 검색 도구
- 개인 문서 Q&A 시스템
Common RAG Mistakes
- 부적절한 문서 청크 나누기
- 약한 검색 설정
- 프롬프트에 너무 많은 컨텍스트를 전달하기
- 더 큰 모델이 검색 문제를 해결할 것이라고 가정하기
실제로는 검색 품질이 모델 선택보다 더 큰 영향을 미칩니다.
Full Walkthrough and Demo
전체 설정(데이터 검색 및 응답 생성 포함)은 아래 동영상에서 시연됩니다.
AI 챗봇이 신뢰할 수 없는 답변을 만든다면, 대부분의 경우 문제는 모델이 아니라 컨텍스트 부족입니다. 응답을 생성하기 전에 올바른 데이터를 검색하는 것이 RAG 기반 시스템을 신뢰할 수 있게 만드는 핵심입니다.