CoreWeave의 AI 클라우드 플랫폼에서 NVIDIA H100 GPU가 기록적인 Graph500 실행을 달성한 방법
Source: NVIDIA AI Blog
기록적인 Graph500 벤치마크
대규모 그래프 처리를 위한 세계 최고 성능 시스템이 상용 클러스터 위에 구축되었습니다.
NVIDIA는 지난달 410 조 개의 traversed edges per second (TEPS) 라는 기록적인 벤치마크 결과를 **발표**했으며, 31번째 Graph500 breadth‑first search (BFS) 리스트에서 1위를 차지했습니다.
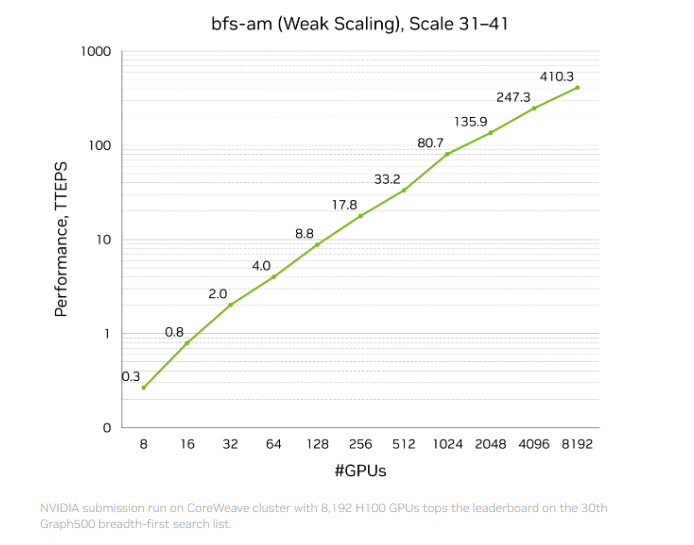
이 실행은 달라스에 위치한 CoreWeave 데이터 센터에서 운영되는 가속 컴퓨팅 클러스터에서 수행되었으며, 8,192개의 NVIDIA H100 GPU를 사용해 2.2 조 정점과 35 조 엣지를 가진 그래프를 처리했습니다. 이 성능은 리스트에 있는 유사 솔루션보다 두 배 이상 뛰어나며, 국가 연구소에서 운영되는 시스템도 포함됩니다.
비교를 위해, 지구상의 모든 사람이 각각 150명의 친구를 가진다면, 그 사회 그래프는 약 1.2 조 엣지를 포함하게 됩니다. NVIDIA‑CoreWeave 시스템은 이러한 모든 관계를 대략 3밀리초 안에 탐색할 수 있습니다.
이 돌파구는 단순히 속도만이 아니라 효율성에서도 두드러집니다. 상위 10위 안에 든 다른 엔트리는 약 9,000 노드를 사용했지만, 우승 실행은 1,000 노드 조금 넘는 규모만으로 가격 대비 3배 더 나은 성능을 제공했습니다.
NVIDIA는 CUDA 플랫폼, Spectrum‑X 네트워킹, H100 GPU, 그리고 새로운 active‑messaging 라이브러리를 포함한 전체 스택 컴퓨트, 네트워킹, 소프트웨어 기술을 활용해 하드웨어 풋프린트를 최소화하면서 성능을 극대화했습니다. 이는 NVIDIA 컴퓨팅 플랫폼이 세계 최대 규모의 희소하고 불규칙한 워크로드는 물론 AI 학습과 같은 밀집 워크로드까지 가속화할 수 있음을 보여줍니다.
대규모 그래프가 작동하는 방식
그래프는 현대 기술의 근본적인 정보 구조입니다. 소셜 네트워크부터 금융 애플리케이션까지, 방대한 웹에서 정보 조각들 간의 관계를 포착합니다.
예시: LinkedIn에서 사용자의 프로필은 **정점(vertex)**이며, 다른 사용자와의 연결은 **엣지(edge)**입니다. 일부 사용자는 몇 개의 연결만 가지고, 다른 사용자는 수만 개의 연결을 가지고 있어 가변적인 밀도를 만들어 그래프가 **희소하고 불규칙(sparse and irregular)**하게 됩니다. 이미지나 언어 모델처럼 구조화되고 밀집된 데이터와 달리, 그래프는 예측할 수 없습니다.
Graph500 BFS 벤치마크는 시스템이 이러한 불규칙성을 대규모로 탐색할 수 있는 능력을 측정합니다. BFS는 모든 정점과 엣지를 순회하는 속도를 평가하며, 높은 TEPS 점수는 뛰어난 인터커넥트, 메모리 대역폭, 그리고 시스템 역량을 활용할 수 있는 소프트웨어를 의미합니다. 본질적으로 시스템이 서로 다른 정보를 얼마나 빠르게 “생각”하고 연관 지을 수 있는지를 나타냅니다.
현재 그래프 처리 기술
GPU는 AI 학습과 같은 밀집 워크로드 가속에 뛰어나지만, 가장 큰 규모의 희소 선형대수 및 그래프 워크로드는 전통적으로 CPU가 담당해 왔습니다.
그래프를 처리할 때 CPU는 컴퓨트 노드 간에 데이터를 이동시킵니다. 그래프가 수조 개의 엣지로 확장될수록 이러한 지속적인 이동은 병목 현상과 통신 혼잡을 초래합니다.
개발자는 active messages와 같은 소프트웨어 기법으로 이를 완화합니다. 이는 작은, 집계 가능한 메시지를 전송해 그래프 데이터를 현장에서 처리함으로써 네트워크 효율성을 높입니다. 하지만 active messaging은 원래 CPU용으로 설계되었으며 CPU 처리량과 연산 능력에 제한을 받습니다.
GPU를 위한 그래프 처리 재설계
BFS 실행을 가속하기 위해 NVIDIA는 데이터 이동을 재구상한 전체 스택 GPU‑전용 솔루션을 설계했습니다.
- **InfiniBand GPUDirect Async (IBGDA)**와 NVSHMEM 병렬 프로그래밍 인터페이스 위에 구축된 맞춤형 소프트웨어 프레임워크는 GPU‑to‑GPU active messages를 가능하게 합니다.
- IBGDA를 사용하면 GPU가 InfiniBand NIC와 직접 통신할 수 있어 수십만 개의 GPU 스레드가 동시에 active messages를 전송할 수 있습니다—CPU에서 가능한 수백 개 스레드에 비해 훨씬 큰 규모입니다.
- 이제 active messaging은 완전히 GPU에서 실행되어 CPU를 우회하고, NVIDIA H100 GPU의 방대한 병렬성 및 메모리 대역폭을 활용해 메시지 전송, 이동, 처리를 수행합니다.
NVIDIA 파트너 CoreWeave의 안정적이고 고성능 인프라 위에서 이 오케스트레이션은 유사 실행 대비 성능을 두 배로 끌어올리면서 하드웨어와 비용을 극히 적게 사용했습니다.
새로운 워크로드 가속
이 돌파구는 고성능 컴퓨팅(HPC)에 막대한 영향을 미칩니다. 유체 역학, 기상 예보, 사이버 보안 등 분야는 대규모 그래프와 유사한 희소 데이터 구조와 통신 패턴에 의존합니다.
수십 년 동안 이러한 분야는 데이터가 수십억에서 수조 개 엣지로 증가함에도 불구하고 가장 큰 규모에서는 CPU에 묶여 있었습니다. NVIDIA의 우승 Graph500 결과와 다른 상위 10위 엔트리 두 개는 대규모 HPC에 GPU 중심 접근법이 가능함을 입증합니다.
NVIDIA의 컴퓨팅, 네트워킹, 소프트웨어 전 스택 오케스트레이션을 통해 개발자는 NVSHMEM과 IBGDA와 같은 기술을 활용해 가장 큰 HPC 애플리케이션을 효율적으로 확장할 수 있게 되었으며, 상용 인프라에서도 슈퍼컴퓨팅 성능을 구현할 수 있습니다.