Understanding Attention Mechanisms – Part 6: Final Step in Decoding
Source: Dev.to
Final Step in Decoding
In the previous article, we obtained the initial output, but we didn’t receive the EOS token yet.
To get that, we need to unroll the embedding layer and the LSTMs in the decoder, and then feed the translated word “vamos” into the decoder’s unrolled embedding layer. After that, we follow the same process as before, but this time we use the encoded values for “vamos”.
The second output from the decoder is EOS, which means we are done decoding.
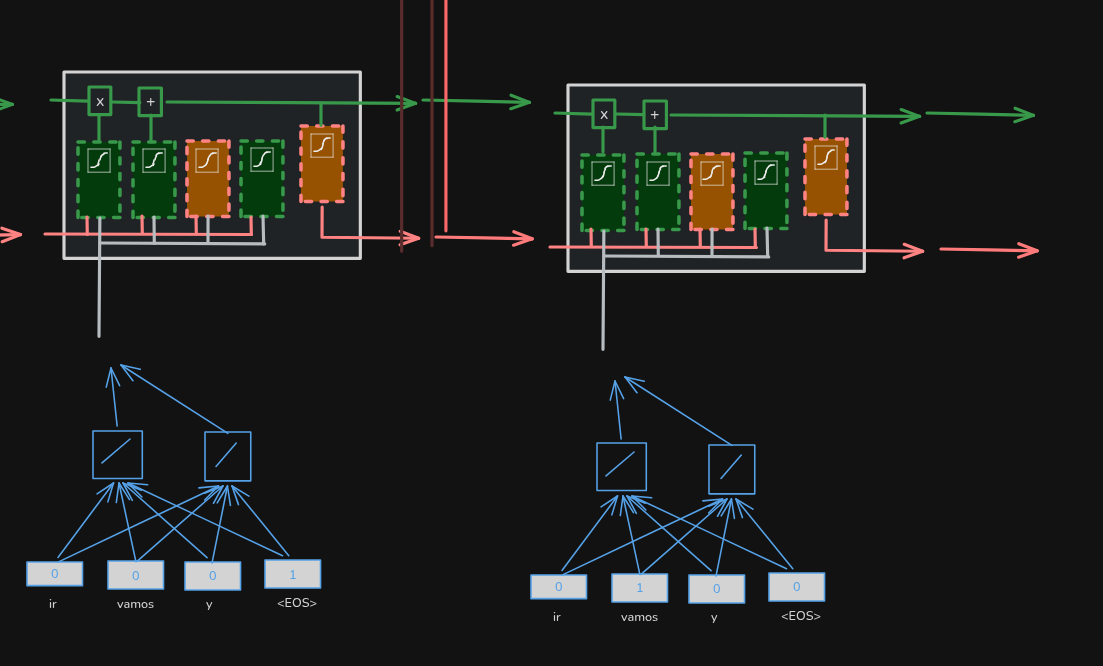
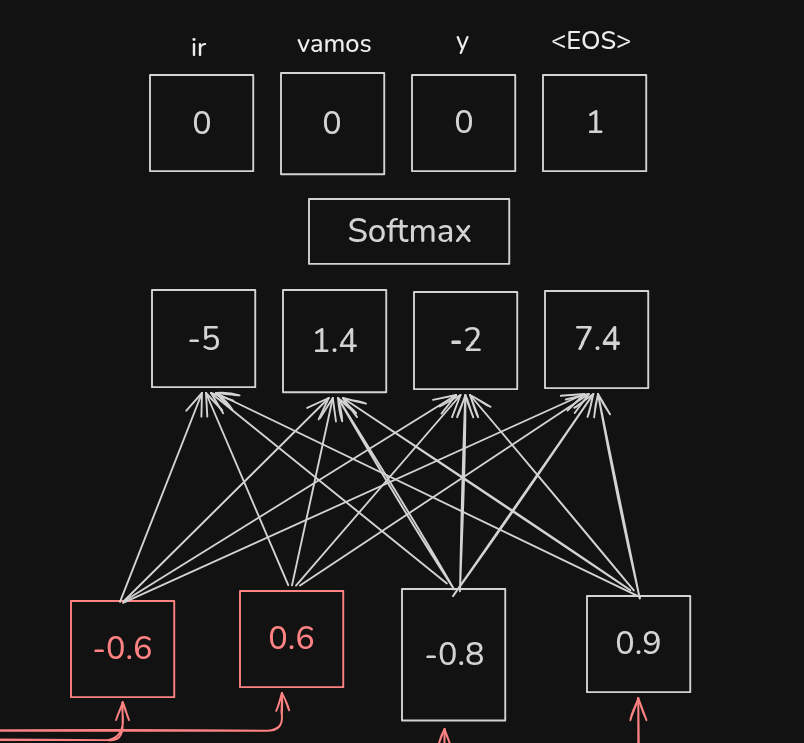
When we add attention to an encoder‑decoder model, the encoder mostly stays the same. However, during each step of decoding, the model has access to the individual encodings for each input word. We use similarity scores and the softmax function to determine what percentage of each encoded input word should be used to predict the next output word.
Now that we have added attention to the model, we won’t strictly need LSTMs in the same way. We’ll explore this further when we move on to transformers.
Installerpedia (optional tool)
Looking for an easier way to install tools, libraries, or entire repositories? Try Installerpedia, a community‑driven, structured installation platform that lets you install almost anything with minimal hassle and clear, reliable guidance.
ipm install repo-name