Hacker News 上的 LLM 研究正在枯竭
发布: (2026年4月25日 GMT+8 02:12)
4 分钟阅读
原文: Hacker News
Source: Hacker News
概览
我觉得最近在 Hacker News(HN)首页看到的 arXiv 论文少了,于是想确认这是否真实。
于是我让 Claude 做了一个快速分析:跟踪 arXiv 文章在 HN 上的占比随时间的变化。它查询了 BigQuery HN 数据集,按月份对文章进行分桶,并绘制了如下曲线:
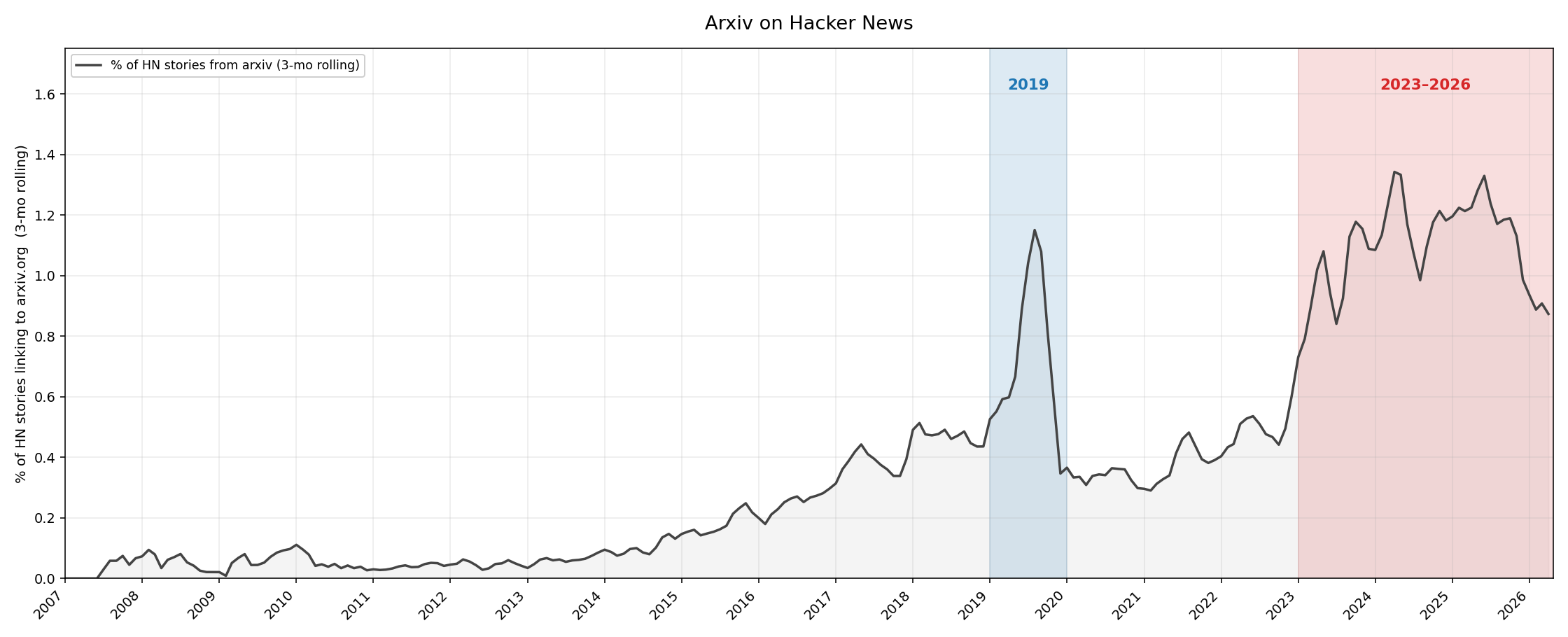
HN 文章链接到 arXiv 的比例 – 趋势证实了我的直觉:过去几个月 arXiv 帖子的比例在快速下降。有趣的是,2019 年还有一次高峰,这促使我们进一步调查。
arXiv 文章的话题分布
我让 Claude 从 2019 年挑选出投票数最高的前 100 篇论文,并按话题分组。结果显示,那是一次深度学习的高峰:前 100 篇中有 41 % 与深度学习相关。对 2023‑2026 年进行同样查询后发现,前 100 篇投票最高的论文中有 59 % 与大语言模型(LLM)或人工智能相关。
得到的图表:
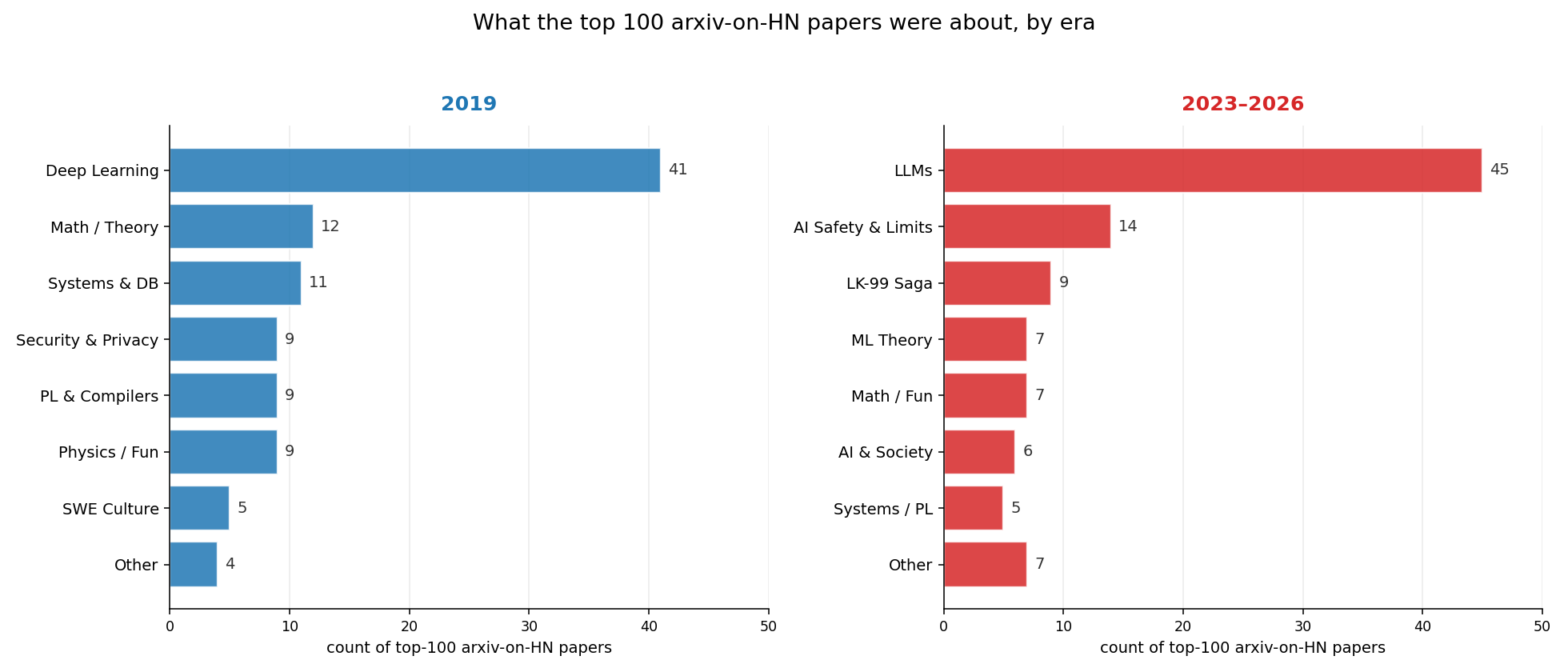
arXiv 文章的话题分布
仍然经得起时间考验的 2019 年论文
Claude 识别出了在前 100 名中仍然“经得起考验”的 2019 年论文:
- MuZero — 通过学习模型进行规划,掌握 Atari、围棋、国际象棋和将棋(161 分)– DeepMind 的 AlphaZero 继任者
- EfficientNet — 重新思考卷积神经网络的模型缩放(119 分)– 复合缩放,奠定了新的计算机视觉 SOTA
- XLNet — 用于语言理解的广义自回归预训练(79 分)– 曾短暂取代 BERT 的位置
- PyTorch: 一种命令式、高性能的深度学习库(113 分)– NeurIPS 论文,正式阐述了 PyTorch 的设计理念
- On the Measure of Intelligence(80 分)– Chollet 的 ARC / “类人智能”宣言
预测在 2023‑2026 年仍能经得起考验的论文
因为最近的论文是否会持久尚未可知,我让 Claude 猜测:
- DeepSeek‑R1 — 通过强化学习激励 LLM 的推理能力(1,351 分)– 首个基于可验证奖励的纯 RL 实现 o1 风格推理的开放配方
- Generative Agents — 人类行为的交互式模拟(391 分)– 经典的 “Smallville” 论文,LLM 代理架构的模板
- The Era of 1‑bit LLMs — BitNet b1.58,三值参数实现成本效益计算(1,040 分)– 首个可信的低位推理作为默认的案例
- Differential Transformer(562 分)– 带有降噪项的注意力机制,结构贡献清晰且有真实的理论支撑
- LK‑99 cluster — 常温超导预印本(2,408 + 1,690 分)– 标志性的元科学案例,而非物理学:高速开放科学以及众包复制的典范
这很有趣。谢谢 Claude。
引用
BibTeX 引用:
@online{castillo2026,
author = {Castillo, Dylan},
title = {LLM Research on {Hacker} {News} Is Drying Up},
date = {2026-04-24},
url = {https://dylancastillo.co/til/llm-research-on-hacker-news-is-dying.html},
langid = {en}
}如需署名,请按以下方式引用:
Castillo, Dylan. 2026. “LLM Research on Hacker News Is Drying Up.” April 24.