I Built A Monster Model Before I Built a Working One
Source: Dev.to
I spent 10 days building my first competition ML model
It had transformers, attention pooling, multiple input branches.
It scored 0.500.
The Competition
With about two weeks of summer left, I decided to jump into my first ML competition. I had always browsed Kaggle competitions and found them fascinating—if not a tiny bit intimidating. I kept waiting for the perfect opportunity: something easy, but not boring.
At some point I realized there’s no point waiting. If I was going to fail, I might as well fail early.
So I took the plunge.
I started working on a competition called BIRDCLEF+ 2026, where the goal was to build a model that understands which specific animal/bird sounds are present in an audio clip and predicts the probability of each one being present. I wasn’t going to code everything myself; I decided to use some AI assistance for the coding and to understand the overall workflow of finishing a model end‑to‑end while getting comfortable with the code.
The Plan
This was the first real‑world ML problem I tackled.
The hard part wasn’t building the model itself; it was everything around it—strenuous data preprocessing, debugging environment mismatches, spotting issues amidst tons of code, limited GPU availability, and trusting the process.
I didn’t realize this at the start. I naively thought the key part was a revolutionary model—something that turned heads, something impressive.
- Multiple input branches
- Transformers
- CNNs
- Attention pooling
If it sounded advanced, I wanted it in. I thought this would be my edge. I soon realized that learning about complex neural‑network architectures and actually implementing them are two completely different things.
Here’s the first model I tried to build:
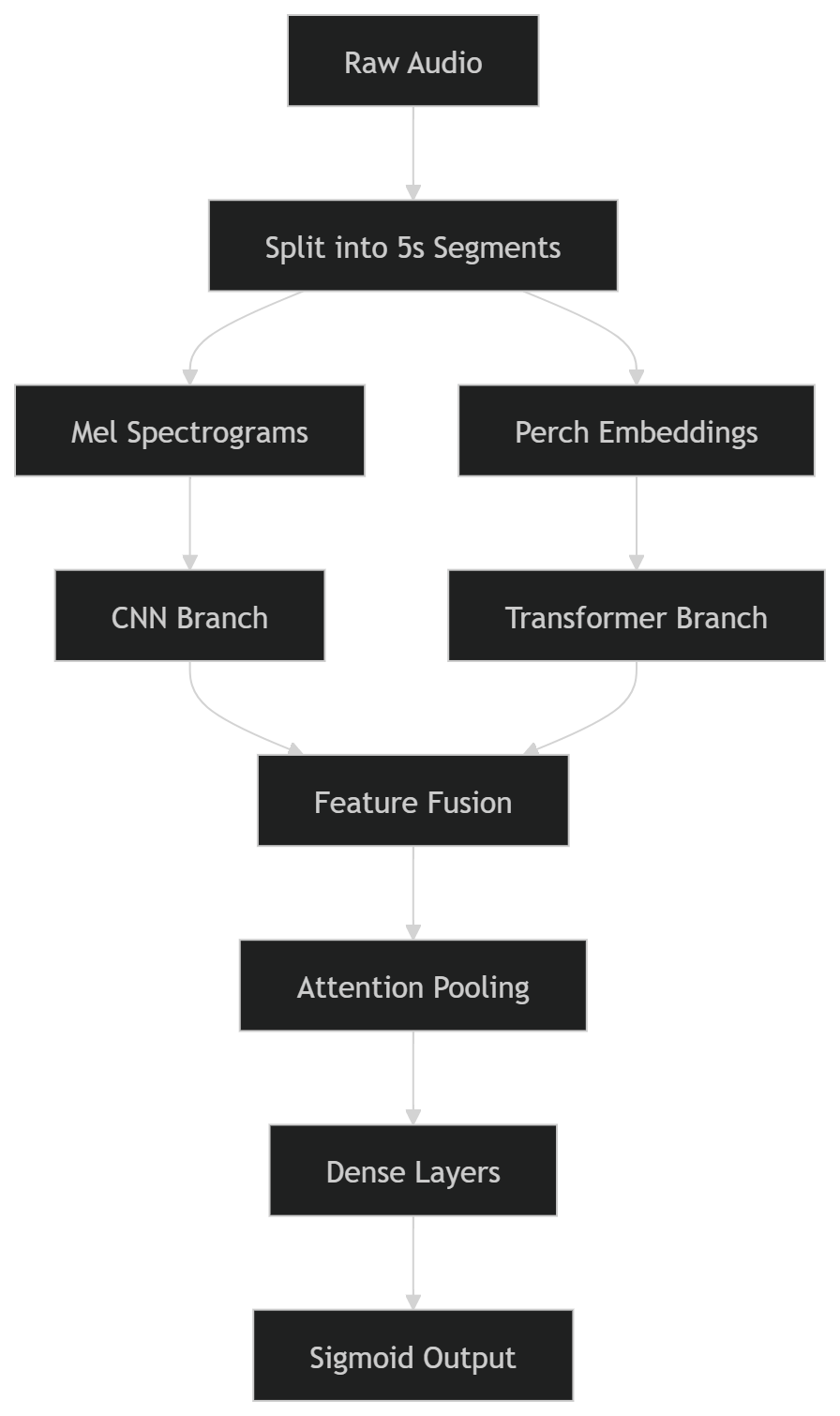
For this, I had to split two training datasets into 5‑second segments, generate Mel spectrograms and Perch embeddings, and correctly align them with their primary and secondary labels.
This turned out to be far more complicated than I expected. I ran into multiple issues—XLA incompatibility with my PyTorch environment, Kaggle cache limits filling up quickly, and several other small but frustrating bugs. What I thought would take a day or two ended up taking an entire week. Slowly, I worked through each problem and got the pipeline running.
Once that was done, setting up the model itself was relatively straightforward. I loaded the preprocessed data and started training. The main issue here was running out of CPU RAM, since data loading happened on the CPU while the GPU handled training. Each session would run for about 1.5–2 hours before crashing, so I implemented checkpointing to save progress every 50 batches.
In total I ran the notebook for around 12–15 hours across multiple sessions and managed to complete just over one epoch of training.
The 0.500 Moment
Then I set up the inference notebook and submitted it to the competition. I finally understood how the submission process works. After just two tries it ran successfully.
I scrolled down to see my score.
0.500

After 10+ days of work, that number hit harder than I expected.
And then I realized—I had trapped myself in complexity. Somewhere across my 1 000+ lines of code there was a bug, and I had no way of finding it.
What I Should Have Done
I should have started with simplicity: one model, one pipeline, one thing I could actually debug. Something like this:
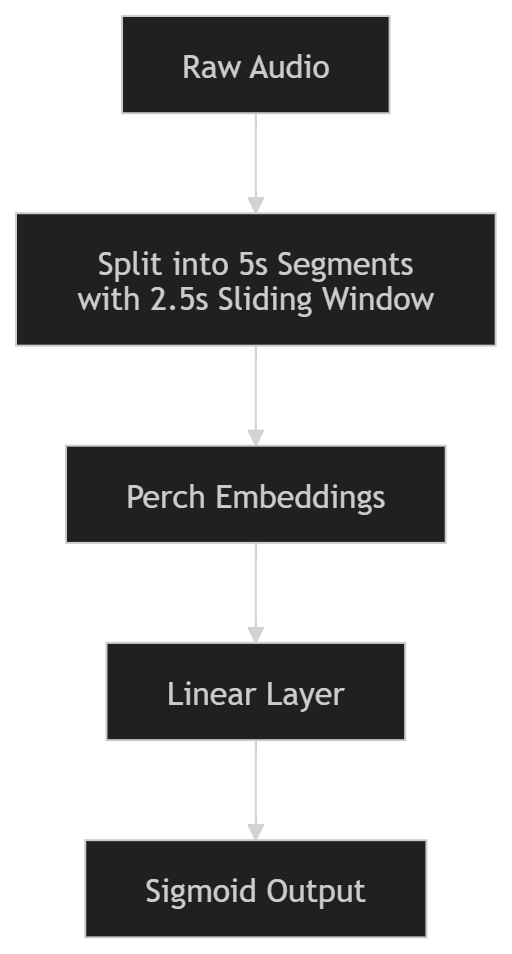
The key to improvement isn’t a whole model revamp, but rather simple changes that give a high ROI.
When splitting the dataset into 5‑second chunks, instead of using non‑overlapping windows (0–5 s, 5–10 s, …) I could have used a 2.5 s sliding window: 0–5 s, 2.5–7.5 s, …
This alone would have hugely increased the volume of the dataset. I could have gotten this to work in < 3–4 days. After that, the inherent nature of the preprocessing would make it easy to add attention‑pooling layers later on without breaking anything.
Lessons
Even though the result wasn’t great, I learned a lot from this attempt. I now understand the entire competition pipeline and feel more confident handling environment issues, timeouts, and GPU limits.
One thing I missed: I only had two weeks, so I didn’t participate in the competition discussions or try teaming. There is a lot to learn from the community—spotting patterns of issues that others have already faced can save you a lot of time.
Conclusion
My first Kaggle competition was an enriching experience, and there was a lot to learn from my failure.
Complexity is not a starting point.
Debug.
Gable code beats sophisticated code.
Iteration speed matters.
Complex models aren’t bad.
But you don’t start with a monster.
You grow into one.
If you’ve ever overengineered something like this, I’d love to hear your experience!