새로운 SemiAnalysis InferenceX 데이터, NVIDIA Blackwell Ultra가 Agentic AI에 대해 최대 50배 향상된 성능과 35배 낮은 비용을 제공
I’m happy to translate the article for you, but I’ll need the text you’d like translated. Could you please paste the content (excluding the source line you already provided) here? Once I have the text, I’ll keep the source link at the top unchanged and translate the rest into Korean while preserving the original formatting.
Source: https://blogs.nvidia.com/blog/inference-open-source-models-blackwell-reduce-cost-per-token
NVIDIA Blackwell Ultra: 에이전트형 AI와 코딩 어시스턴트 가속화
NVIDIA Blackwell 플랫폼은 이미 Baseten, DeepInfra, Fireworks AI, Together AI와 같은 주요 추론 제공업체들에 널리 채택되어 토큰당 비용을 최대 10배까지 절감하고 있습니다(source).
이제 NVIDIA Blackwell Ultra 플랫폼이 그 모멘텀을 에이전트형 AI로 확장합니다.
왜 에이전트형 AI와 코딩 어시스턴트가 중요한가
- 폭발적인 성장: 소프트웨어 프로그래밍 관련 AI 쿼리가 전체 AI 트래픽의 **11 %에서 ~50 %**로 증가했습니다(지난 해 기준) (source).
- 이러한 워크로드는 다음을 요구합니다:
- 낮은 지연 시간: 다단계 워크플로우 전반에 걸친 실시간 응답성.
- 긴 컨텍스트 윈도우: 전체 코드베이스를 대상으로 추론하기 위해.
성능 혁신
SemiAnalysis InferenceX의 최신 데이터가 NVIDIA의 엔드‑투‑엔드 최적화 효과를 보여줍니다:
| Metric | NVIDIA Blackwell Ultra (GB300 NVL72) | NVIDIA Hopper (baseline) |
|---|---|---|
| Throughput per megawatt | ↑ 50× | — |
| Cost per token | ↓ 35× (vs. Hopper) | — |
NVIDIA가 이러한 향상을 달성하는 방법
- 칩‑레벨 혁신: 차세대 Blackwell Ultra 실리콘.
- 시스템 아키텍처: 최적화된 GB300 NVL72 구성.
- 소프트웨어 스택: 고급 드라이버, 라이브러리 및 런타임 최적화.
이러한 공동 설계 노력은 자율 코딩 에이전트부터 인터랙티브 어시스턴트에 이르기까지 AI 워크로드를 가속화하고, 대규모 운영 비용을 크게 절감합니다.

GB300 NVL72 — 저지연 워크로드에서 최대 50배 향상된 성능 제공
최근 Signal65 의 분석에 따르면, NVIDIA GB200 NVL72는 극한의 하드웨어‑소프트웨어 공동 설계 덕분에 와트당 토큰 수가 10배 이상 증가했으며, 이는 NVIDIA Hopper 플랫폼 대비 토큰당 비용이 약 1/10 수준에 해당합니다. 이러한 이점은 기반 스택이 성숙해짐에 따라 계속해서 커지고 있습니다.
TensorRT‑LLM, Dynamo, Mooncake, SGLang 팀의 지속적인 최적화는 모든 지연 목표에서 mixture‑of‑experts (MoE) inference 에 대한 Blackwell NVL72 처리량을 더욱 끌어올립니다. 예를 들어, 최근 TensorRT‑LLM 개선으로 GB200에서 저지연 워크로드에 대해 최대 5배 향상된 성능을 달성했으며, 이는 불과 4개월 전과 비교한 결과입니다.
주요 소프트웨어 진보
- 고성능 GPU 커널 – 효율성과 저지연을 위해 튜닝되어 Blackwell의 방대한 연산 능력을 최대한 활용합니다.
- NVIDIA NVLink 대칭 메모리 – GPU 간 직접 메모리 접근을 가능하게 하여 통신 오버헤드를 감소시킵니다.
- 프로그램 종속적 런치 – 이전 커널이 종료되기 전에 다음 커널의 설정 단계를 시작하여 대기 시간을 최소화합니다.
소프트웨어에서 하드웨어로: GB300 NVL72
이러한 소프트웨어 개선을 바탕으로, Blackwell Ultra GPU 를 탑재한 GB300 NVL72는 Hopper 플랫폼 대비 약 50배에 달하는 메가와트당 처리량을 구현합니다. 이는 경제성 측면에서 크게 개선된 것을 의미합니다:
- 저지연, 에이전트형 애플리케이션 에서 토큰당 비용을 최대 35배 낮출 수 있습니다.
- 전체 지연 범위에 걸쳐 일관된 비용 절감 효과를 제공합니다.
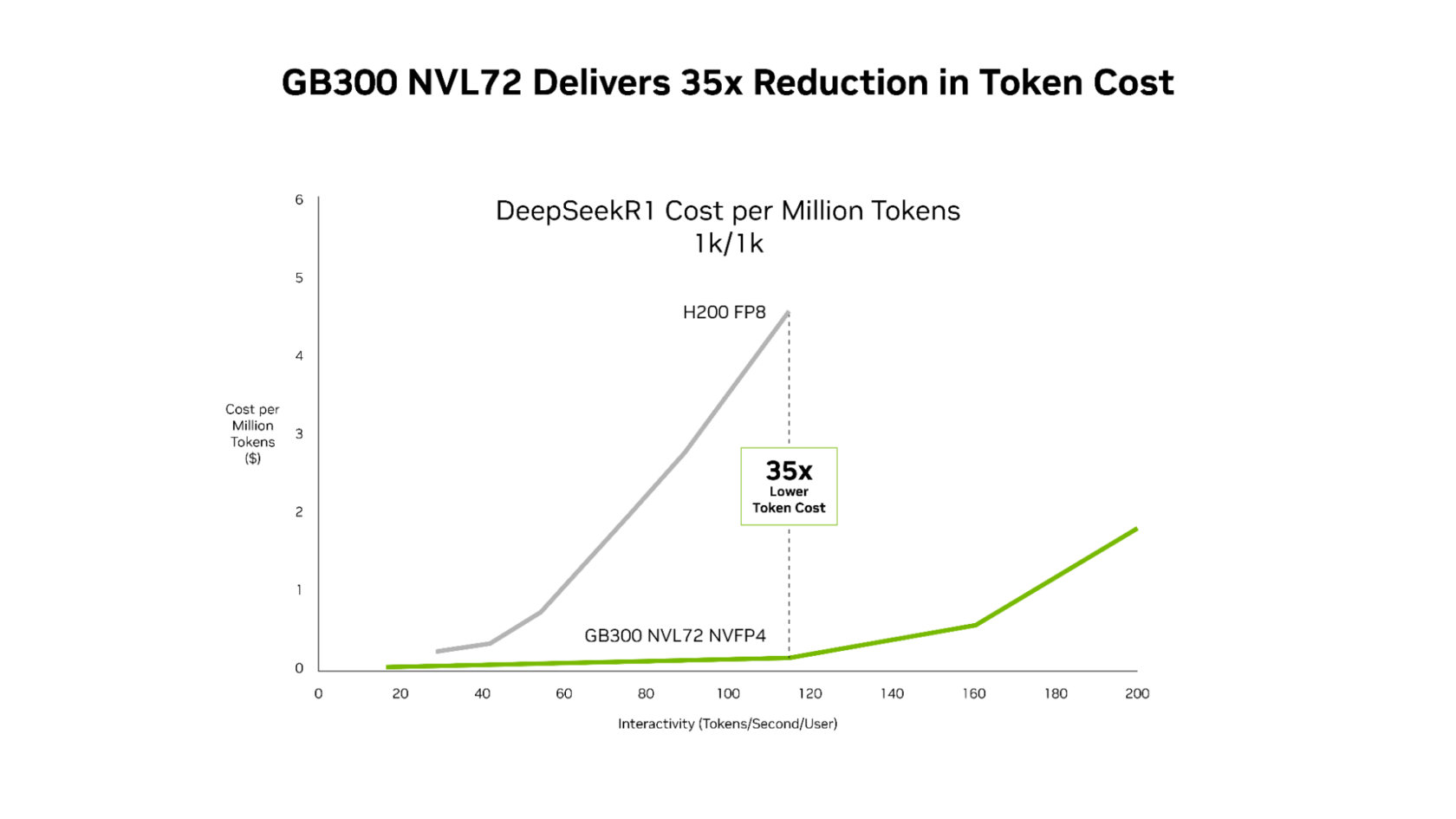
에이전트형 코딩 및 인터랙티브 어시스턴트 워크로드—여러 단계의 워크플로우에서 매밀리초가 누적되는 경우—에 있어, 이러한 끊임없는 소프트웨어 최적화와 차세대 하드웨어의 결합은 AI 플랫폼이 훨씬 더 많은 사용자에게 실시간 인터랙티브 경험을 확장할 수 있도록 합니다.
Source:
GB300 NVL72 — 장기 컨텍스트 워크로드를 위한 뛰어난 경제성 제공
GB200 NVL72와 GB300 NVL72 모두 초저지연을 제공하지만, GB300 NVL72의 장점은 장기 컨텍스트 시나리오에서 가장 두드러집니다. 128 k‑토큰 입력 및 8 k‑토큰 출력과 같은 워크로드—예를 들어 전체 코드베이스를 대상으로 추론하는 AI 코딩 어시스턴트—에서는 GB300 NVL72가 GB200 NVL72에 비해 토큰당 비용을 최대 1.5배 낮추게 됩니다.
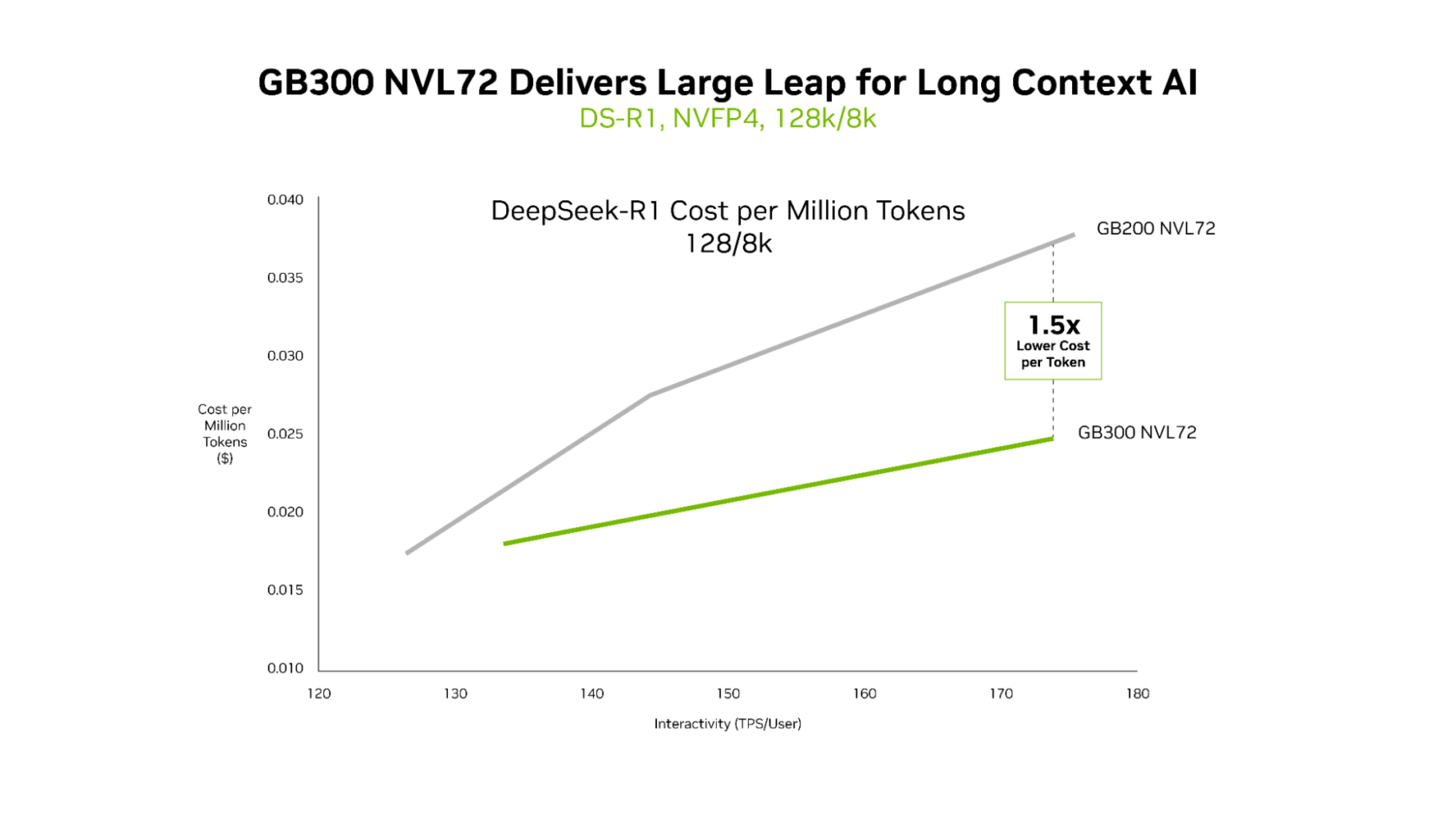
GB300 NVL72가 장기 컨텍스트 워크로드에서 뛰어난 이유
- 더 큰 컨텍스트 윈도우 – 에이전트가 더 많은 코드를 읽을수록 코드베이스에 대한 이해도가 깊어지지만, 그만큼 더 많은 연산이 필요합니다.
- 높은 연산 성능 – Blackwell Ultra는 이전 세대에 비해 NVFP4 연산이 1.5배 더 강력합니다.
- 빠른 어텐션 처리 – 어텐션 연산이 2배 빠르게 수행되어 전체 코드베이스를 효율적으로 처리할 수 있습니다.
이러한 개선점 덕분에 GB300 NVL72는 저지연·장기 컨텍스트 AI 애플리케이션에 최적의 선택이 됩니다.
에이전트 AI를 위한 인프라
주요 클라우드 제공업체와 AI 혁신 기업들은 이미 NVIDIA GB200 NVL72를 대규모로 배포했으며, 현재 GB300 NVL72를 프로덕션에 롤아웃하고 있습니다.
- Microsoft – Azure delivers the first large‑scale cluster with NVIDIA GB300 NVL72 for OpenAI workloads
- CoreWeave – Production‑ready GB300 NVL72 instances for enterprise AI (6× performance gain on DeepSeek‑R1)
- Oracle Cloud Infrastructure (OCI) – Supercluster with NVIDIA Blackwell‑dedicated alloy
이들 제공업체는 에이전트 코딩 및 코딩 어시스턴트와 같은 저지연·장기 컨텍스트 워크로드에 GB300 NVL72를 활용하고 있습니다. 토큰 비용을 절감함으로써 GB300 NVL72는 실시간으로 방대한 코드베이스를 추론할 수 있는 새로운 유형의 애플리케이션을 가능하게 합니다.
“추론이 AI 생산의 중심으로 이동함에 따라 장기 컨텍스트 성능과 토큰 효율성이 핵심이 됩니다.”라고 CoreWeave 엔지니어링 수석 부사장 Chen Goldberg가 말했습니다.
“Grace Blackwell NVL72는 그 과제를 직접 해결하며, CoreWeave의 AI 클라우드—CKS와 SUNK를 포함—는 GB300 시스템의 이점을 GB200의 성공 위에 구축하여 예측 가능한 성능과 비용 효율성을 제공하도록 설계되었습니다. 그 결과 토큰 경제성이 향상되고 대규모 워크로드를 실행하는 고객에게 보다 활용 가능한 추론을 제공하게 됩니다.”
NVIDIA Vera Rubin NVL72가 차세대 성능을 제공
NVIDIA Blackwell 시스템을 대규모로 배포하면서 지속적인 소프트웨어 최적화를 통해 설치 기반 전반에 걸쳐 추가적인 성능 및 비용 개선이 계속해서 이루어지고 있습니다.
앞으로는 NVIDIA Rubin 플랫폼—여섯 개의 새로운 칩을 결합해 하나의 AI 슈퍼컴퓨터를 만드는 플랫폼—이 또 한 번의 대규모 성능 도약을 제공할 예정입니다:
- MoE 추론: Blackwell 대비 메가와트당 최대 10× 높은 처리량을 달성하여 백만 토큰당 비용이 1/10 수준으로 감소합니다.
- Frontier‑AI 학습: 대형 MoE 모델을 Blackwell 대비 GPU 수를 1/4만 사용하여 학습할 수 있습니다.
자세히 보기:
- Vera Rubin NVL72 시스템 – Rubin 플랫폼을 기반으로 구축된 차세대 AI 슈퍼컴퓨터.