开发者指南:ADK 中的 multi-agent 模式
Source: Google Developers Blog
2025年12月16日
Source: …
介绍
软件开发领域已经得出这样一个教训:单体应用无法扩展。无论是构建大型电子商务平台,还是复杂的 AI 应用,依赖单一的“一体化”实体都会产生瓶颈、增加调试成本,并限制专用性能。
同样的原理也适用于 AI 代理。一个承担过多职责的单一代理会成为 “样样通,样样松”。随着指令复杂度的提升,对特定规则的遵循度会下降,错误率会叠加,导致越来越多的 幻觉。如果你的代理出现故障,你不应该必须拆除整个提示来寻找 bug。
可靠性来源于去中心化和专门化。多代理系统 (MAS) 让你构建相当于微服务架构的 AI 体系。通过为各个代理分配特定角色(如解析器、批评者、调度器),你可以构建本质上更模块化、可测试且可靠的系统。
在本指南中,我们将使用 Google Agent Development Kit (ADK) 来演示八种关键设计模式——从顺序流水线到人机交互(Human‑in‑the‑Loop)模式——提供构建生产级代理团队所需的具体模式和伪代码。
Source: …
1. 顺序流水线模式(又称装配线)
让我们从代理工作流的核心开始。把这个模式想象成经典的装配线——Agent A 完成任务后直接把“接力棒”交给 Agent B。它是线性的、确定性的,而且调试起来非常轻松,因为你总是清楚数据来自何处。
这是处理数据流水线的首选架构。在下面的示例中,我们展示了处理原始文档的流程:
| 代理 | 职责 |
|---|---|
| Parser | 将原始 PDF 转换为文本 |
| Extractor | 提取结构化数据 |
| Summarizer | 生成最终摘要 |

在 ADK 中,SequentialAgent 原语会为你处理编排工作。这里的关键在于 状态管理:只需使用 output_key 写入共享的 session.state,下一个代理就能准确知道从哪里继续工作。
# ADK Pseudocode
# Step 1: Parse the PDF
parser = LlmAgent(
name="ParserAgent",
instruction="Parse raw PDF and extract text.",
tools=[PDFParser],
output_key="raw_text"
)
# Step 2: Extract structured data
extractor = LlmAgent(
name="ExtractorAgent",
instruction="Extract structured data from {raw_text}.",
tools=[RegexExtractor],
output_key="structured_data"
)
# Step 3: Summarize
summarizer = LlmAgent(
name="SummarizerAgent",
instruction="Generate summary from {structured_data}.",
tools=[SummaryEngine]
)
# Orchestrate the Assembly Line
pipeline = SequentialAgent(
name="PDFProcessingPipeline",
sub_agents=[parser, extractor, summarizer]
)2. Coordinator / Dispatcher Pattern(又称礼宾)
有时你不需要链式调用,而是需要一个决策者。在这种模式中,一个中心的、智能的代理充当 调度器。它分析用户意图并将请求路由到最适合该任务的专职代理。
适用于复杂的客服机器人,例如你可能需要将用户发送到 “Billing”(账单) 专家处理发票问题,或发送到 “Tech Support”(技术支持) 专家进行故障排除。
这依赖于 LLM 驱动的委派。定义一个父级 CoordinatorAgent 并提供一组专职 sub_agents。ADK 的 AutoFlow 机制会处理其余工作,根据你为子代理提供的描述转移执行。
# ADK Pseudocode
billing_specialist = LlmAgent(
name="BillingSpecialist",
description="Handles billing inquiries and invoices.",
tools=[BillingSystemDB]
)
tech_support = LlmAgent(
name="TechSupportSpecialist",
description="Troubleshoots technical issues.",
tools=[DiagnosticTool]
)
# The Coordinator (Dispatcher)
coordinator = LlmAgent(
name="CoordinatorAgent",
instruction=(
"Analyze user intent. Route billing issues to BillingSpecialist "
"and bugs to TechSupportSpecialist."
),
sub_agents=[billing_specialist, tech_support]
)Source: …
3. 并行 Fan‑Out / Gather 模式(又称章鱼)
速度至关重要。如果任务之间没有依赖关系,为什么要一个接一个地执行呢?在此模式中,多个代理 同时 执行任务,以降低延迟或获得多元化的视角。它们的输出随后由最终的 合成器 代理进行聚合。
非常适用于 自动代码审查:生成一个 安全审计员、一个 风格强制执行器 和一个 性能分析师,并行审查 Pull Request。它们完成后,合成器 代理将它们的反馈合并为一条统一、连贯的审查评论。
在 ADK 中应使用 ParallelAgent 来同时运行 sub_agents。虽然这些代理在不同的执行线程中运行,但它们共享会话状态。为防止竞争条件,请确保每个代理将其数据写入 唯一键。
# ADK Pseudocode (illustrative)
security_auditor = LlmAgent(
name="SecurityAuditor",
instruction="Identify security vulnerabilities in the code.",
output_key="security_report"
)
style_enforcer = LlmAgent(
name="StyleEnforcer",
instruction="Check code style compliance.",
output_key="style_report"
)
performance_analyst = LlmAgent(
name="PerformanceAnalyst",
instruction="Analyze performance bottlenecks.",
output_key="performance_report"
)
# Synthesizer that gathers the reports
synthesizer = LlmAgent(
name="ReviewSynthesizer",
instruction=(
"Combine {security_report}, {style_report}, and {performance_report} "
"into a single review comment."
),
tools=[CommentFormatter]
)
# Parallel execution
parallel_review = ParallelAgent(
name="ParallelCodeReview",
sub_agents=[security_auditor, style_enforcer, performance_analyst],
gather_agent=synthesizer
)其余五种模式(Human‑in‑the‑Loop、Retry‑with‑Fallback、Knowledge‑Base Augmentation、Adaptive Routing 和 Self‑Healing)遵循相同的清晰结构化方法,详见完整指南。
# Define parallel workers
security_scanner = LlmAgent(
name="SecurityAuditor",
instruction="Check for vulnerabilities like injection attacks.",
output_key="security_report"
)
style_checker = LlmAgent(
name="StyleEnforcer",
instruction="Check for PEP8 compliance and formatting issues.",
output_key="style_report"
)
complexity_analyzer = LlmAgent(
name="PerformanceAnalyst",
instruction="Analyze time complexity and resource usage.",
output_key="performance_report"
)
# Fan‑out (The Swarm)
parallel_reviews = ParallelAgent(
name="CodeReviewSwarm",
sub_agents=[security_scanner, style_checker, complexity_analyzer]
)
# Gather / Synthesize
pr_summarizer = LlmAgent(
name="PRSummarizer",
instruction=(
"Create a consolidated Pull Request review using "
"{security_report}, {style_report}, and {performance_report}."
)
)
# Wrap in a sequence
workflow = SequentialAgent(sub_agents=[parallel_reviews, pr_summarizer])4. 层次分解(又称 俄罗斯套娃)
有时一个任务对单个代理的上下文窗口来说太大。高层代理可以将复杂目标拆解为子任务并进行委派。与路由模式不同,父代理可能只委派 部分 任务,并在继续自身推理之前等待结果。
在下图中,ReportWriter 并不自行进行研究。它将工作委派给 ResearchAssistant,后者又管理 WebSearch 和 Summarizer 工具。
你可以把子代理当作工具来使用。通过将代理包装在 AgentTool 中,父代理可以显式调用它,从而把子代理的整个工作流视为一次函数调用。
# ADK Pseudocode
# Level 3: Tool Agents
web_searcher = LlmAgent(
name="WebSearchAgent",
description="Searches web for facts."
)
summarizer = LlmAgent(
name="SummarizerAgent",
description="Condenses text."
)
# Level 2: Coordinator Agent
research_assistant = LlmAgent(
name="ResearchAssistant",
description="Finds and summarizes info.",
sub_agents=[web_searcher, summarizer]
)
# Level 1: Top‑Level Agent
report_writer = LlmAgent(
name="ReportWriter",
instruction=(
"Write a comprehensive report on AI trends. "
"Use the ResearchAssistant to gather info."
),
tools=[AgentTool(research_assistant)]
)5. 生成器与批评者(又称 编辑桌)
生成高质量、可靠的输出往往需要第二双眼睛。在此模式中,你将 创建 与 验证 分离:
- 生成器 – 产生草稿。
- 批评者 – 根据硬编码的标准或逻辑检查对草稿进行审查。
该架构包含一个条件循环:如果审查通过,循环结束,内容最终确定;否则,反馈会被送回生成器进行修订。这在需要语法检查的代码生成或必须符合合规标准的内容创作中尤为有用。
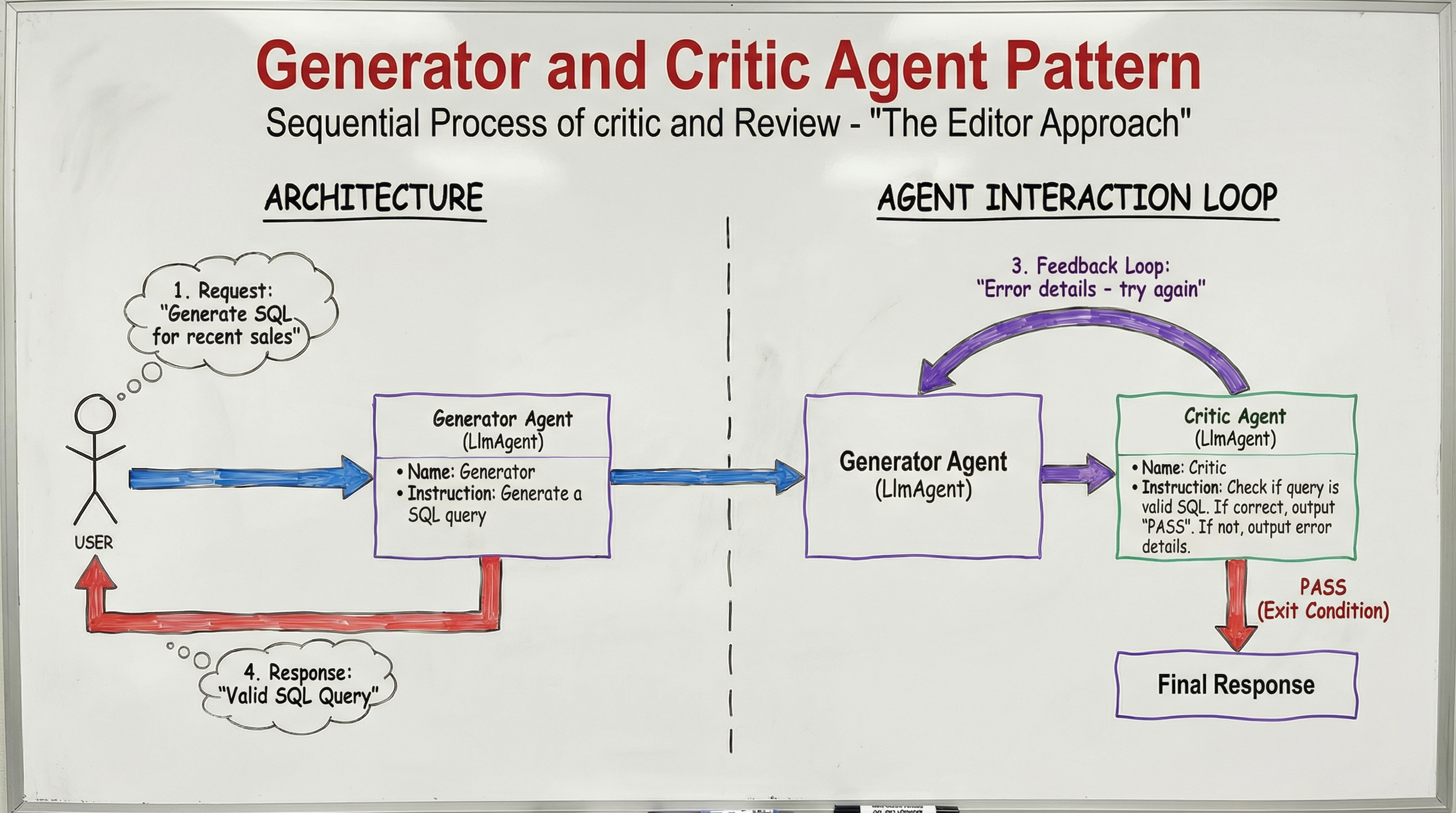
在 ADK 中的实现使用 SequentialAgent 来处理草稿与审查的交互,并使用父级 LoopAgent 来强制质量门。
# ADK Pseudocode
# The Generator
generator = LlmAgent(
name="Generator",
instruction=(
"Generate a SQL query. If you receive {feedback}, "
"fix the errors and generate again."
),
output_key="draft"
)
# The Critic
critic = LlmAgent(
name="Critic",
instruction=(
"Check if {draft} is valid SQL. If correct, output 'PASS'. "
"If not, output error details."
),
output_key="feedback"
)
# The Loop
validation_loop = LoopAgent(
name="ValidationLoop",
sub_agents=[generator, critic],
condition_key="feedback",
exit_condition="PASS"
)6. 迭代细化(aka 雕塑家)
优秀的作品很少在一次草稿中完成。正如人类作者会反复修改、润色和编辑,代理也可能需要多次尝试才能达到期望的质量。该模式在 Generator‑Critic 思路的基础上进一步强调 定性改进,而不是简单的通过/未通过检查。
- Generator – 创建初始粗稿。
- Critique Agent – 提供优化建议。
- Refinement Agent – 根据这些建议对输出进行打磨。
循环会持续进行,直至满足质量阈值。ADK 的 LoopAgent 支持两种退出机制:
- 硬限制 –
max_iterations。 - 提前完成 – 当在达到最大次数之前满足阈值时,代理可以在其
EventActions中设置escalate=True来发出信号。
# ADK Pseudocode
# Generator
generator = LlmAgent(
name="Generator",
instruction="Generate an initial rough draft.",
output_key="current_draft"
)
# Critique Agent
critic = LlmAgent(
name="Critic",
instruction=(
"Review {current_draft} and provide a list of improvement notes. "
"If the draft already meets quality standards, set "
"`escalate=True` in the response."
),
output_key="critique_notes"
)
# Refinement Agent
refiner = LlmAgent(
name="Refiner",
instruction=(
"Take {current_draft} and {critique_notes}, then produce a refined version."
),
output_key="refined_draft"
)
# Iterative Loop
refinement_loop = LoopAgent(
name="IterativeRefinement",
sub_agents=[generator, critic, refiner],
condition_key="critique_notes",
exit_condition="escalate",
max_iterations=5
)LLM 代理示例
critic = LlmAgent(
name="Critic",
instruction="Review {current_draft}. List ways to optimize it for performance.",
output_key="critique_notes"
)
refiner = LlmAgent(
name="Refiner",
instruction="Read {current_draft} and {critique_notes}. Rewrite the draft to be more efficient.",
output_key="current_draft"
)
loop = LoopAgent(
name="RefinementLoop",
max_iterations=3,
sub_agents=[critic, refiner]
)
workflow = SequentialAgent(sub_agents=[generator, loop])7. Human‑in‑the‑Loop (the human safety net)
AI 代理功能强大,但有时需要人类介入、验证或提供领域专长,才能在最终输出发布之前进行审查。此模式在自动化步骤之间插入人工检查点,确保满足安全、合规或质量标准。人类可以批准、编辑或拒绝代理的输出,随后工作流相应继续。