시스템 설계 기본: 시스템이 실제로 확장되는 방법
발행: (2026년 4월 9일 오전 06:22 GMT+9)
3 분 소요
원문: Dev.to
Source: Dev.to
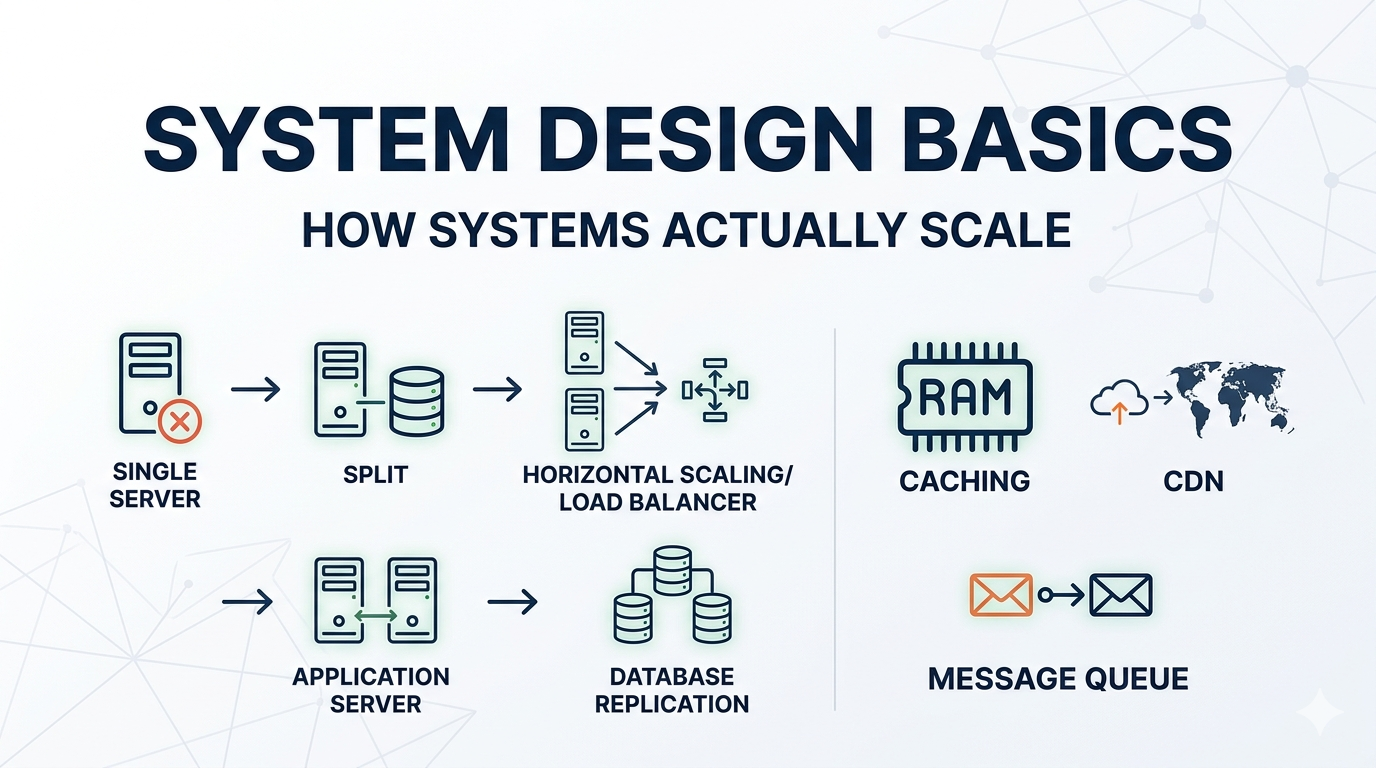
대부분의 시스템은 분산된 상태로 시작하지 않습니다. 간단하게 시작하고 규모가 커짐에 따라 진화합니다.
1. 단일 서버
모든 것이 한 대의 머신에서 실행됩니다:
- 애플리케이션
- 데이터베이스
구축은 쉽지만, 깨지기 쉽습니다.
2. 애플리케이션과 데이터베이스 분리
데이터베이스를 별도의 서버로 옮깁니다.
장점
- 성능 향상
- 독립적인 확장 가능
3. 수평 확장
여러 대의 애플리케이션 서버를 추가합니다. 이제 시스템은 더 많은 트래픽을 처리할 수 있습니다.
문제점
사용자는 어떻게 올바른 서버에 접근할까요?
4. 로드 밸런서
들어오는 요청을 서버들에 고르게 분배합니다.
장점
- 과부하 방지
- 가용성 향상
5. 데이터베이스 복제
- 기본 데이터베이스가 쓰기 작업을 담당
- 복제본이 읽기 작업을 담당
장점
- 기본 데이터베이스에 대한 부하 감소
- 읽기 성능 향상
6. 캐싱
Redis 또는 인‑메모리 캐시를 사용합니다.
저장 대상
- 자주 접근되는 데이터
- 세션 데이터
장점
- 응답 속도 향상
- 데이터베이스 쿼리 감소
7. CDN
정적 파일을 사용자와 가까운 위치에서 제공합니다.
장점
- 지연 시간 감소
- 백엔드 부하 감소
8. 메시지 큐
비동기 작업을 위해 큐를 사용합니다. 예시:
- 이메일
- 알림
- 백그라운드 작업
장점
- 시스템 구성 요소 간 결합도 감소
- 신뢰성 향상
9. 데이터베이스 샤딩
데이터를 여러 데이터베이스에 분산합니다.
장점
- 대규모 처리 가능
트레이드‑오프
- 복잡성 증가
10. 모니터링
다음 항목을 추적합니다:
- 지연 시간
- 오류
- 트래픽
모니터링 없이는 눈이 먼 상태와 같습니다.
핵심 아이디어
시스템은 처음부터 규모에 맞게 설계되지 않습니다. 병목 현상이 나타날 때마다 점진적으로 진화합니다.