🍵 Linear Regression for Absolute Beginners With Tea — A Zero‑Knowledge Analogy
Source: Dev.to
Machine Learning can feel intimidating — gradients, cost functions, regularization, over‑fitting… it sounds like a foreign language.
So let’s forget the jargon.
Imagine you run a tea stall. Every day you record:
- Temperature
- Cups of tea sold
Your goal? 👉 Predict tomorrow’s tea sales.
This single goal will teach you everything about:
- Linear Regression
- Cost Function
- Gradient Descent
- Over‑fitting
- Regularization
- Regularized Cost Function
Let’s begin.
⭐ Scenario 1: What Is Linear Regression?
Predicting Tea Sales From Temperature
You notice:
| Temperature (°C) | Tea Cups Sold |
|---|---|
| 10 | 100 |
| 15 | 80 |
| 25 | 40 |
There is a pattern: lower temperature → more tea.
Linear regression tries to draw a straight line that best represents this relationship:
[ \hat{y}=mx+c ]
- (x) = temperature
- (\hat{y}) = predicted tea sales
- (m) = slope (how much tea sales drop for each degree increase)
- (c) = baseline tea demand
That’s it — a simple line that predicts tomorrow’s tea sales.
⭐ Scenario 2: Cost Function
Measuring “How Wrong” Your Predictions Are
Today’s temperature: 20 °C
Your model predicted: 60 cups
Actual: 50 cups
Error = 10 cups
The cost function gives a score for your overall wrongness:
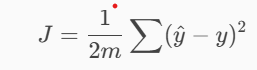
Why square?
Because being wrong by 30 cups is far worse than being wrong by 3 cups, and the model should learn that.
The lower the cost → the better the model.
⭐ Scenario 3: Gradient Descent
The Art of Improving Step by Step
Imagine you’re experimenting with a new tea recipe:
- Add more sugar → too sweet
- Add less → too bland
- Adjust slowly until perfect
This is gradient descent.
The model adjusts:
- slope ((m))
- intercept ((c))
step‑by‑step to reduce the cost function.
Think of the cost function as a hill. You are standing somewhere on it. Your goal is to walk down to the lowest point. That lowest point = best model.
⭐ Scenario 4: Over‑fitting
When Your Model Tries Too Hard and Learns “Noise”
Suppose you record too many details every day:
- Temperature
- Humidity
- Rain
- Wind
- Festival
- Cricket‑match score
- Traffic
- Your neighbour’s dog barking
- The colour of customers’ shirts
- How cloudy the sky looks
Your model tries to use everything, even things that don’t matter.
That leads to over‑fitting:
- Model performs great on training data
- But terrible on new data
It memorizes instead of understanding the general pattern.
⭐ Scenario 5: How Do We Fix Over‑fitting?
- ✔ Remove useless features – ignore “dog barking” and similar noise.
- ✔ Gather more data – more examples → clearer pattern.
- ✔ Apply Regularization – the most powerful fix.
⭐ Scenario 6: What Is Regularization?
Adding a Penalty to Stop the Model From Overthinking
In your tea stall, if the tea‑maker uses too many ingredients, the tea becomes:
- Confusing
- Strong
- Expensive
- Unpredictable
So you tell him:
“Use fewer ingredients. If you use too many, I will cut your bonus.”
That penalty forces him to make simple and consistent tea.
Regularization does the same with machine‑learning models. It says:
“If your model becomes too complex, I’ll increase your cost.”
This forces the model to keep only the important features.
⭐ Scenario 7: Regularized Linear Regression
(With detailed explanation)
Regularization modifies the normal cost function:
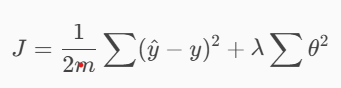
Where:
- (\theta) = model parameters (weights of each feature)
- (\lambda) = regularization strength (higher (\lambda) = stronger penalty)
🟦 What does this penalty do?
Imagine you track 10 features:
- Temperature
- Humidity
- Wind
- Rain
- Festival
- Day of week
- Road traffic
- Cricket‑match score
- Local noise level
- Dog‑barking frequency
Your model tries to make sense of all of these. Some weights become huge:
| Feature | Weight |
|---|---|
| Temperature | 1.2 |
| Festival | 2.8 |
| Traffic | 3.1 |
| Dog barking | 1.5 |
| Noise level | 2.4 |
Huge weights = the model thinks those features are extremely important, even if many are random noise.
Regularization adds a penalty to shrink these weights:
- Temperature → stays important
- Festival → slightly reduced
- Dog barking → shrinks toward 0
- Noise → shrinks toward 0
This makes your model simpler, more general, and more accurate.
⭐ Scenario 8: How Regularization Fixes Over‑fitting
(Deep real‑world scenario)
Before Regularization: Over‑thinking Model
Your model notices all random details:
One day it rained and India won a match and a festival was happening and it was cold and traffic was low… Tea sales were high that day.
So your model thinks:
- “Rain increases tea sales by 6 %”
- “Cricket‑match result increases sales by 8 %”
- “Dog barking decreases sales by 2 %”
- “Traffic increases sales by 4 %”
- …etc.
It’s memorizing coincidences – classic over‑fitting.
After Regularization:
The penalty forces the model to keep only the truly predictive features (e.g., temperature) and push the noisy ones (dog barking, cricket score, etc.) toward zero. The resulting model generalizes well to new days, giving more reliable sales forecasts.
Regularization: Mature Model
Regularization shrinks useless weights:
- Dog barking → 0
- Cricket match → 0
- Noise → 0
- Traffic → tiny
- Festival → moderate
- Temperature → stays strong
- Rain → moderate
The model learns:
“Sales mainly depend on Temperature + Rain + Festival days. Everything else is noise.”
Why regularization helps
- Reduces dependence on random details
- Encourages simple rules
- Improves generalisation to future days
This is why regularization is essential in real‑world ML.
🎯 FINAL TL;DR (Perfect for Beginners)
| Concept | Meaning | Tea‑Stall Analogy |
|---|---|---|
| Linear Regression | Best straight‑line fit | Predict tea sales from temperature |
| Cost Function | Measures wrongness | How far prediction is from real tea sales |
| Gradient Descent | Optimization technique | Adjust tea recipe until perfect |
| Overfitting | Model memorises noise | Tracking dog barking & cricket matches |
| Regularization | Penalty for complexity | Forcing tea‑maker to use fewer ingredients |
| Regularized Cost | Normal cost + penalty | Prevents “overthinking” the prediction |