생물학적 진화와 정보 획득
Source: Hacker News
몇 주 전, 우리는 경제학자 브라이언 아서가 제시한 기술 진화 시뮬레이션을 살펴보았습니다. 그는 NAND 게이트와 같은 단순한 빌딩 블록에서 시작해, 점점 더 유용한 기존 부품들을 무작위로 결합함으로써 12입력 AND 게이트나 4비트 가산기와 같은 놀라울 정도로 복잡한 회로를 진화시켰습니다. 우리는 이를 검색 문제를 단순화하는 방법으로 분석했습니다. 기존에 작동하는 부품들을 모듈로 사용하고, 이들을 몇 개씩 결합해 더 복잡한 모듈을 만든 뒤, 다시 그 모듈들을 결합함으로써, 탐색 트리의 많은 가능성 없는 가지들을 차단하고, 시뮬레이션이 방대한 가능성 집합 속에서 유용한 기술을 찾아낼 수 있게 하는 것이죠.
실제 인간 기술은 무작위로 부품을 결합해 유용한 것이 나오는 식으로 생성되지 않습니다. 이러한 시뮬레이션에서의 무작위성은 단지 다양한 조건 하에서 새로운 기술을 만들기가 얼마나 쉽거나 어려운지를 보여주기 위한 도구일 뿐입니다. 하지만 생물학적 기술—미생물부터 보라색 고래와 같이 737 항공기만큼 큰 생물까지—도 무작위성에 의해 생성됩니다. 진화는 무작위 돌연변이로 인해 발생하는 유전적 변이를 수확하고, 가장 적합한 개체를 선별해 그들의 유전자를 미래로 전파함으로써, 생물학적 기술을 한 조각씩 구축합니다. 수십억 년에 걸쳐 이 과정은 놀라울 정도로 복잡한 생물학적 시스템을 만들어냅니다.
흥미로운 점은, 생물학적 진화가 아서의 회로 시뮬레이션과 매우 유사한 트릭을 사용한다는 것입니다. 유전 수준에서 모듈성을 활용함으로써, 개체군은 유용한 유전 변이가 개체군 전체에 퍼지는 속도를 높이고, 결과적으로 정보 획득 속도를 높일 수 있습니다. 성적 생식과 수평 유전자 전달과 같은 유전 물질 공유 방식은 본질적으로 이 역할을 수행하는 메커니즘입니다. 이를 간단한 시뮬레이션으로 보여줄 수 있습니다.
가장 단순한 번식 방식은 무성생식으로, 부모가 자신과 동일한 유전자를 가진 자식을 생산합니다. 예를 들어, 단세포 생물은 세포 분열을 통해 두 개 이상의 “자식”으로 나뉘며, 각 자식은 원래 부모와 같은 유전자를 가집니다.
하지만 자식이 반드시 부모와 동일한 복제본이 되는 것은 아닙니다. 분열 과정에서 유전 돌연변이가 발생하면 일부 유전자가 무작위로 바뀌어 약간 다른 유전자를 가진 자식이 태어날 수 있습니다. 경우에 따라 이러한 돌연변이는 항생제 내성과 같은 추가 기능을 제공해 생존 및 번식 확률을 높일 수 있습니다. 이러한 유전자의 적합도 기여 때문에, 시간이 지나면서 유용한 돌연변이는 개체군 내에서 점점 더 흔해집니다.
간단한 시뮬레이션으로 이를 보여줄 수 있습니다. 시뮬레이션에서는 100마리의 개체가 각각 200개의 개별 유전자로 이루어진 게놈을 가지고 시작합니다. 각 유전자는 1(“좋은” 버전) 또는 0(“나쁜” 버전) 중 하나일 수 있습니다. 초기 개체군은 무작위이며, 각 개체는 대략 50:50 비율의 좋은 유전자와 나쁜 유전자를 가집니다. 시뮬레이션의 각 반복에서, 모든 개체는 두 자식을 생산합니다. 자식은 부모의 유전자를 복사하지만, 돌연변이 때문에 각 유전자는 0.2% 확률로 뒤바뀝니다(1→0 또는 0→1). 가장 적합한 100명의 자식(적합도는 각 유전자의 값 합계, 여기서 1이 “좋은” 버전)만이 다음 세대로 선택되고, 이 과정이 반복됩니다. 실제 진화와 비교하면 단순화된 모델인데, 예를 들어 유전자가 독립적으로 적합도에 기여한다고 가정하고, 유전자의 상호작용을 무시합니다. 그럼에도 불구하고 이 모델은 작동 메커니즘을 보여주기에 충분합니다.
시뮬레이션을 실행하면, “좋은” 유전자의 비율이 시간이 지남에 따라 꾸준히 상승합니다. 더 적합한 자손이 덜 적합한 자손을 압도하기 때문이죠. 돌연변이율에 따라 개체군은 최댓값인 200에 도달하거나, 그보다 낮은 수준에서 정체될 수 있습니다.
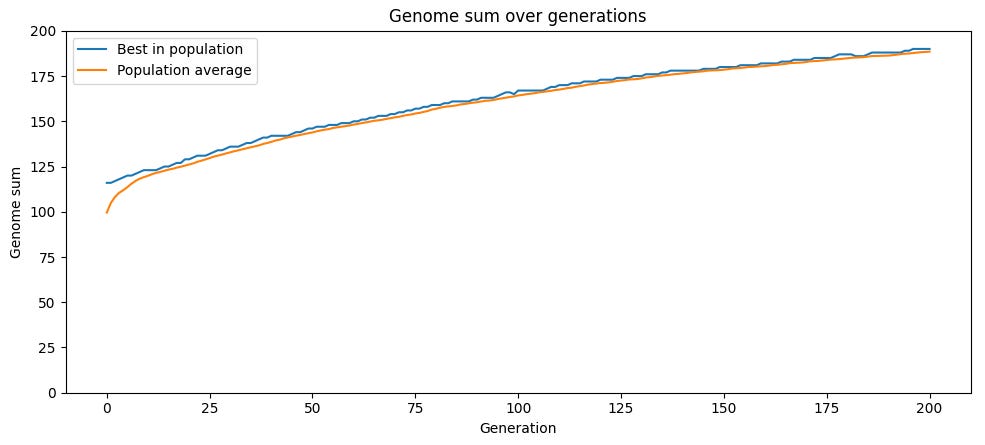
이 전략의 문제점은—단일 부모의 잡음이 섞인 복제본을 생산하고, 유전 변이의 원천을 순전히 무작위 돌연변이에 의존한다는 점—이미 평균 이상의 적합도를 가진 상태에서는 돌연변이가 평균적으로 해로울 가능성이 높다는 것입니다. 게놈에 1이 0보다 많다면, 무작위 변화는 1을 0으로 바꾸는 경우가 0을 1로 바꾸는 경우보다 더 흔합니다. 따라서 평균 이상 적합도를 가진 부모의 자식은 평균적으로 적합도가 낮아집니다.
돌연변이는 무작위이기 때문에 변이는 여전히 존재하고, 일부 자식은 부모보다 높은 적합도를 가질 수 있습니다. 그리고 선택 과정이 매 반복마다 가장 적합하지 않은 개체를 제거하기 때문에, 선택된 자식 집단은 부모보다 평균 적합도가 높아져 시간이 지남에 따라 평균 적합도가 증가합니다. 하지만 돌연변이가 평균 적합도를 낮추는 효과는 이 과정을 끌어내립니다.
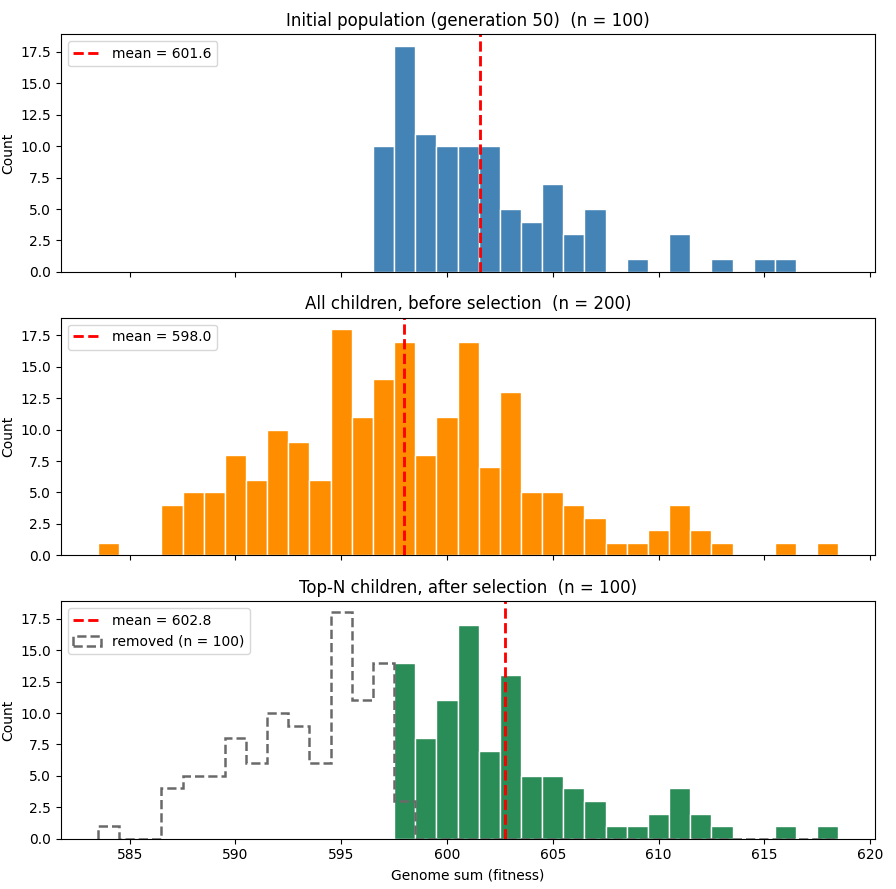
아래 그래프는 약간 다른 파라미터(게놈 길이 1000, 돌연변이율 2%)를 사용한 시뮬레이션 결과를 보여줍니다. 상단 그래프는 50세대에서 개체군 적합도 분포를, 두 번째 그래프는 선택 전 자식들의 적합도 분포를 나타냅니다. 돌연변이 때문에 평균 적합도가 떨어졌지만, 무작위성 덕분에 일부 자식은 높은 적합도를 얻게 됩니다. 마지막 그래프는 상위 절반이 선택된 후의 자식들을 보여줍니다. 평균 적합도가 상승했으며, 초기 개체군보다 약간 높아졌습니다.
이제 다른 번식 전략인 성적 생식을 시뮬레이션해 보겠습니다. 여기서는 자식이 두 부모로부터 유전자를 물려받습니다. 동일한 100마리 개체와 200개의 유전자를 가진 게놈을 사용하지만, 이번에는 개체들을 무작위로 짝지어 각 쌍이 네 자식을 생산합니다. 각 유전자는 50% 확률로 어느 한쪽 부모에게서 물려받게 됩니다. 가장 적합한 100명의 자식을 다음 세대로 선택하고, 반복을 계속합니다. 이 시뮬레이션에서는 돌연변이가 없으므로, 유전적 변이는 전적으로 부모 유전자의 재조합에서 비롯됩니다.
전 시뮬레이션과 마찬가지로 개체군은 점차 최대 적합도에 도달합니다. 하지만 성적 생식은 훨씬 더 빠르게 도달합니다. 무성생식에서는 200세대가 지나야 평균 적합도가 … (이하 생략)