LLM Foundry:让 LLM 实际有用的乏味堆栈
发布: (2026年5月3日 GMT+8 12:39)
4 分钟阅读
原文: Dev.to
Source: Dev.to
介绍
大多数 AI 项目都是倒着构建的。团队先从模型开始,随后才发现需要记忆系统、语义检索、工具使用、测试以及当提供商离线时的备选方案。
什么是 LLM Foundry?
LLM Foundry 是围绕 LLM 的工作坊——而不是模型本身。它是让模型在实际工作中有用的层,而不仅仅是在演示中看起来聪明。
关键特性
- 语义检索 基于嵌入,使记忆搜索不只是关键词匹配。
- 多提供商支持,兼容 OpenAI 接口、Anthropic、Hugging Face 以及故障转移包。
- 压缩 + 记忆,将长任务压缩成紧凑的工作上下文。
- 代理轨迹,可导出为训练数据。
- 基准 + 测试套件运行,使系统可测试,而非凭感觉。
典型工作流
有用的模型栈并不是一次提示加祈祷。它通常遵循以下步骤:
- 阅读任务。
- 恢复相关记忆。
- 压缩杂乱信息。
- 向模型提问。
- 检查答案。
- 如有需要使用工具。
- 保存轨迹。
- 对结果进行基准测试。
这就是聊天机器人与真正可以在实际工作中信赖的系统之间的区别。
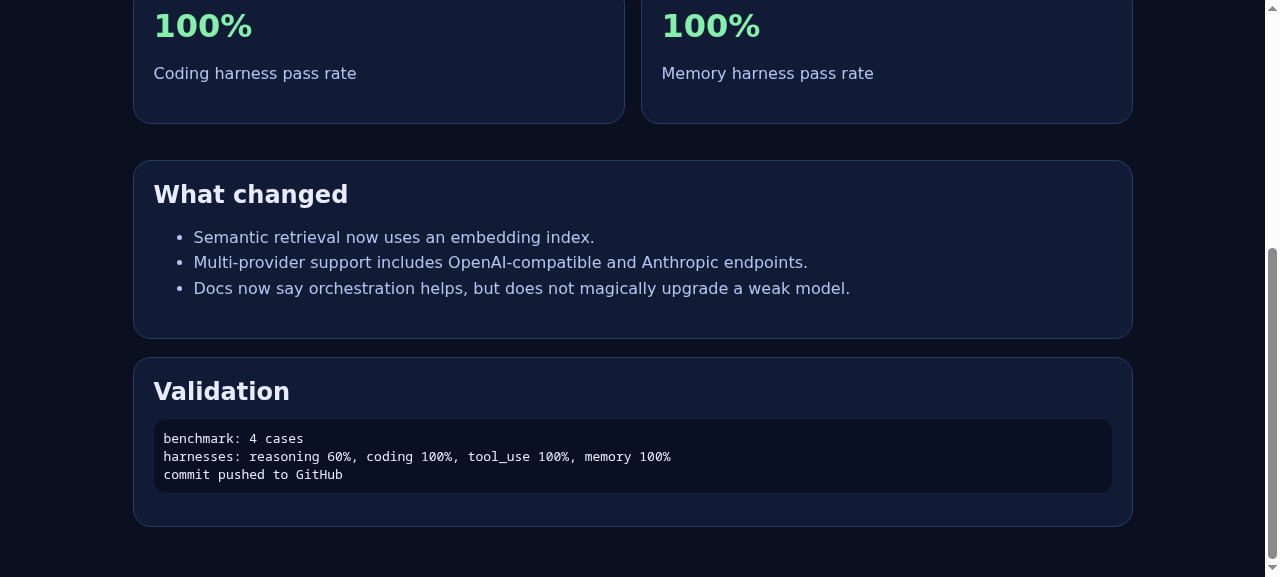
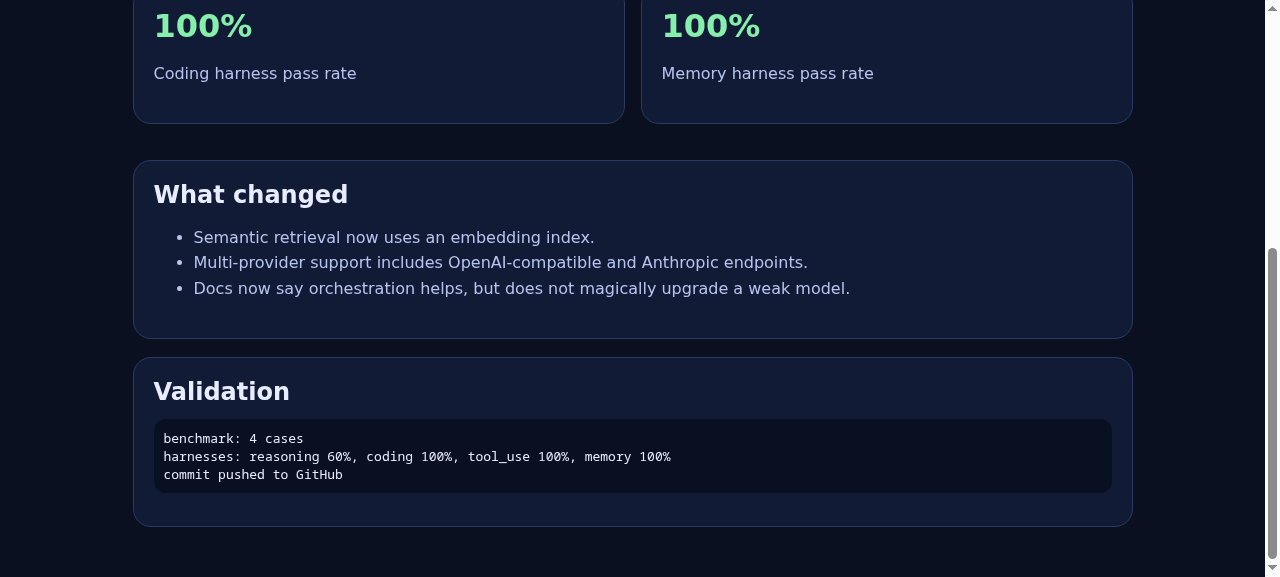
编排的重要性
如果基础模型在推理方面表现不佳,编排并不会神奇地让它达到前沿水平。你可以提升它的行为、可靠性、召回率和工作流质量,但无法凭空创造缺失的智能。
编排可以做到的是让一个尚可的模型变得更有用:
- 它看到的无关文本更少。
- 它更频繁地检索到正确的上下文。
- 它可以调用工具而不是盲目猜测。
- 它可以被检查并打分。
- 它的轨迹以后可以成为训练数据。
验证结果
实时报告: https://zo.pub/man42/llm-foundry
截图
- 顶部:https://zo.pub/man42/llm-foundry/top.png
- 中部:https://zo.pub/man42/llm-foundry/mid.png
- 底部:https://zo.pub/man42/llm-foundry/bottom.png
{kind=link}
{kind=link}
{kind=link}
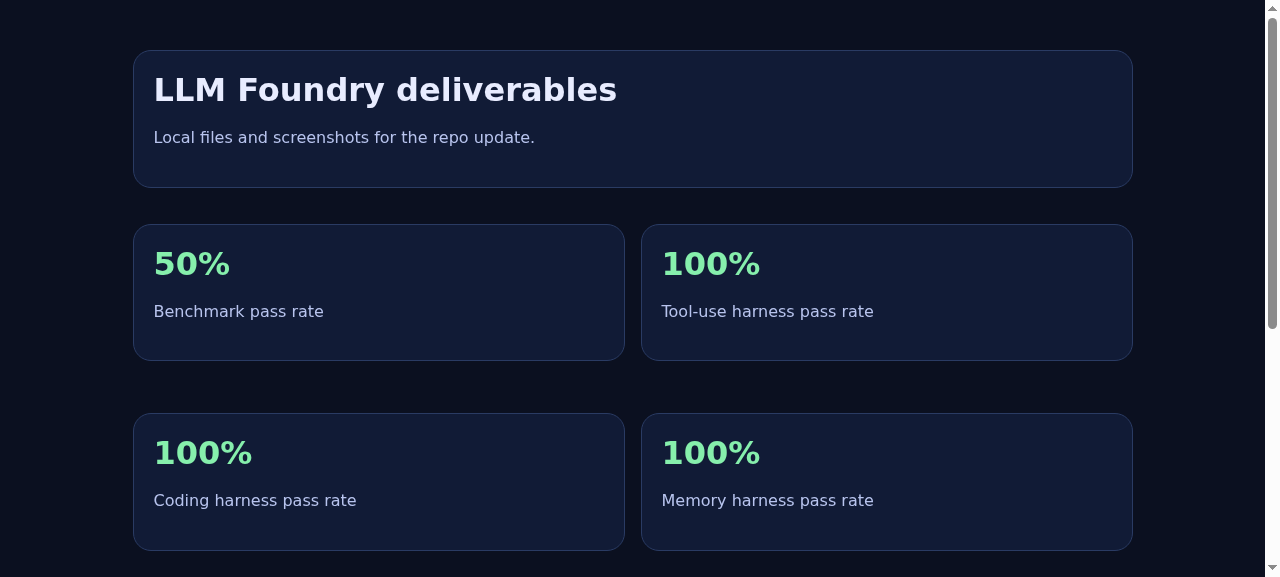
基准摘要
| 指标 | 通过率 |
|---|---|
| 整体基准 | 50 % |
| 推理测试 | 60 % |
| 编码测试 | 100 % |
| 工具使用测试 | 100 % |
| 记忆测试 | 100 % |
基准通过率不是炫耀,而是基线。关键在于系统是可度量的,从而可以改进。
记忆系统改进
检索层现在基于嵌入,使系统能够语义上寻找相关上下文,而不是仅凭字面词匹配。当任务表述改变但含义不变时,这一点尤为重要,能够避免因措辞差异而错过有用信息。
目标与基础设施
目标不仅是一个“模型包装器”,而是一个实用的 LLM 工作层:
- 模型可以是本地的也可以是远程的。
- 后端可以兼容 OpenAI 或 Anthropic。
- 记忆可以被压缩并重复使用。
- 轨迹可以转化为训练数据。
- 基准可以告诉你是否有任何改进。
这套基础设施让模型能够用于长期任务、研究以及产品工作流。
代码仓库
- GitHub 仓库: https://github.com/AmSach/llm-foundry
- GitHub 个人主页: https://github.com/AmSach
- 证明包: https://zo.pub/man42/llm-foundry