构建使用私有数据回答问题的 AI 聊天机器人(RAG 概述)
发布: (2026年1月16日 GMT+8 10:55)
4 分钟阅读
原文: Dev.to
Source: Dev.to
引言
大多数 AI 聊天机器人表现良好——直到你问它们一些具体的问题。
大型语言模型无法访问你的私有文档或内部知识。当缺少上下文时,它们会通过猜测来填补空白,从而导致幻觉和不可靠的答案。
在本文中,我们将演示如何通过检索增强生成(Retrieval‑Augmented Generation,RAG)构建一个使用私有数据回答问题的 AI 聊天机器人,并解释为什么这种方法比仅使用提示的聊天机器人更可靠。
为什么仅使用提示的聊天机器人会失效
- 开箱即用的 LLM:
- 不了解你的内部或私有数据
- 无法获取最新信息
- 即使不确定也会生成答案
这在以下场景中会成为真正的问题:
- 内部工具
- 文档助手
- 客服机器人
- 知识型应用
仅靠提示工程无法解决,因为模型仍然缺乏必要的上下文。
检索增强生成(RAG)到底做了什么
检索增强生成(RAG) 改变了聊天机器人回答问题的方式。
- 从你的数据源检索相关信息
- 将检索到的信息放入提示中
- 基于检索到的上下文生成答案
一种有用的类比:
- 仅使用提示的聊天机器人相当于参加闭卷考试。
- RAG 系统相当于参加开卷考试。
结果是更准确、更一致的响应。
高层架构
典型的 RAG 聊天机器人包括:
- 用户查询
- 检索层(搜索或向量相似度)
- 相关文档块
- 用于生成最终答案的 LLM
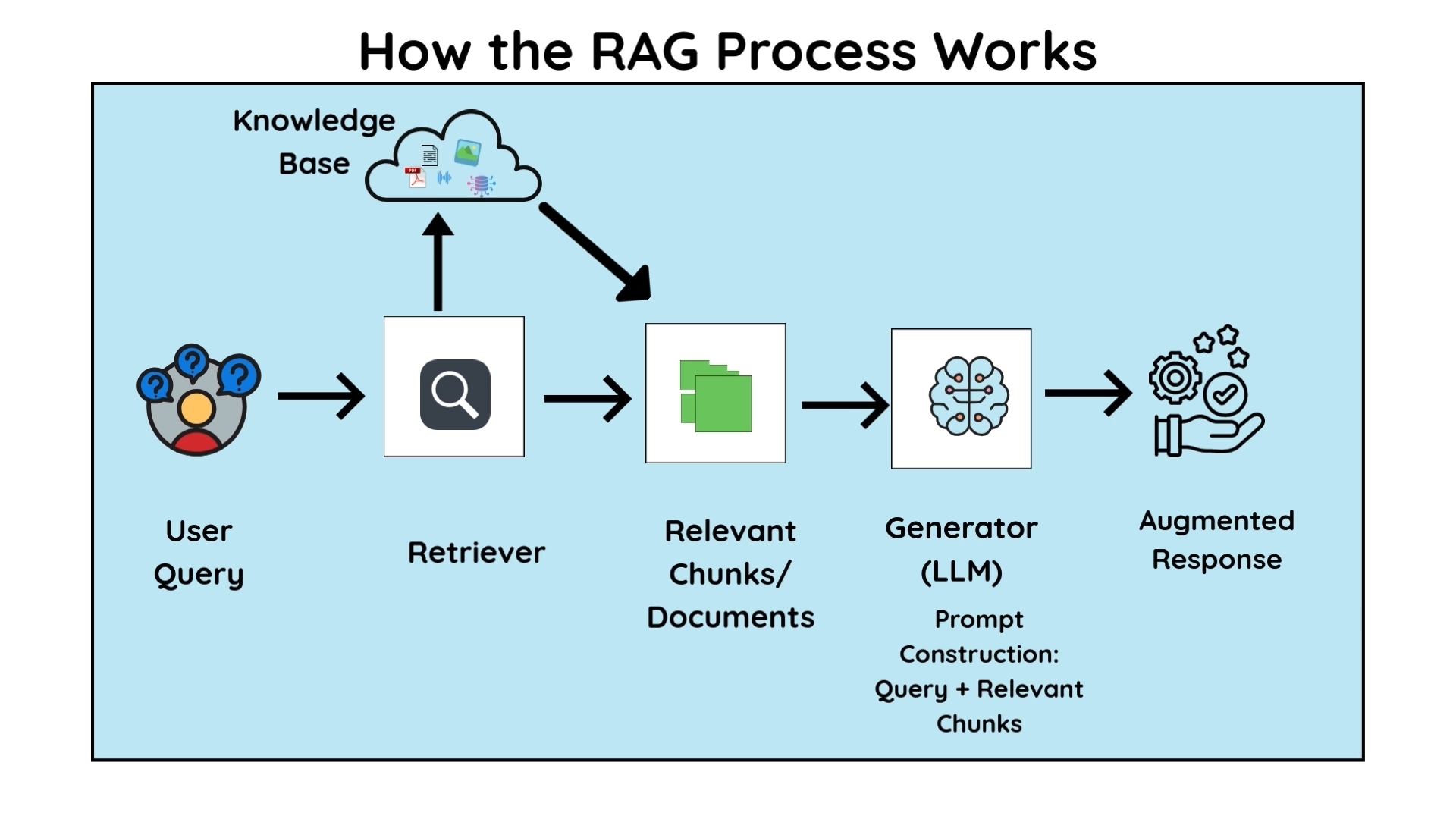
为何这种分离很重要
- 检索负责准确性
- 语言模型负责自然语言生成
何时适合使用 RAG
当满足以下条件时,RAG 是合适的选择:
- 数据是私有或内部的
- 准确性比创造性更重要
- 知识库会随时间变化
常见的使用场景包括:
- 内部文档助手
- 客服聊天机器人
- 知识库搜索工具
- 个人文档问答系统
常见的 RAG 错误
- 文档切块不当
- 检索配置薄弱
- 向提示中传入过多上下文
- 认为更大的模型可以解决检索问题
实际上,检索质量比模型选择更为关键。
完整演练与演示
完整的设置(包括数据检索和响应生成)在下面的视频中演示。
如果你的 AI 聊天机器人产生不可靠的答案,通常是因为缺少上下文——而不是模型本身的问题。在生成响应之前检索到正确的数据,正是使基于 RAG 的系统可靠的关键。