I Built a Tool to Test Whether Multiple LLMs Working Together Can Beat a Single Model
Source: Dev.to
The Question
Can you get a better answer by having multiple LLMs collaborate than by just asking one directly?
That’s the thesis behind Occursus Benchmark — an open‑source benchmarking platform that systematically tests multi‑model LLM synthesis pipelines against single‑model baselines across 4 providers and 22 orchestration strategies.
Screenshots
 |  |  |
What It Does
Occursus Benchmark runs the same task through 22 different orchestration strategies — from a simple single‑model call to a 13‑call graph‑mesh collaboration — and scores every output using dual blind judging (two frontier models score independently on a 0‑100 scale, then the scores are averaged). This tells you whether adding pipeline complexity actually improves quality, or just burns tokens and money.
The tool supports four LLM providers:
| Provider | Model |
|---|---|
| Ollama | Local / free |
| OpenAI | GPT‑4o |
| Anthropic | Claude Sonnet 4 |
| Gemini |
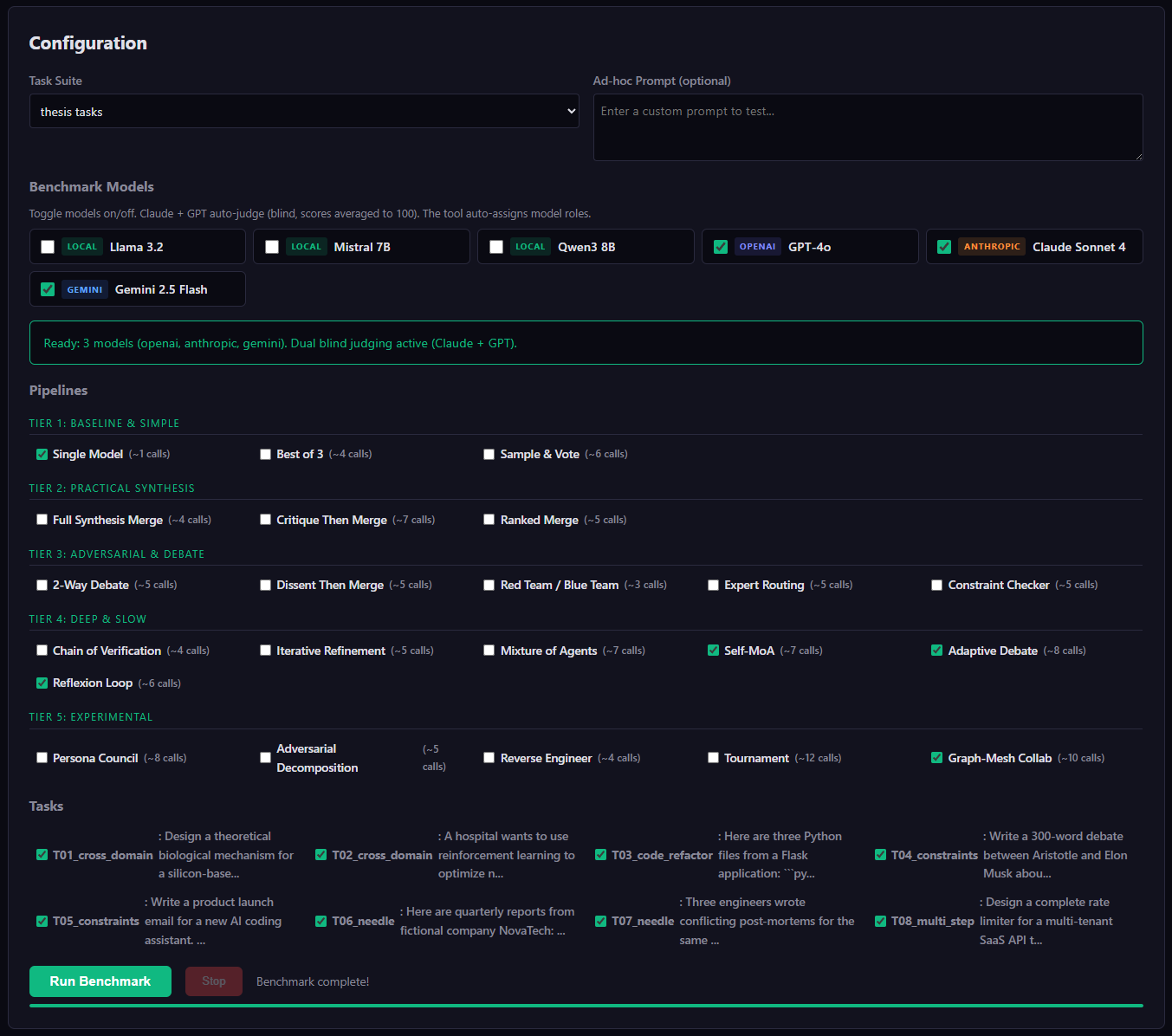
You can toggle models on and off; the tool auto‑assigns them to pipeline roles (generator, critic, synthesizer, reviewer).
The 22 Pipelines
| Tier | Pipelines | Strategy |
|---|---|---|
| 1 — Baseline | Single Model, Best of 3, Sample & Vote | Direct call and simple selection |
| 2 — Synthesis | Full Merge, Critique Then Merge, Ranked Merge | Multi‑persona generation + synthesis |
| 3 — Adversarial | 2‑Way Debate, Dissent Merge, Red Team/Blue Team, Expert Routing, Constraint Checker | Models challenge each other’s work |
| 4 — Deep | Chain of Verification, Iterative Refinement, Mixture of Agents, Self‑MoA, Adaptive Debate, Reflexion | Multi‑round reasoning loops |
| 5 — Experimental | Persona Council, Adversarial Decomposition, Reverse Engineer, Tournament, Graph‑Mesh | Heavy orchestration (8‑13 calls) |
Notable Pipeline Architectures
| Architecture | Source | Highlight |
|---|---|---|
| Self‑MoA | Princeton 2025 | Same‑model sampling outperforms multi‑model mixing by 6.6 % |
| Adaptive Debate / A‑HMAD | 2025 | Specialist debaters achieved +13.2 % over baselines on GSM8K |
| Reflexion | 2023+ | Verbal self‑reflection memory produces >18 % accuracy gains |
| Graph‑Mesh | MultiAgentBench, ACL 2025 | All‑to‑all topology outperforms star/chain/tree |
Two Ways to Call LLMs: API or Subscription
One of the key features is dual provider mode — you choose how the tool connects to cloud LLMs.
API Mode (Default)
- Standard REST API calls using your API keys.
- Full control over
temperature,max_tokens, and concurrency. - Costs roughly $0.01‑$0.05 per call depending on the model.
Subscription CLI Mode
Routes calls through your existing paid subscriptions at $0 extra cost:
| CLI | Provider | Subscription Required |
|---|---|---|
claude -p | Anthropic | Pro / Max |
codex exec | OpenAI | ChatGPT |
gemini -p | Gemini |
This makes running large benchmark suites economically viable — a full 22‑pipeline × 8‑task run with dual judging makes ~700+ LLM calls. At API rates that’s $50‑$100; with subscription mode it’s essentially free.
Trade‑off: Subscription CLIs don’t expose
temperatureormax_tokens, so advanced toggles (token‑budget management, adaptive temperature) only work in API mode.
How It Works
- Toggle models on/off – 6 preset models across 4 providers, simple checkboxes.
- Select pipelines and tasks – Choose which strategies to benchmark against which problems.
- Click Run – The tool auto‑assigns models to roles:
- Claude or GPT as the primary generator and synthesizer
- The other as critic and alternative generator
- Gemini for diversity in multi‑model pipelines
- Ollama for speed
- Watch results stream in – Real‑time Server‑Sent Events update a score matrix, bar charts, and statistics as each cell completes.
- Dual blind judge – Both Claude and GPT score every output independently. Scores are averaged into a single 0‑100 result. Neither judge knows which pipeline produced the output.
4 Task Suites
| Suite | # Tasks | Difficulty | Purpose |
|---|---|---|---|
| Smoke | 5 | Easy | Quick validation |
| Core | 12 | Easy‑Medium | Standard benchmark |
| Stress | 8 | Hard | Complex reasoning and planning |
| Thesis | 8 | Very Hard | Designed to break single‑model ceilings |
Thesis‑Suite Highlights
| Task | Description |
|---|---|
| Cross‑domain synthesis | Design silicon‑based biology with chemistry equations (requires deep knowledge from two unrelated fields). |
| Multi‑file code refactoring | Refactor a Flask app to FastAPI with six simultaneous requirements (SQL‑injection fix, OAuth2, async, Pydantic, bcrypt, preserve JSON schema). |
| Constraint satisfaction | Write a debate without using the letter “z”, with exactly three rhetorical questions and a ten‑word final sentence. |
| Needle‑in‑haystack | Find contradictions across five quarterly financial reports. |
| (additional tasks omitted for brevity) |
Bottom line: Occursus Benchmark lets you empirically answer whether multi‑model collaboration truly beats a single, powerful LLM — and it does so with a reproducible, open‑source framework.
ts and calculate EBITDA
These are problems where a single LLM routinely drops constraints, misses cross‑domain connections, or loses track of conflicting information.
Enhancement Toggles
Beyond pipeline selection, the tool offers toggles that modify how every pipeline behaves:
- Chain‑of‑Thought – Forces step‑by‑step reasoning before the final answer.
- Token Budget Management – Reserves 60 % of the token budget for the synthesis step (prevents verbose intermediate steps from starving the final answer).
- Adaptive Temperature – Auto‑classifies tasks (factual / code / analytical / creative) and sets the optimal temperature.
- Repeat Runs – Run each cell 1 / 3 / 5 times, reporting mean ± std dev for statistical significance.
- Cost Tracking – Displays estimated $ per pipeline using published per‑token pricing.
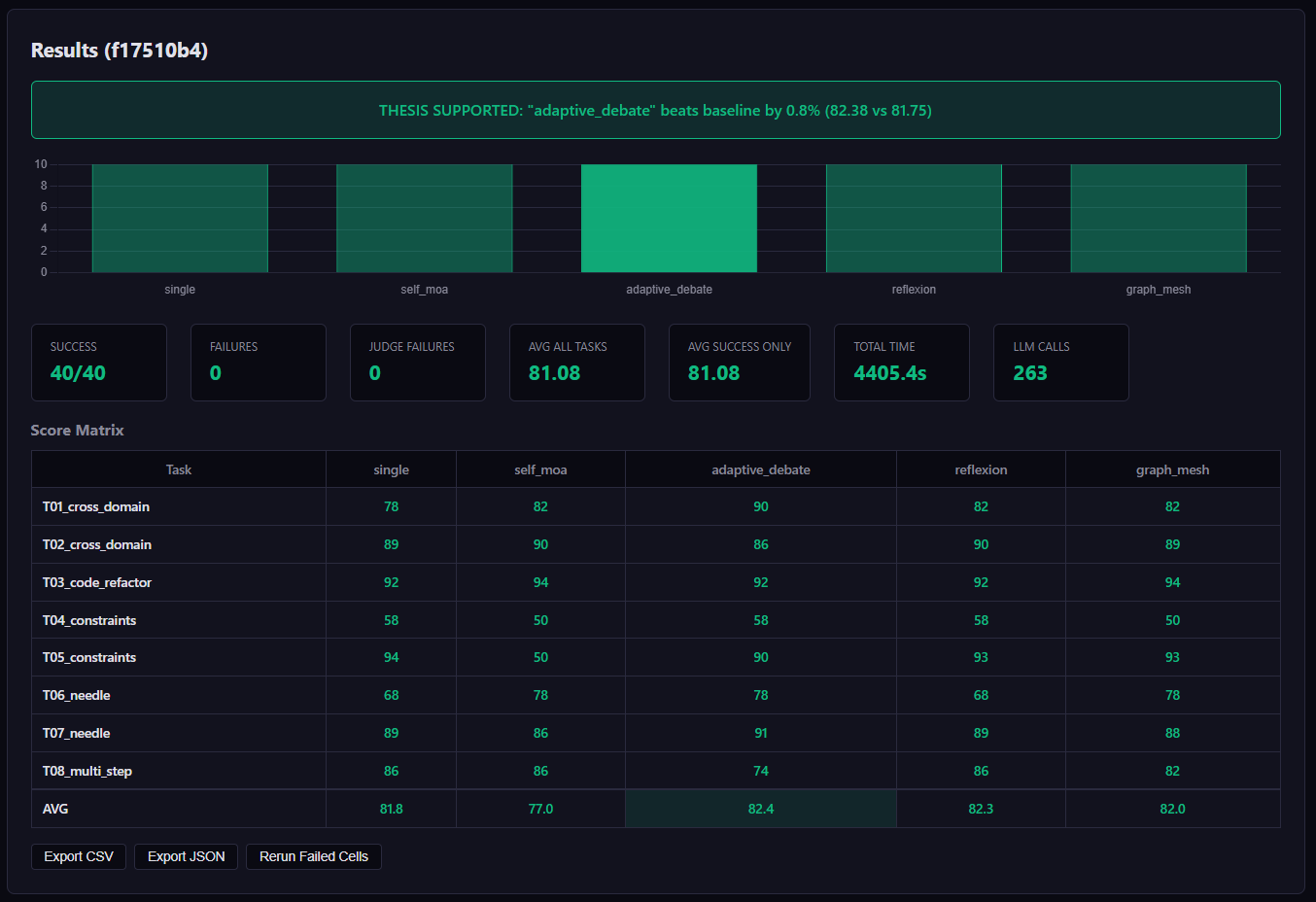
Early Results
We have now run two full benchmark rounds across the thesis task suite (8 hard tasks including cross‑domain synthesis, multi‑file code refactoring, constraint satisfaction, and needle‑in‑haystack analysis). Below are the combined results.
Latest Run: Research Pipelines on Thesis Tasks
| Pipeline | Avg Score | vs Baseline | Based On |
|---|---|---|---|
| Adaptive Debate | 82.4 | +0.6 | A‑HMAD 2025 |
| Reflexion Loop | 82.2 | +0.4 | Reflexion 2023+ |
| Graph‑Mesh Collab | 82.0 | +0.2 | MultiAgentBench ACL 2025 |
| Single (baseline) | 81.8 | — | — |
| Self‑MoA | 77.0 | -4.8 | Princeton 2025 |
Adaptive Debate won – its specialist debaters (logical reasoner, factual verifier, strategic planner) consistently improved answers through two rounds of domain‑specific critique. Reflexion and Graph‑Mesh were close behind.
Surprise: Self‑MoA underperformed the baseline by 4.8 points, contradicting the Princeton paper’s finding. On these hard tasks, same‑model temperature diversity wasn’t enough – the specialist critique from different model perspectives in Adaptive Debate added genuine value.
Combined Top 5 Pipelines (Across Both Runs)
| Rank | Pipeline | Avg Score | Calls | Strategy |
|---|---|---|---|---|
| 1 | Sample & Vote | 84.2 | 6 | 5 candidates, consistency selection |
| 2 | Ranked Merge | 84.1 | 5 | 3 experts ranked by judge, top‑weighted merge |
| 3 | Constraint Checker | 83.0 | 5 | Generate → validate → fix violations |
| 4 | Adaptive Debate | 82.4 | 8 | Specialist debaters, 2‑round critique |
| 5 | Reflexion Loop | 82.2 | 6 | Attempt → evaluate → reflect → retry |
The baseline single model scored 81.8 – 82.1 across both runs – meaning pipelines need to score above ~82 to justify their additional LLM calls.
Key Findings
- Multi‑model pipelines DO beat single‑model on hard tasks, but only by a narrow margin (1‑2 points) rather than the 10‑20‑point gaps reported in research papers.
- Gains come from:
- Selection pressure (Sample & Vote, Ranked Merge): generating multiple candidates and picking the best consistently outperforms single‑shot.
- Specialist critique (Adaptive Debate, Constraint Checker): domain‑specific feedback catches errors that a generic single model misses.
- Self‑correction (Reflexion): articulating why something failed produces better retries than a simple critique‑revise loop.
What Doesn’t Work Well
| Approach | Score | Issue |
|---|---|---|
| Generic debate (debate_2way) | 57.1 | Forcing opposition on settled facts destroys quality |
| Dissent‑then‑merge | 68.9 | Harsh critique without structure loses good content |
| Tournament | 73.9 | Elimination discards useful diversity |
| Self‑MoA | 77.0 | Same‑model sampling lacks the diverse perspectives hard tasks need |
Tech Stack
- Backend: Python, FastAPI (fully async)
- Providers: Ollama, OpenAI, Anthropic, Gemini – with auto‑routing by model name and exponential‑backoff retries
- Frontend: Vanilla HTML/JS/CSS, Chart.js, Server‑Sent Events
- Storage: SQLite (WAL mode), CSV/JSON export
- Pipelines: 10 module files implementing 22 strategies, all sharing a common
BasePipelineinterface
Try It
git clone https://github.com/rich1398/Multi-Model-Benchmarking.git
cd Multi-Model-Benchmarking
pip install -r requirements.txt
python app.py- Open
http://localhost:8000. - Configure your API keys (or just use Ollama for free local testing).
- Run your first benchmark.
GitHub:
This is an active research project. The next benchmark run will test all 22 pipelines against the thesis task suite with enhancement toggles enabled. If you have ideas for pipeline architectures that might beat single‑model baselines, open an issue or PR.