NVIDIA가 산업 혁명을 구동하는 3가지 방법
Source: NVIDIA AI Blog
NVIDIA 가속 컴퓨팅 플랫폼은 한때 CPU가 장악하던 슈퍼컴퓨팅 벤치마크를 선도하며 전 세계 AI, 과학, 비즈니스 및 컴퓨팅 효율성을 가능하게 하고 있습니다.
Moore’s Law는 한계에 다다랐고, 병렬 처리가 앞으로의 방향입니다. 이러한 진화와 함께 NVIDIA GPU 플랫폼은 이제 차세대 추천 시스템, 대형 언어 모델(LLM)부터 AI 에이전트에 이르기까지 모든 분야에 적용되는 세 가지 스케일링 법칙—프리트레이닝, 포스트‑트레이닝, 테스트‑타임 컴퓨트—을 구현할 수 있는 독특한 위치에 있습니다.
CPU‑to‑GPU 전환: 컴퓨팅의 역사적 변곡점
SC25에서 NVIDIA 창업자이자 CEO인 Jensen Huang은 변화하는 풍경을 강조했습니다. TOP500 슈퍼컴퓨터 목록 중 TOP100에 해당하는 시스템 중 85 % 이상이 GPU를 사용하고 있습니다. 이 전환은 CPU의 직렬 처리 패러다임에서 대규모 병렬 가속 아키텍처로의 역사적 변화를 의미합니다.
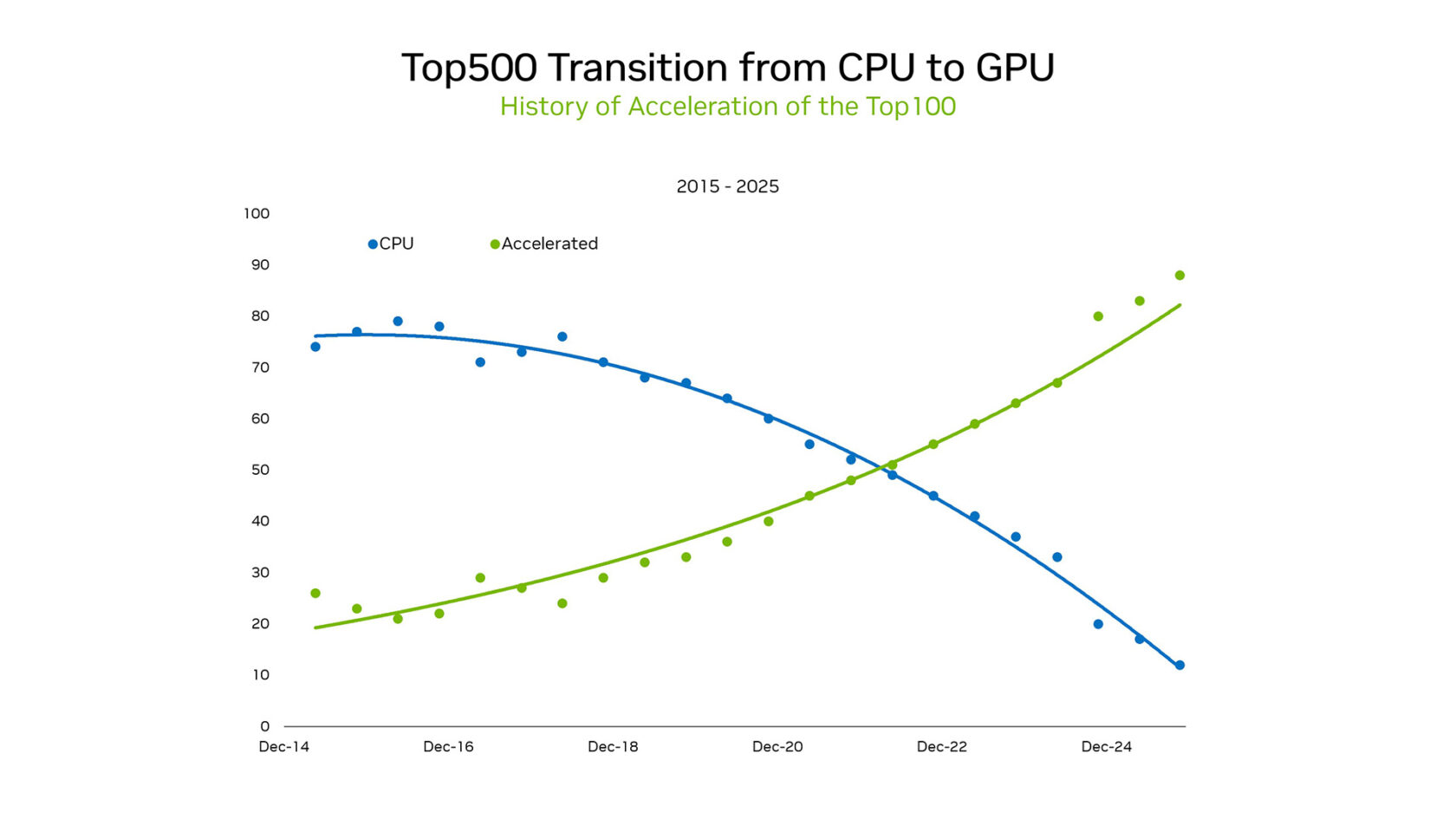
2012년 이전에 머신러닝은 프로그래밍된 논리에 기반했습니다. 통계 모델은 CPU에서 하드코딩된 규칙 집합으로 효율적으로 실행되었습니다. 그러나 게임용 GPU에서 AlexNet이 실행되어 이미지 분류를 예시로부터 학습할 수 있음을 보여주면서 상황이 바뀌었습니다. GPU 기반 병렬 처리는 새로운 컴퓨팅 물결을 일으켰고, 에너지 요구량이 감당되지 않는 수준에 이르지 않으면서 엑사스케일을 실현 가능하게 만들었습니다.
세계에서 가장 에너지 효율이 높은 슈퍼컴퓨터를 순위화한 Green500의 최신 결과는 GPU와 CPU 간의 차이를 명확히 보여줍니다. 상위 5개 시스템 모두 NVIDIA GPU였으며 평균 70.1 gigaflops per watt를 달성한 반면, CPU 전용 시스템은 평균 15.5 flops per watt에 불과했습니다. 4.5배 차이는 GPU 전환이 가져오는 총소유비용(TCO)상의 거대한 이점을 강조합니다.
연구자들은 이제 트릴리언 파라미터 모델을 학습하고, 핵융합 반응기를 시뮬레이션하며, 약물 발견을 가속화하는 등 CPU만으로는 도달할 수 없던 규모를 구현할 수 있게 되었습니다.
CPU와 GPU의 차이를 또다시 입증한 지표는 NVIDIA의 Graph500 결과입니다. NVIDIA는 8,192개의 H100 GPU를 사용해 2.2 trillion 정점과 35 trillion 엣지를 가진 그래프를 처리하며 410 trillion traversed edges per second라는 사상 최고 기록을 세웠습니다. 동일한 작업을 수행하려면 약 150,000대의 CPU가 필요했으며, 이는 하드웨어 풋프린트 감소가 얼마나 큰지를 보여줍니다.
NVIDIA는 SC25에서 AI 슈퍼컴퓨팅 플랫폼이 GPU뿐만 아니라 네트워킹, CUDA 라이브러리, 메모리, 스토리지 및 오케스트레이션까지 공동 설계된 풀스택 솔루션임을 강조했습니다.

CUDA 덕분에 NVIDIA는 풀스택 플랫폼을 제공합니다. CUDA‑X 생태계의 오픈소스 라이브러리와 프레임워크는 큰 속도 향상을 이끌어냅니다. Snowflake는 최근 NVIDIA A10 GPU 통합을 발표해 데이터 사이언스 워크플로를 대폭 강화했습니다. Snowflake ML은 이제 NVIDIA cuML 및 cuDF 라이브러리를 사전 설치하여 인기 있는 ML 알고리즘을 가속합니다.
이 네이티브 통합을 통해 Snowflake 사용자는 코드 변경 없이도 모델 개발 주기를 가속화할 수 있습니다. NVIDIA 벤치마크 결과는 CPU 대비 NVIDIA A10 GPU에서 Random Forest는 5배 빠르고, HDBSCAN은 200배까지 가속된다고 보여줍니다.
현 시점에서 GPU는 효율성 수학의 논리적 결과이자 새로운 패러다임을 촉진하는 촉매제입니다. 하지만 실제 마법이 일어나는 곳은 CUDA‑X와 수많은 오픈소스 소프트웨어 라이브러리·프레임워크입니다.

에너지 효율성을 위한 요구에서 시작된 이 움직임은 이제 과학 플랫폼으로 성장했습니다: 대규모 시뮬레이션과 AI가 결합된 형태입니다. TOP100에서 NVIDIA GPU가 차지하는 리더십은 이러한 궤적을 입증할 뿐 아니라, 다음 단계—모든 분야에서의 돌파구—를 예고합니다.
AI 차세대 프론티어를 이끄는 세 가지 스케일링 법칙
CPU에서 GPU로의 전환은 단순히 슈퍼컴퓨팅의 이정표가 아닙니다. 이는 AI 워크플로우의 로드맵을 제시하는 세 가지 스케일링 법칙—프리트레이닝, 포스트‑트레이닝, 테스트‑타임 스케일링—의 기반이 됩니다.
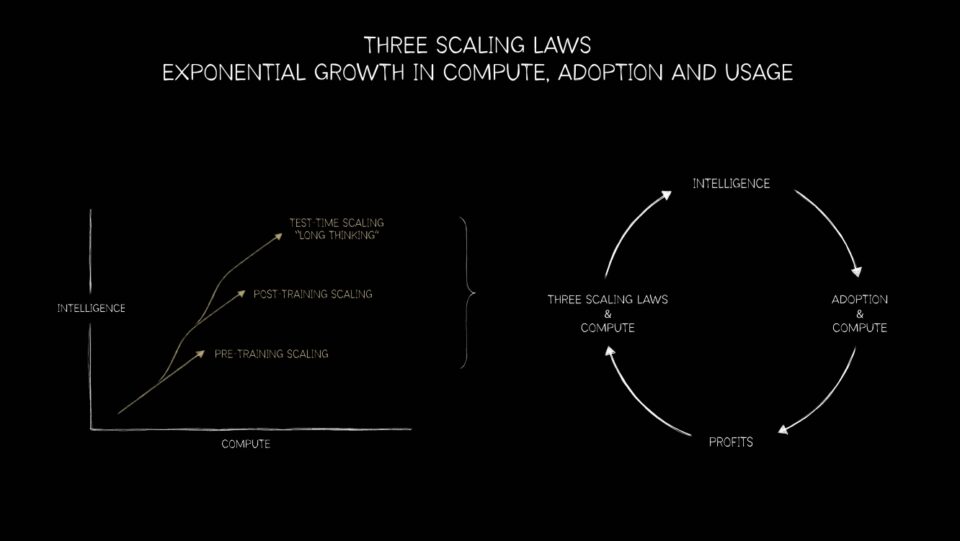
프리트레이닝 스케일링
프리트레이닝 스케일링은 업계 최초로 적용된 법칙이었습니다. 연구자들은 데이터셋, 파라미터 수, 컴퓨트가 증가함에 따라 모델 성능이 예측 가능하게 향상된다는 사실을 발견했습니다. 데이터나 파라미터를 두 배로 늘리면 정확도와 다재다능성이 크게 도약했습니다.
최신 MLPerf Training 벤치마크에서 NVIDIA 플랫폼은 모든 테스트에서 최고 성능을 기록했으며, 유일하게 모든 테스트에 제출한 플랫폼이었습니다. GPU가 없었다면 “큰 것이 좋은” 시대의 AI 연구는 전력 예산과 시간 제약에 가로막혔을 것입니다.
포스트‑트레이닝 스케일링
포스트‑트레이닝 스케일링은 이야기를 확장합니다. 기본 모델이 구축된 뒤에는 산업, 언어, 안전 제약 등에 맞춰 미세 조정이 필요합니다. 인간 피드백을 활용한 강화 학습, 프루닝, 디스틸레이션 등은 때때로 프리트레이닝만큼이나 방대한 추가 컴퓨트를 요구합니다. GPU는 이러한 지속적인 파인‑튜닝과 도메인 적응을 가능하게 하는 동력을 제공합니다.
테스트‑타임 스케일링
가장 최신 법칙인 테스트‑타임 스케일링은 가장 변혁적인 영향을 미칠 가능성이 있습니다. Mixture‑of‑experts 아키텍처를 활용한 현대 모델은 실시간으로 여러 솔루션을 사고, 계획하고 평가할 수 있습니다. 체인‑오브‑쓰루 사고, 생성적 검색, 에이전시 AI 등은 동적이고 재귀적인 컴퓨트를 요구하며, 이는 종종 프리트레이닝 요구량을 초과합니다. 이 단계는 데이터 센터부터 엣지 디바이스까지 추론 인프라에 대한 기하급수적 수요를 촉발할 것입니다.
이 세 가지 법칙은 새로운 AI 워크로드에 GPU가 왜 필수적인지를 설명합니다. 프리트레이닝 스케일링은 GPU를 없어서는 안 될 존재로 만들었습니다.