NVIDIA 正在推动工业革命的 3 种方式
Source: NVIDIA AI Blog
NVIDIA 加速计算平台正领先于曾经由 CPU 主导的超级计算基准测试,为全球的 AI、科学、商业和计算效率提供动力。
摩尔定律已走到尽头,平行处理是未来的方向。随着这一演进,NVIDIA GPU 平台如今独具优势,能够实现三大扩展定律——预训练、后训练和推理时计算——从下一代推荐系统和大语言模型(LLM)到 AI 代理及更广阔的应用。
CPU‑到‑GPU 的转变:计算史上的一次重大变革
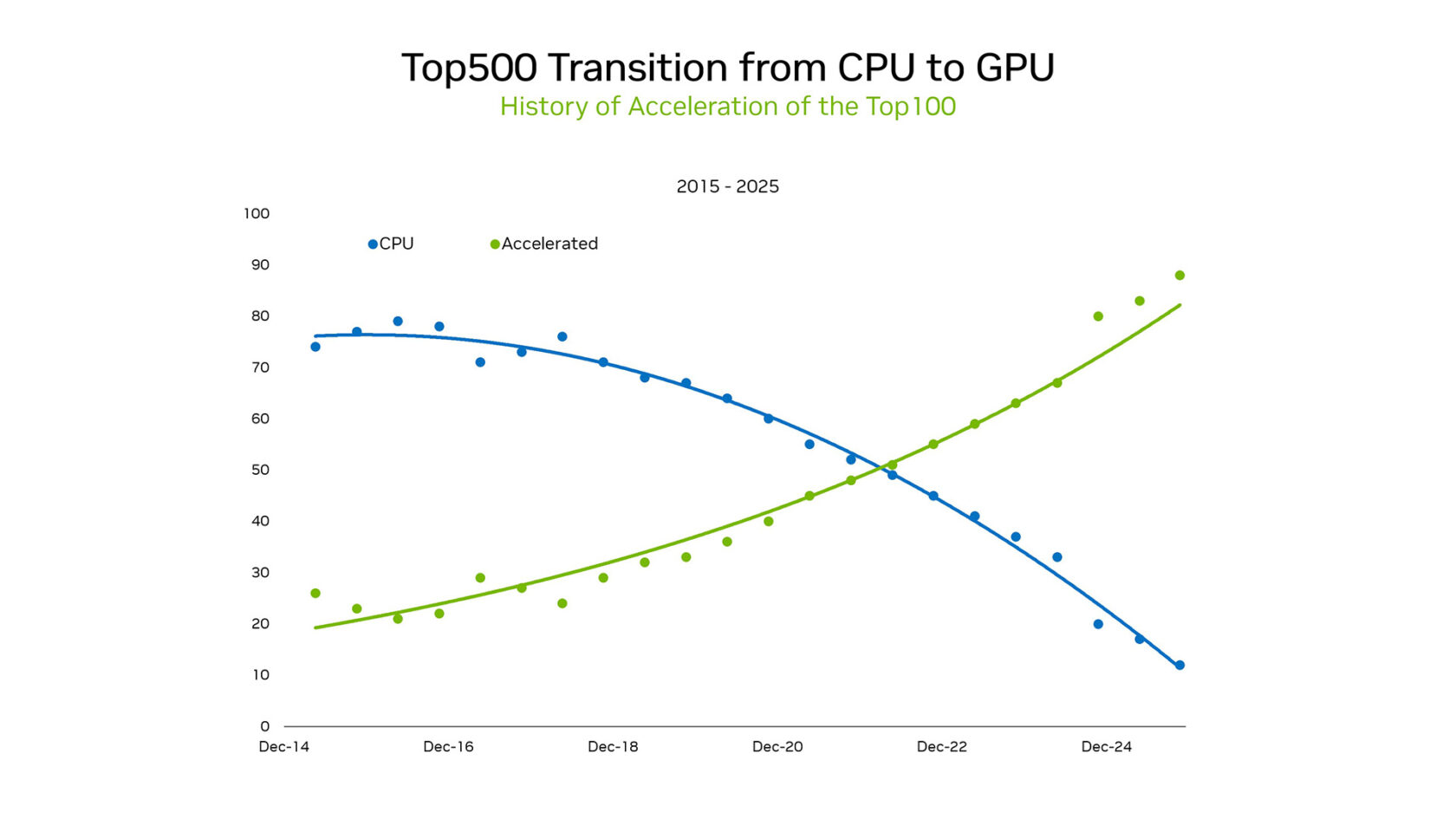
在 SC25 上,NVIDIA 创始人兼 CEO 黄仁勋强调了这一格局的转变。在 TOP100(TOP500 超级计算机列表的子集)中,超过 85 % 的系统使用 GPU。这一逆转标志着从 CPU 的串行处理范式向大规模并行加速架构的历史性转变。
在 2012 年之前,机器学习主要基于编程逻辑。统计模型在 CPU 上以硬编码规则的形式高效运行。AlexNet 在游戏 GPU 上的成功展示了图像分类可以通过示例学习,这一突破让并行 GPU 处理成为新一波计算浪潮的核心,使得在不产生不可承受能源消耗的情况下实现 Exascale 成为可能。
最近来自 Green500(全球能源效率最高的超级计算机排名)的数据进一步凸显了 GPU 与 CPU 的差距。前五名全部是 NVIDIA GPU,平均功耗为 70.1 吉弗洛普/瓦特,而仅使用 CPU 的系统平均只有 15.5 弗洛普/瓦特。这 4.5 倍的差异突显了转向 GPU 在总体拥有成本(TCO)上的巨大优势。
研究人员现在可以训练万亿参数模型、模拟聚变反应堆并加速药物发现,这些规模是 CPU 单独无法实现的。
另一个衡量 CPU 与 GPU 差异的指标来自 NVIDIA 在 Graph500 上的成绩。NVIDIA 使用 8,192 块 H100 GPU,创下 410 万亿遍历边每秒的纪录,处理了一个拥有 2.2 万亿节点和 35 万亿边的图。若使用 CPU 完成同样工作量,则需要约 150,000 台 CPU,充分说明了硬件占用的大幅度下降。
NVIDIA 还在 SC25 上展示了其 AI 超级计算平台远不止 GPU——网络、CUDA 库、内存、存储和编排均为协同设计,提供完整的全栈平台。

得益于 CUDA,NVIDIA 成为全栈平台。CUDA‑X 生态系统中的开源库和框架带来了巨大的加速。Snowflake 最近宣布将 NVIDIA A10 GPU 集成到其数据科学工作流中。Snowflake ML 现在预装了 NVIDIA cuML 和 cuDF 库,以加速常用的机器学习算法。
通过这种原生集成,Snowflake 用户可以在无需更改代码的情况下加速模型开发周期。NVIDIA 的基准测试显示,在 NVIDIA A10 GPU 上,随机森林的训练时间缩短 5 倍,而 HDBSCAN 的加速可达 200 倍,相较于 CPU。
从目前来看,GPU 是效率数学的必然结果,也是新范式的催化剂。但真正的魔力来自 CUDA‑X 以及众多开源软件库和框架。

最初出于能源效率的需求,如今已发展为一个科学平台:在大规模上实现仿真与 AI 的融合。NVIDIA GPU 在 TOP100 中的领先地位既是这一轨迹的证明,也是下一步突破的信号——跨学科的创新即将到来。
推动 AI 下一前沿的三大扩展定律
从 CPU 到 GPU 的转变不仅是超级计算的里程碑,更是 三大扩展定律 的基石,这三大定律描绘了 AI 工作流的路线图:预训练、后训练和推理时的扩展。
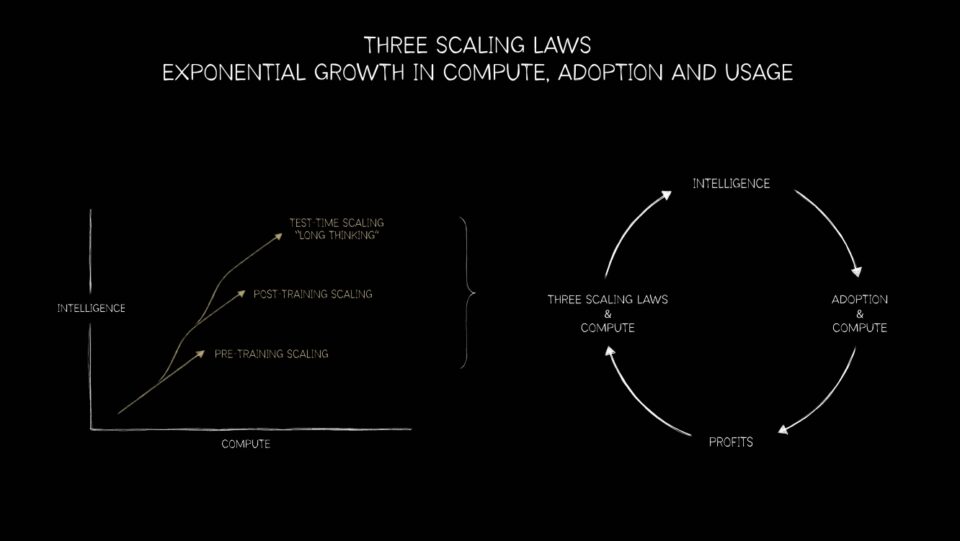
预训练扩展
预训练扩展是首个帮助行业的定律。研究人员发现,随着数据集、参数数量和计算规模的增长,模型性能会以可预测的方式提升。数据或参数翻倍,准确率和通用性都会出现跨越式提升。
在最新的 MLPerf Training 基准测试中,NVIDIA 平台在所有测试中均实现了最高性能,并且是唯一在全部测试中提交结果的平台。若没有 GPU,AI 研究的 “更大更好” 时代将因功耗和时间限制而停滞。
后训练扩展
后训练扩展则延伸了这一故事。基础模型构建完成后,需要进行细化——针对特定行业、语言或安全约束进行调优。诸如基于人类反馈的强化学习、剪枝和蒸馏等技术需要巨量的额外计算,有时甚至与预训练相当。GPU 提供了强大的算力,使得跨领域的持续微调和适配成为可能。
推理时扩展
推理时扩展是最新的定律,可能是最具变革性的。采用 mixture‑of‑experts 架构的现代模型能够在实时环境中进行推理、规划和多方案评估。链式思考、生成式搜索和代理式 AI 需要动态、递归的计算——往往超过预训练所需的算力。此阶段将推动对推理基础设施的指数级需求——从数据中心到边缘设备。
这三大定律共同解释了为何新一代 AI 工作负载离不开 GPU。预训练扩展已经让 GPU 成为不可或缺的工具。