理解 Word2Vec – 第4部分:可视化词向量
发布: (2026年3月10日 GMT+8 03:56)
2 分钟阅读
原文: Dev.to
Source: Dev.to
可视化词向量
在我们 优化所有权重 之前,记住这些 权重代表与每个词关联的数值。由于本例为每个词使用 两个权重,我们可以 在坐标图上绘制每个词。
该图使用:
- x 轴 – 与顶部激活函数相连的权重值
- y 轴 – 与底部激活函数相连的权重值
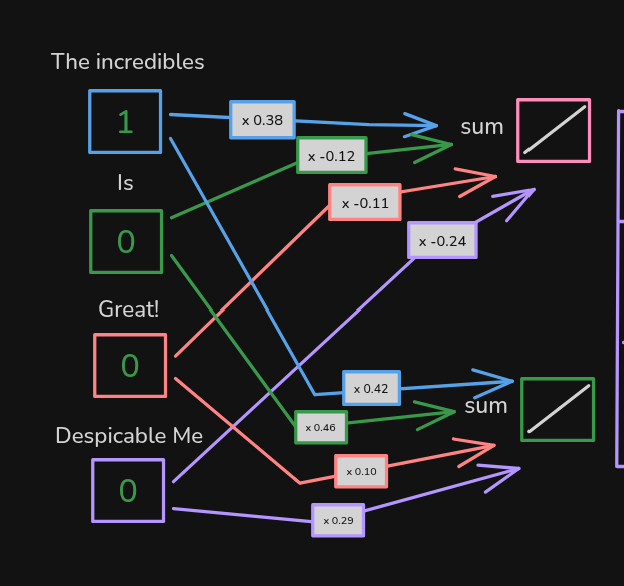
例如,“超人总动员” 在这里被绘制:
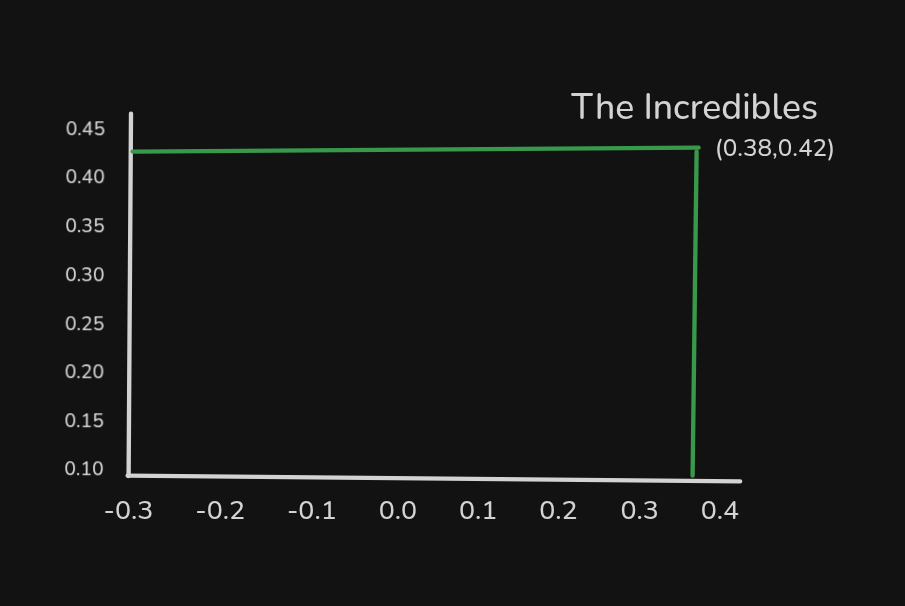
当我们 绘制其他词汇 时,图形如下所示:
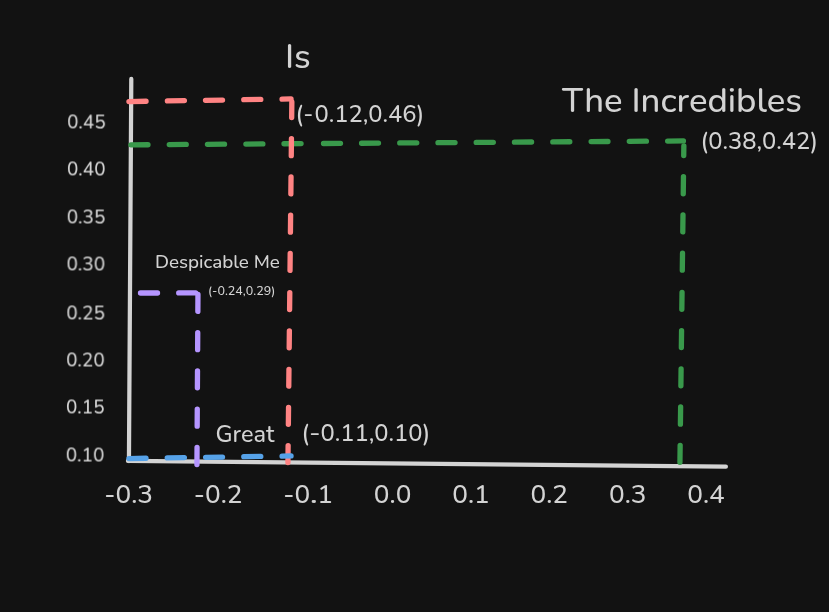
在这张图中,词语 “卑鄙的我” 与 “超人总动员” 目前并不相似。然而,在 训练数据 中,它们出现在 相同的上下文 中:
- 超人总动员真棒!
- 卑鄙的我真棒!
因此我们 期望反向传播会调整它们的权重,使它们 更加相似。
接下来会怎样?
在下一篇文章中,我们将看到 训练后图形是如何变化的。
Installerpedia(可选工具)
想要更轻松地安装工具、库或整个代码仓库吗?试试 Installerpedia,这是一个社区驱动、结构化的安装平台,让你几乎可以毫不费力、并且得到清晰可靠的指导来安装任何东西。
ipm install repo-name
🔗 在此探索 Installerpedia:https://hexmos.com/freedevtools/installerpedia/