중국, 미국 GPU 금지 우회해 1.54 엑사플롭스 'LineShine' 슈퍼컴퓨터 구축 — CPU 전용 거인, 화웨이 설계 Armv9 코어 240만 개 탑재
출처: Tom’s Hardware

(이미지 출처: Google)
오늘날 대부분의 선도적인 슈퍼컴퓨터와 AI 클러스터는 일반 목적 작업과 오케스트레이션을 위해 CPU를, 대규모 병렬 연산 워크로드를 위해 AI GPU를 사용해 엑사플롭스급 성능을 달성합니다. 하지만 중국에서는 상황이 다릅니다. 최근 몇 년간 중국은 GPU에 대한 미국의 수출 금지 때문에 충분한 GPU를 확보하지 못해, CPU 전용 슈퍼컴퓨터를 다수 구축하고 AI·HPC 워크로드에 활용하고 있습니다. 예를 들어, 중국 국가슈퍼컴퓨팅센터는 최근 1.54 엑사플롭스급 머신을 20,480개의 Armv9 기반 CPU로 구축했습니다(논문).
LineShine LX2 프로세서
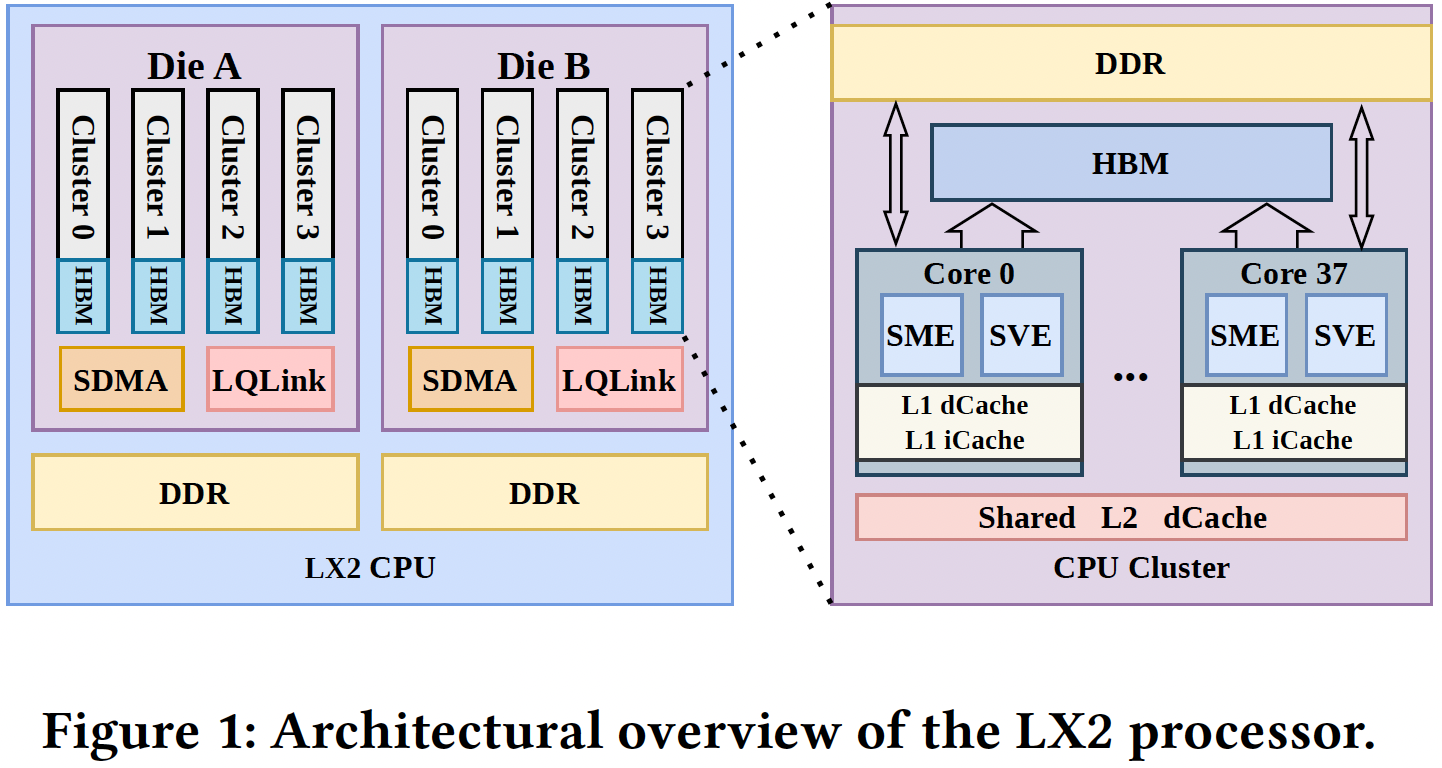 (이미지 출처: 중국 국가슈퍼컴퓨팅센터)
(이미지 출처: 중국 국가슈퍼컴퓨팅센터)
각 LX2 프로세서는 두 개의 컴퓨트 칩렛을 사용하며, 총 304개의 CPU 코어를 8개의 클러스터(클러스터당 38코어)로 구성합니다. 모든 코어는 AI 학습 및 과학 컴퓨팅에 사용되는 벡터·행렬 연산을 가속화하는 **Arm SVE(Scalable Vector Extension)**와 SME(Scalable Matrix Extension) 유닛을 탑재하고 있으며, FP64, FP32, BF16, FP16, INT8 데이터 형식을 지원합니다. 코어당 32 KB L1 명령 캐시와 32 KB L1 데이터 캐시를 갖추고, 각 클러스터는 28.5 MB L2 캐시를 공유합니다.
TH 프리미엄으로 더 깊이 파고들기: AI와 데이터 센터
이 프로세서는 32 GB 온패키지 HBM(초당 최대 4 TB 대역폭)과 최대 256 GB 오프패키지 DDR5 메모리를 결합한 매우 이례적인 메모리 서브시스템을 사용합니다. 유사한 메모리 구성을 사용한 사례로는 Fujitsu의 Arm 기반 A64FX가 있으며, 이는 후가쿠 슈퍼컴퓨터를 구동합니다. 그러나 LX2는 이러한 메모리 서브시스템을 채택한 업계 최초의 Armv9 기반 CPU일 가능성이 높습니다.
각 칩렛은 4개의 HBM 도메인과 4개의 DDR 도메인을 포함하고, 프로세서당 16개의 NUMA 도메인이 존재합니다. HBM 접근은 지역성에 매우 민감한 반면, DDR 메모리 접근은 다이 내부에서 보다 균일하게 이루어지며 클러스터 간에 공유됩니다. 이러한 특성 때문에 개발자는 토폴로지 인식 메모리 배치 및 스케줄링 기법을 설계해야 했으며, 이는 전용 SDMA 엔진이 DDR과 HBM 사이의 데이터를 이동시켜 수행합니다.
성능 면에서 단일 LX2 프로세서는 FP64 60.3 TFLOPS, BF16/FP16 240 TFLOPS, INT8 960 TOPS를 제공합니다. 전통적인 서버 CPU와 달리, 이 아키텍처는 CPU 중심 설계임에도 불구하고 밀집형 AI·행렬 워크로드에 최적화된 것으로 보입니다. 논문에서는 SME 행렬 엔진의 높은 활용률을 유지하려면 커널, 런타임 스케줄링, 캐시 상주 관리, HBM·DDR 계층 간 텐서 배치 등에 대한 광범위한 공동 설계가 필요했다고 언급합니다.
LineShine 슈퍼컴퓨터
LineShine 슈퍼컴퓨터는 20,480개의 컴퓨트 노드로 구성됩니다. 각 노드에는 두 개의 LX2 프로세서가 탑재되며, 각 프로세서는 304개의 CPU 코어를 보유합니다. 따라서 전체 시스템은 40,960개의 LX2 프로세서와 2,451,840개의 CPU 코어를 사용합니다. 슈퍼컴퓨터는 LingQi 고속 네트워크(LQLink) 로 연결되어 노드당 1.6 Tb/s의 전송 속도를 제공합니다.
Tom’s Hardware의 최신 뉴스와 심층 리뷰를 바로 메일함으로 받아보세요.
 (이미지 출처: 중국 국가슈퍼컴퓨팅센터)
(이미지 출처: 중국 국가슈퍼컴퓨팅센터)
이 머신은 BF16 학습 성능 1.54 ExaFLOP/s를 제공하며, 63억 파라미터 규모의 지구 관측 생성 압축 모델을 학습할 때 피크 2.16 ExaFLOP/s에 도달합니다. Nvidia GPU 수백만 개를 사용하는 xAI와 같은 기업은 클러스터의 피크 성능을 공개하지 않으므로 LineShine을 Colossus 등 다른 최첨단 AI 클러스터와 직접 비교하기는 어렵습니다. 다만, xAI의 Colossus는 497.9 ExaFLOPS(추정)라는 피크 성능을 가지고 있다고 알려져 있습니다. 모델 FLOPS 활용률이 약 15% 수준(=LineShine 수준)이라면, 약 75 ExaFLOPS 정도를 제공할 수 있습니다.
이론적인 FP64 피크 성능을 기준으로 보면, 40,960개의 LX2 프로세서는 2.47 ExaFLOPS를 달성할 수 있습니다. 하지만 실제 FP64 처리량은 여러 변수에 크게 좌우되므로 정확히 알 수 없습니다.
장점은 많지만, 한계도 존재합니다
CPU 전용 AI·HPC 슈퍼컴퓨터는 전통적인 CPU+GPU 이종 시스템에 비해 여러 장점을 제공합니다. 특히 AI 학습과 대규모 데이터 수집·전처리·스토리지 연동·시뮬레이션·오케스트레이션을 결합한 복합 과학 작업에 유리합니다.
- 동일 프로세서·메모리 공간 사용 → CPU‑GPU 간 데이터 전송(고비용·고대역폭) 및 복잡한 프로그래밍 모델, GPU 메모리 제한, 가속기 전용 소프트웨어 스택 등의 문제를 회피
- 동질적인 CPU 기반 시스템은 HBM과 대용량 DDR을 결합해 더 큰 일관 메모리 풀을 제공하므로 방대한 과학 데이터셋, 검색 기반 생성, 긴 컨텍스트 윈도우 처리에 유리
- 불규칙 제어 흐름·분산 I/O·통신 집약 파이프라인 등 GPU에 비효율적인 워크로드에 적합한 AI‑for‑Science 애플리케이션에 매력적
- 전통적인 HPC 환경과 자연스럽게 통합 가능 → 시뮬레이션 등 일반 슈퍼컴퓨터 작업 수행이 용이, AI 학습·추론과 HPC를 동시에 필요로 하는 경우에 특히 유용
- 외국 가속기·플랫폼 의존도 감소 → Nvidia GPU와 CUDA 생태계에 대한 의존을 줄일 수 있어 중국 입장에서 전략적으로 중요
하지만 큰 트레이드오프도 존재합니다. CPU 전용 시스템은 전력 효율이 낮고 GPU 기반 슈퍼컴퓨터에 비해 밀집 AI 처리량이 떨어지는 경향이 있습니다. 그래서 업계는 여전히 이종 CPU+GPU 아키텍처에 베팅하고 있습니다.

팔로우* Google 뉴스의 Tom’s Hardware*, 혹은* 선호 소스로 추가*하여 최신 뉴스·분석·리뷰를 피드에서 받아보세요.
Anton Shilov는 Tom’s Hardware의 기고 작가입니다. 그는 지난 수십 년간 CPU·GPU부터 슈퍼컴퓨터, 최신 공정 기술·최첨단 제조 장비, 그리고 하이테크 산업 트렌드에 이르기까지 다양한 주제를 다뤄왔습니다.