理解注意力机制 – 第6部分:解码的最后一步
发布: (2026年4月5日 GMT+8 04:50)
2 分钟阅读
原文: Dev.to
Source: Dev.to
解码的最后一步
在上一篇文章中,我们得到了初始输出,但还没有得到 EOS 标记。
为了得到它,我们需要 展开解码器中的嵌入层和 LSTM,然后将翻译后的单词 “vamos” 输入到解码器展开后的嵌入层。之后,我们按照之前的相同步骤进行,只是这次使用 “vamos” 的编码值。
解码器的第二个输出是 EOS,这意味着解码完成。
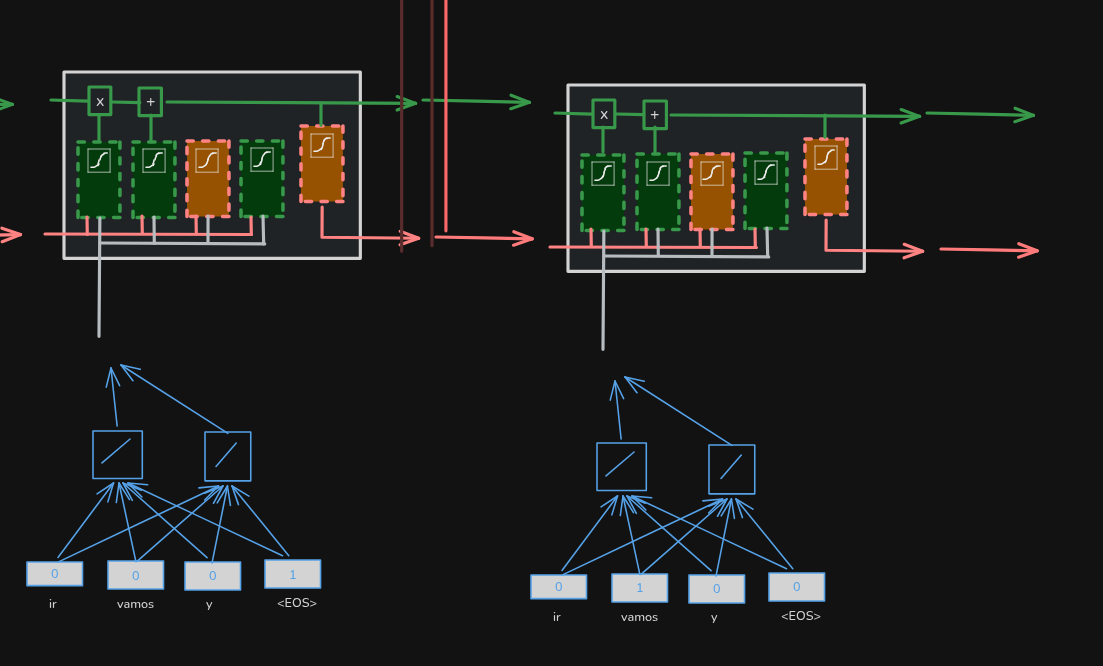
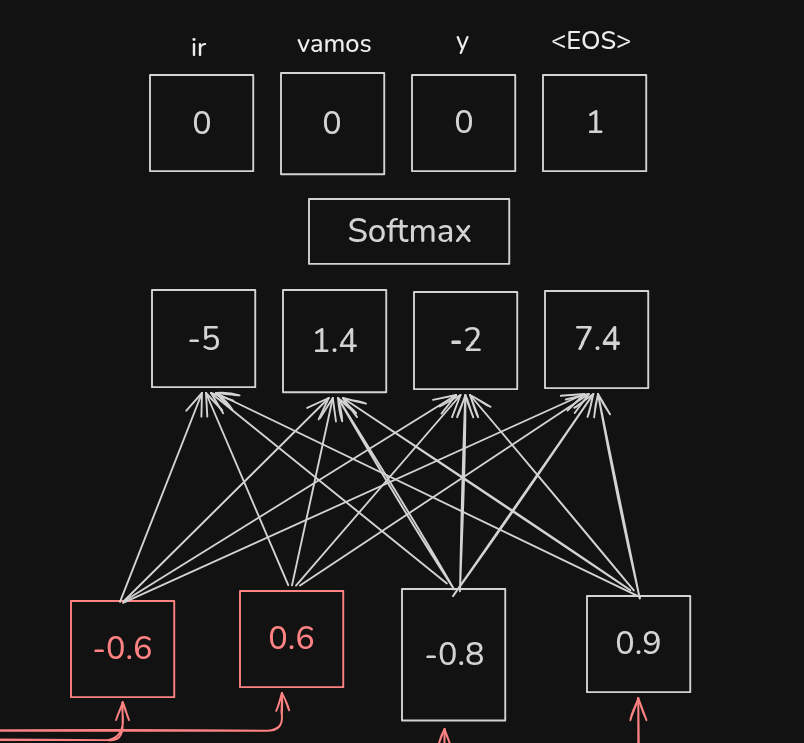
当我们为编码器‑解码器模型添加注意力机制时,编码器基本保持不变。然而,在解码的每一步,模型都可以访问每个输入词的单独编码。我们使用相似度得分和 softmax 函数 来决定 每个编码输入词的多少比例 应该用于预测下一个输出词。
现在我们已经在模型中加入了注意力机制,之后可能不再严格需要 LSTM。我们将在后续讨论 Transformer 时进一步探讨这一点。
Installerpedia(可选工具)
想要更轻松地安装工具、库或整个代码仓库吗?试试 Installerpedia,一个社区驱动、结构化的安装平台,让你只需极少的操作和清晰可靠的指导就能安装几乎任何东西。
ipm install repo-name