在 Google TPU 上使用 Tunix 轻松微调 FunctionGemma
Source: Google Developers Blog
2026年2月3日
使用 Tunix 对 FunctionGemma 进行微调
FunctionGemma 是一种功能强大的小型语言模型,能够帮助开发者快速且低成本地部署能够将自然语言转换为可执行 API 调用的代理,尤其适用于边缘设备。在之前的 《FunctionGemma 微调指南》 博客中,我们的同事分享了使用 Hugging Face TRL 库在 GPU 上微调 FunctionGemma 的最佳实践。
本文我们将探索另一条路径,使用 Google Tunix 在 TPU 上完成微调。完整的 notebook 可在 此处 找到。
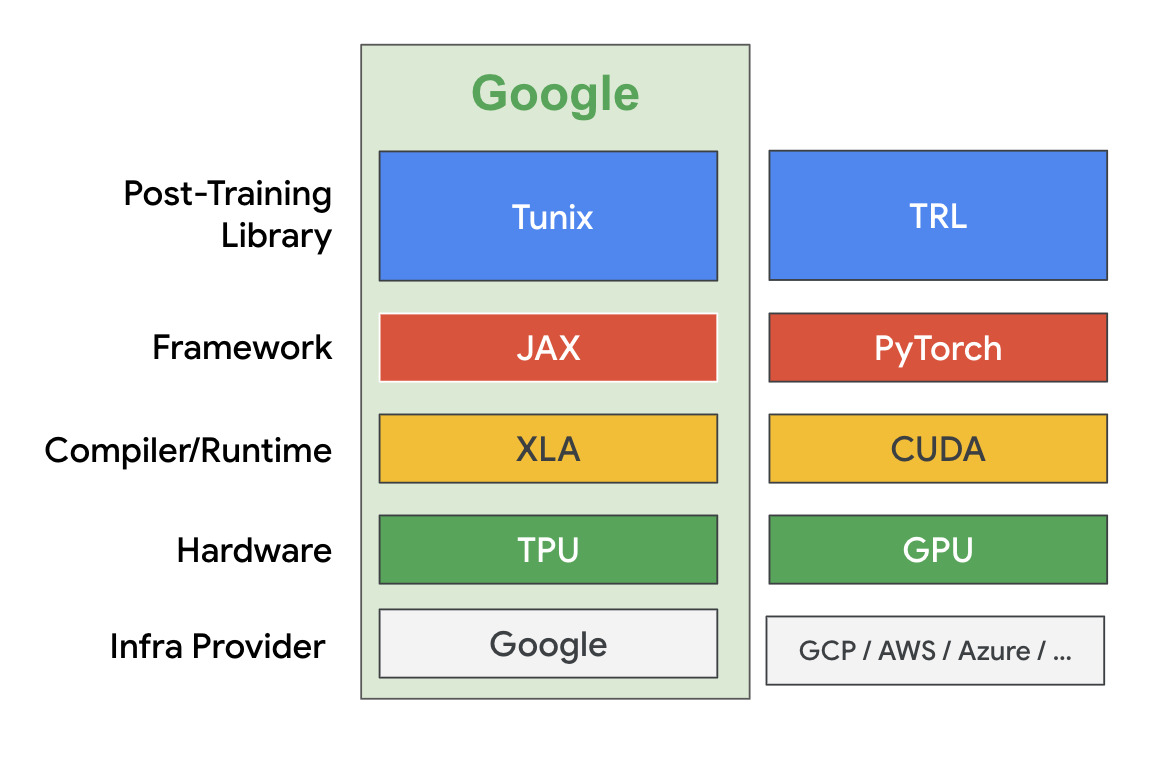
Tunix 是一个基于 JAX 实现的轻量级库,旨在简化大语言模型(LLM)的后训练流程。它是 扩展 JAX AI Stack 的一部分。Tunix 支持多种现代 LLM 后训练技术,包括监督微调、参数高效微调、偏好调优、强化学习以及模型蒸馏。它兼容最新的开源模型,如 Gemma、Qwen 和 LLaMA,并能够在硬件加速器上高效扩展。
在本教程中,我们使用 LoRA 对 FunctionGemma 进行监督微调,并在免费层的 Colab TPU v5e‑1 上运行全部步骤。我们使用的 Mobile Action 数据集与 之前的微调教程 中使用的相同。
1️⃣ 下载模型和数据集
MODEL_ID = "google/functiongemma-270m-it"
DATASET_ID = "google/mobile-actions"
local_model_path = snapshot_download(
repo_id=MODEL_ID,
ignore_patterns=["*.pth"]
)
data_file = hf_hub_download(
repo_id=DATASET_ID,
filename="dataset.jsonl",
repo_type="dataset"
)2️⃣ 创建一个简单的 mesh(不进行分片)
NUM_TPUS = len(jax.devices())
MESH = [(1, NUM_TPUS), ("fsdp", "tp")] if NUM_TPUS > 1 else [(1, 1), ("fsdp", "tp")]
mesh = jax.make_mesh(*MESH, axis_types=(jax.sharding.AxisType.Auto,) * len(MESH[0]))3️⃣ 加载模型并应用 LoRA 适配器
with mesh:
base_model = params_safetensors_lib.create_model_from_safe_tensors(
local_model_path, model_config, mesh
)
lora_provider = qwix.LoraProvider(
module_path=".*q_einsum|.*kv_einsum|.*gate_proj|.*down_proj|.*up_proj",
rank=LORA_RANK,
alpha=LORA_ALPHA,
)
model_input = base_model.get_model_input()
model = qwix.apply_lora_to_model(
base_model,
lora_provider,
rngs=nnx.Rngs(0),
**model_input,
)
state = nnx.state(model)
pspecs = nnx.get_partition_spec(state)
sharded_state = jax.lax.with_sharding_constraint(state, pspecs)
nnx.update(model, sharded_state)4️⃣ 用于仅完成(completion‑only)损失的自定义数据集
class CustomDataset:
def __init__(self, data, tokenizer, max_length=1024):
self.data = data
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.data)
def __iter__(self):
for item in self.data:
template_inputs = json.loads(item["text"])
prompt_and_completion = self.tokenizer.apply_chat_template(
template_inputs["messages"],
tools=template_inputs["tools"],
tokenize=False,
add_generation_prompt=False,
)
prompt_only = self.tokenizer.apply_chat_template(template_inputs["messages"][:-1],
tools=template_inputs["tools"],
tokenize=False,
add_generation_prompt=True,
)
tokenized_full = self.tokenizer(prompt_and_completion, add_special_tokens=False)
tokenized_prompt = self.tokenizer(prompt_only, add_special_tokens=False)
full_ids = tokenized_full["input_ids"]
prompt_len = len(tokenized_prompt["input_ids"])
if len(full_ids) > self.max_length:
full_ids = full_ids[: self.max_length]
input_tokens = np.full(
(self.max_length,), self.tokenizer.pad_token_id, dtype=np.int32
)
input_tokens[: len(full_ids)] = full_ids
input_mask = np.zeros((self.max_length,), dtype=np.int32)
if len(full_ids) > prompt_len:
mask_end = min(len(full_ids), self.max_length)
input_mask[prompt_len:mask_end] = 1
yield peft_trainer.TrainingInput(
input_tokens=jnp.array(input_tokens, dtype=jnp.int32),
input_mask=jnp.array(input_mask, dtype=jnp.int32),
)5️⃣ 数据生成器
def data_generator(split_data, batch_size):
dataset_obj = CustomDataset(split_data, tokenizer, MAX_LENGTH)
bat(代码片段在此处结束,保持原始来源的完整性。)
batch_tokens, batch_masks = [], []
for item in dataset_obj:
batch_tokens.append(item.input_tokens)
batch_masks.append(item.input_mask)
if len(batch_tokens) == batch_size:
yield peft_trainer.TrainingInput(
input_tokens=jnp.array(np.stack(batch_tokens)),
input_mask=jnp.array(np.stack(batch_masks)),
)
batch_tokens, batch_masks = [], []
print("Preparing training data...")
train_batches = list(data_generator(train_data, BATCH_SIZE))
val_batches = list(data_generator(val_data_for_loss, BATCH_SIZE))启动微调
print("Starting Training...")
max_steps = len(train_batches) * NUM_EPOCHS
lr_schedule = optax.cosine_decay_schedule(
init_value=LEARNING_RATE, decay_steps=max_steps
)
metrics_logging_options = metrics_logger.MetricsLoggerOptions(
log_dir=os.path.join(OUTPUT_DIR, "logs"), flush_every_n_steps=10
)
training_config = peft_trainer.TrainingConfig(
eval_every_n_steps=EVAL_EVERY_N_STEPS,
max_steps=max_steps,
checkpoint_root_directory=os.path.join(OUTPUT_DIR, "ckpts"),
metrics_logging_options=metrics_logging_options,
)
trainer = (
peft_trainer.PeftTrainer(model, optax.adamw(lr_schedule), training_config)
.with_gen_model_input_fn(gen_model_input_fn)
)
with mesh:
trainer.train(train_batches, val_batches)
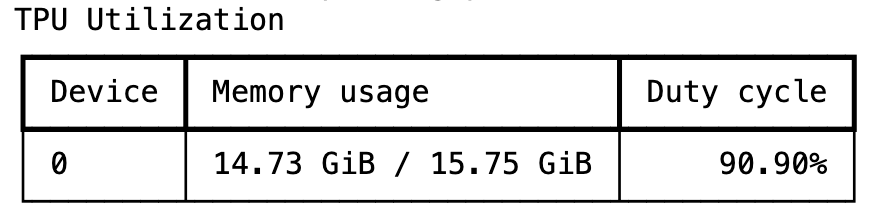
print("Training Complete.")训练只需几分钟,Tunix 在运行期间能够实现 TPU 的高利用率。
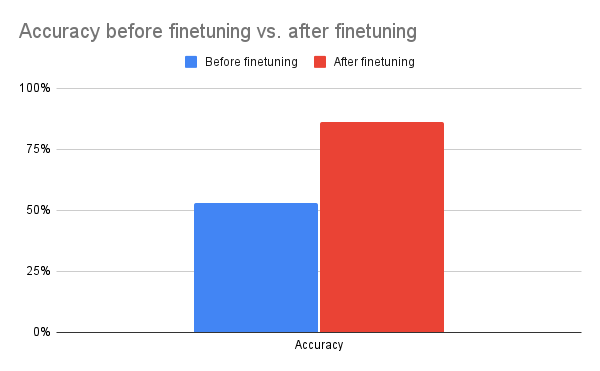
经过一个 epoch 的训练后,我们看到准确率显著提升,证明 Tunix 能以极低的开销带来质的改进。
当对性能满意后,我们合并 LoRA 适配器,并将微调后的模型导出为 safetensors,以供后续处理(例如使用 LiteRT 在设备上部署)。
merged_output_dir = os.path.join(OUTPUT_DIR, "merged")
print(f"Saving merged LoRA model to {merged_output_dir}")
gemma_params.save_lora_merged_model_as_safetensors(
local_model_path=local_model_path,
output_dir=merged_output_dir,
lora_model=model,
rank=LORA_RANK,
alpha=LORA_ALPHA,
)
print("Model Exported Successfully.")这就是微调 Functi 的完整工作流。
onGemma** with Tunix. 如图所示,Tunix 使用简便,并且能够高效利用 Google TPU。虽然本示例涉及监督微调——最简单的方法——Tunix 也支持更高级的技术,例如强化学习,我们还在积极添加更多的代理式训练能力。
结论
Tunix 在研究原型和生产就绪系统之间架起了桥梁。它的模块化、JAX 原生速度以及支持的算法广度,使其成为任何希望为特定任务打磨 LLM 的开发者的必备工具。