FunctionGemma 微调指南
Source: Google Developers Blog
Source: …
概览
在 Agentic AI 的世界里,调用工具的能力将自然语言转换为可执行的软件操作。上个月我们发布了 FunctionGemma,这是我们 Gemma 3 270M 模型的专门版本,经过明确的函数调用微调。它旨在帮助开发者构建快速且具成本效益的代理,将自然语言转化为可执行的 API 操作。
具体应用往往需要专用模型。在本文中,我们演示如何微调 FunctionGemma,以处理 工具选择歧义——即模型必须在一个或多个看似相似的函数之间做出选择的情形。我们还推出了 FunctionGemma Tuning Lab,这是一款演示工具,使得在不编写任何训练代码的情况下即可完成此过程。
为什么要为工具调用进行微调?
如果 FunctionGemma 已经支持工具调用,为什么微调仍然有用?
答案在于 上下文 和 策略——通用模型并不了解您的业务规则。常见的微调理由包括:
消除选择歧义
用户可能会问:“旅行政策是什么?” 基础模型可能会默认使用公开的 Google 搜索,而企业专属模型应当查询内部知识库。极度专业化
训练模型掌握公共数据中不存在的细分任务或专有格式,例如处理特定领域的移动操作(如控制设备功能)或解析内部 API 以生成复杂的合规报告。模型蒸馏
使用大模型生成合成训练数据,然后微调一个更小、更快的模型,以高效执行该工作流。
Source: …
案例研究:内部文档 vs. Google 搜索
数据集
bebechien/SimpleToolCalling (Hugging Face TRL)
挑战
我们需要一个模型能够将查询路由到正确的工具:
| Tool | Purpose(用途) |
|---|---|
search_knowledge_base | 内部文档 |
search_google | 公开信息 |
示例:
- 通用查询: “What are the best practices for writing a simple recursive function in Python?” → 应使用 Google。
- 政策查询: “What is the reimbursement limit for travel meals?” → 应使用 内部知识库。
解决方案
- 数据集准备 – 数据集包含需要在两种工具之间做选择的对话。
- 训练‑测试划分 – 我们保留一个独立的测试集用于在未见数据上评估,确保模型学习 路由逻辑 而不是记忆示例。
当使用 50 %/50 % 划分评估基础 FunctionGemma 模型时,它经常选择错误的工具,或建议“讨论”政策而不是发起函数调用。
⚠️ 关于数据分布的关键说明
数据的划分方式与数据本身同等重要。
from datasets import load_dataset
# Load the raw dataset
dataset = load_dataset("bebechien/SimpleToolCalling", split="train")
# Convert to conversational format
dataset = dataset.map(
create_conversation,
remove_columns=dataset.features,
batched=False,
)
# 50 % train – 50 % test (no shuffling)
dataset = dataset.train_test_split(test_size=0.5, shuffle=False)为何这很重要
- 指南使用 50/50 划分 并将
shuffle=False,因为原始数据集已经被打乱。 - 如果你的源数据按类别有序(例如先是所有
search_google示例,随后是所有search_knowledge_base示例),关闭洗牌会导致模型只在一种工具上训练,而在另一种工具上测试,性能会出现灾难性下降。
最佳实践
- 确认源数据是混合的。
- 如果不确定顺序,设置
shuffle=True(或在划分前先洗牌),以保证训练期间所有工具都有均衡的代表性。
结果
模型使用 SFTTrainer(监督微调)进行 8 个 epoch 的微调。损失曲线显示模型快速适应了新的路由逻辑:
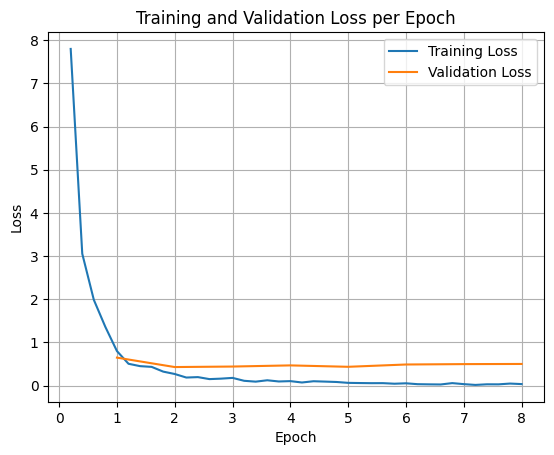
微调后,模型能够可靠地遵循企业政策。例如,查询:
“What is the process for creating a new Jira project?”
现在会产生正确的函数调用:
call:search_knowledge_base{query:Jira project creation process}模型已经学会区分内部政策问题和公开信息查询,并自动调用相应的工具。
Source: …
介绍 FunctionGemma 调优实验室
FunctionGemma 调优实验室是一个托管在 Hugging Face Spaces 上的用户友好演示。它简化了教模型学习您特定函数模式的整个过程。
关键特性
- 无代码界面 – 在 UI 中直接定义函数模式(JSON),无需 Python 脚本。
- 自定义数据导入 – 上传包含 用户提示、工具名称 和 工具参数 的 CSV。
- 一键微调 – 使用滑块调节学习率和 epoch 并立即开始训练。默认设置适用于大多数使用场景。
- 实时可视化 – 实时查看训练日志和损失曲线,监控收敛情况。
- 自动评估 – 实验室会在训练前后自动评估性能,立即反馈改进效果。
开始使用调优实验室
要在本地运行实验室,使用 Hugging Face CLI 克隆仓库并启动应用:
hf download google/functiongemma-tuning-lab --repo-type=space --local-dir=functiongemma-tuning-lab
cd functiongemma-tuning-lab
pip install -r requirements.txt
python app.py就这样——您可以在无需编写任何代码的情况下微调 FunctionGemma!
结论
无论您选择使用 TRL 编写自己的训练脚本,还是使用 FunctionGemma 调优实验室 的演示可视化界面,微调都是释放 FunctionGemma 完整潜力的关键。它可以将通用助手转变为能够遵循严格业务逻辑并处理复杂专有数据结构的专用代理。
感谢阅读!