第35天提升我的Data Science技能
发布: (2025年12月27日 GMT+8 15:52)
3 分钟阅读
原文: Dev.to
Source: Dev.to
最近,我注意到我的学习方式有了变化。
我不再仅仅因为某件事能运行而感到兴奋。
我更感兴趣的是它为什么能工作,以及当我不留意时悄然出现的错误。
今天让我非常清楚地意识到这一点。
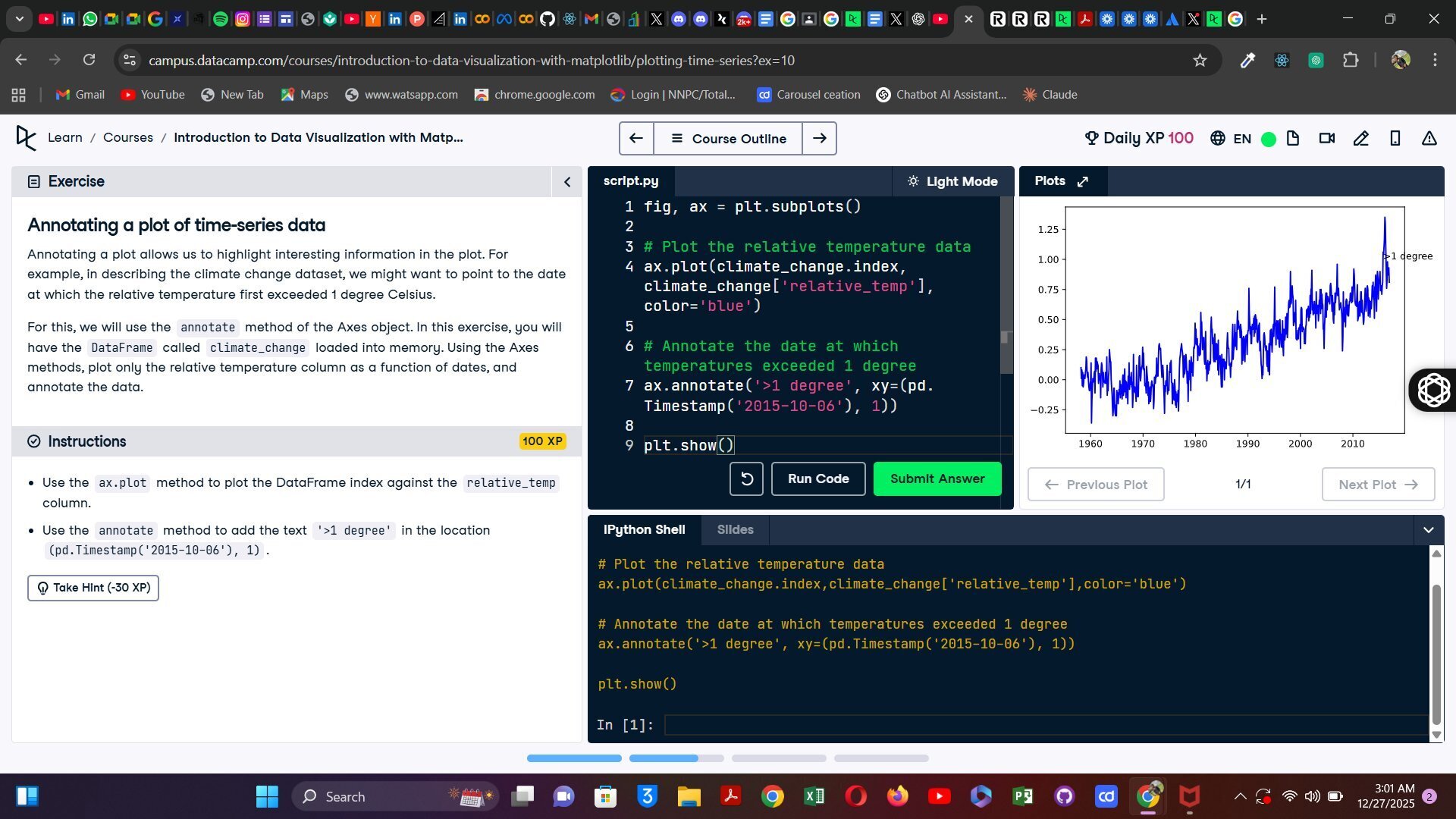
可视化即判断
在使用 Matplotlib 处理时间序列时,我在图表上标注了一个有意义的点。这不仅仅是在线上的一个标签;更像是在说:“这一刻很重要”。
这让我恍然大悟:可视化不是装饰,而是判断。你选择突出显示的内容,说明了你认为重要的东西。
导入数据的张力
与此同时,我在导入各种形式的数据——带有多个工作表的 Excel 文件、仅供机器使用的 pickle 文件、从 API 拉取的 JSON 数据。
导入数据看似简单……直到你意识到自己在毫无质疑的情况下对它寄予了多少信任:
- 我选对工作表了吗?
- 我了解缺失值的情况吗?
- 我是否仅因为它成功加载就假设结构是“干净”的?
使用 API
随后是 API——数据根本不存放在文件中,而是存在于别处,由我未参与的决策塑造,通过我必须遵守的端点暴露出来。
这让我感到非常谦卑。
收获
- 大多数数据工作中的错误并非源于技能不足。 而是因为在早期步骤中过于匆忙。
- 标注教会我放慢脚步,并问自己:“什么值得关注?”
- 导入让我明白结构从不中立。
- 使用 API 提醒我,真实世界的数据默认是混乱的,这很正常。
我仍在学习,仍在弄坏东西,也在修复它们。但我变得更有目的性,这感觉像是真正的进步。
给你的提问: 你在流程的哪一部分因为觉得它“基础”而匆忙完成,但其实可能需要更多的关注?
— SP