如何 NVIDIA H100 GPU 在 CoreWeave 的 AI 云平台上实现创纪录的 Graph500 运行
Source: NVIDIA AI Blog
打破纪录的 Graph500 基准
全球在大规模图处理方面表现最好的系统是基于商用集群构建的。
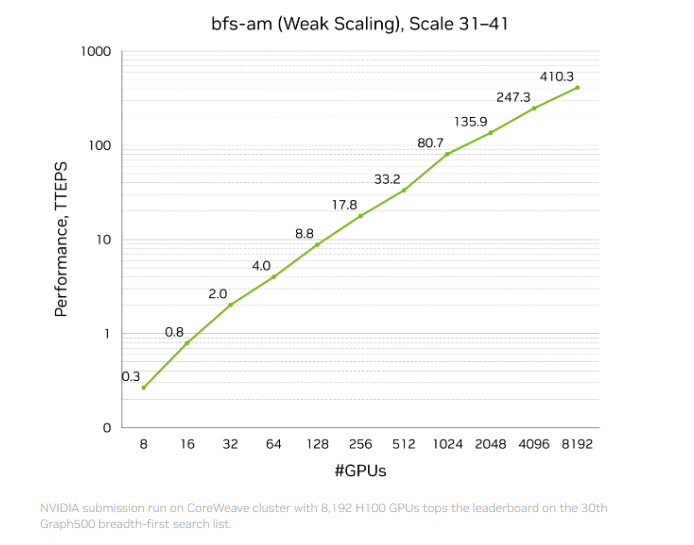
NVIDIA 上个月宣布了一项创纪录的基准结果:410 万亿遍历边每秒 (TEPS),在第 31 届 Graph500 广度优先搜索 (BFS) 排行榜上排名第一。
该测试在位于达拉斯的 CoreWeave 数据中心的加速计算集群上完成,使用 8,192 块 NVIDIA H100 GPU 处理一个拥有 2.2 万亿顶点 和 35 万亿边 的图。该性能是榜单上可比方案的两倍以上,包括那些部署在国家实验室的系统。
为了便于理解,假设地球上每个人都有 150 位朋友,那么得到的社交图将包含约 1.2 万亿条边。NVIDIA‑CoreWeave 系统可以在大约 三毫秒 内搜索完所有这些关系。
这一次突破不仅在于原始速度,还在于效率。排名前十的可比条目使用了约 9,000 台节点,而获胜的运行仅用了 1,000 多台节点,实现了 每美元性能提升 3 倍。
NVIDIA 充分利用了其全栈计算、网络和软件技术——包括 CUDA 平台、Spectrum‑X 网络、H100 GPU 以及全新的主动消息库——在最小化硬件占用的同时提升性能。这展示了 NVIDIA 计算平台如何让世界上最大的稀疏、不规则工作负载以及像 AI 训练这样的密集工作负载实现加速民主化。
大规模图的工作原理
图是现代技术的底层信息结构。它们捕获了海量网络中信息片段之间的关系,从社交网络到银行应用程序无所不包。
示例:在 LinkedIn 上,用户的个人资料是一个 顶点;与其他用户的连接是 边。有些用户只有少量连接,另一些则有数万连接,导致图的 稀疏且不规则。与结构化且密集的图像或语言模型不同,图是不可预测的。
Graph500 BFS 基准衡量系统在大规模下处理这种不规则性的能力。BFS 评估遍历每个顶点和每条边的速度;高 TEPS 分数表明系统拥有出色的互连、内存带宽以及能够充分利用这些能力的软件。本质上,它衡量系统“思考”和关联不同信息的速度。
当前的图处理技术
GPU 在加速密集工作负载(如 AI 训练)方面表现出色,而最大的稀疏线性代数和图工作负载传统上由 CPU 处理。
在处理图时,CPU 在计算节点之间移动数据。随着图的规模扩展到万亿级边,这种持续移动会导致瓶颈和通信拥堵。
开发者通过软件技术(如 主动消息)来缓解这一问题:主动消息发送小而可聚合的消息,在原地处理图数据,从而提升网络效率。然而,主动消息最初是为 CPU 设计的,受限于 CPU 的吞吐量和计算能力。
为 GPU 重新设计图处理
为了加速 BFS 运行,NVIDIA 打造了一个全栈、仅 GPU 的解决方案,重新构想了跨网络的数据移动方式。
- 基于 InfiniBand GPUDirect Async (IBGDA) 和 NVSHMEM 并行编程接口构建的自定义软件框架,实现了 GPU‑to‑GPU 主动消息。
- 通过 IBGDA,GPU 可以直接与 InfiniBand NIC 通信,使 数十万 GPU 线程 能够同时发送主动消息——远超 CPU 上仅几百线程的能力。
- 主动消息现在完全在 GPU 上运行,绕过 CPU,充分利用 NVIDIA H100 GPU 的大规模并行性和内存带宽来发送、移动和处理消息。
在 NVIDIA 合作伙伴 CoreWeave 稳定的高性能基础设施上运行,这一编排使可比运行的性能翻倍,同时使用的硬件和成本仅为其一小部分。
加速新工作负载
这一突破对高性能计算 (HPC) 具有深远影响。流体动力学、天气预报和网络安全等领域依赖于稀疏数据结构和类似大规模图的通信模式。
数十年来,这些领域在最大规模上一直受制于 CPU,即使数据从数十亿边增长到万亿边。NVIDIA 的获胜 Graph500 结果以及另外两项进入前十的条目,验证了一种面向 GPU 的新 HPC 大规模方法。
凭借 NVIDIA 在计算、网络和软件方面的全栈编排,开发者现在可以使用 NVSHMEM 和 IBGDA 等技术,高效扩展其最大的 HPC 应用,将超级计算性能带到商用可得的基础设施上。
随时了解最新的 Graph500 基准 并了解更多关于 NVIDIA 网络技术 的信息。