LLM Foundry: the boring stack that makes an LLM actually useful
Source: Dev.to
Introduction
Most AI projects are built backwards. Teams start with the model and only later discover they need a memory system, semantic retrieval, tool use, tests, and a fallback plan for when a provider goes offline.
What is LLM Foundry?
LLM Foundry is the workshop around an LLM — not the model itself. It is the layer that makes a model useful for actual work instead of just looking smart in a demo.
Key Features
- Semantic retrieval backed by embeddings, so memory search is not just keyword matching.
- Multi‑provider support for OpenAI‑compatible endpoints, Anthropic, Hugging Face, and failover bundles.
- Compression + memory so long tasks can be shrunk into a compact working context.
- Agent traces that can be exported into training data.
- Benchmark + harness runs so the system is testable instead of vibes‑based.
Typical Workflow
A useful model stack is not one prompt and a prayer. It usually follows these steps:
- Read the task.
- Recover relevant memory.
- Compress the clutter.
- Ask the model.
- Check the answer.
- Use tools if needed.
- Save traces.
- Benchmark the result.
This is the difference between a chatbot and something you might actually trust on real work.
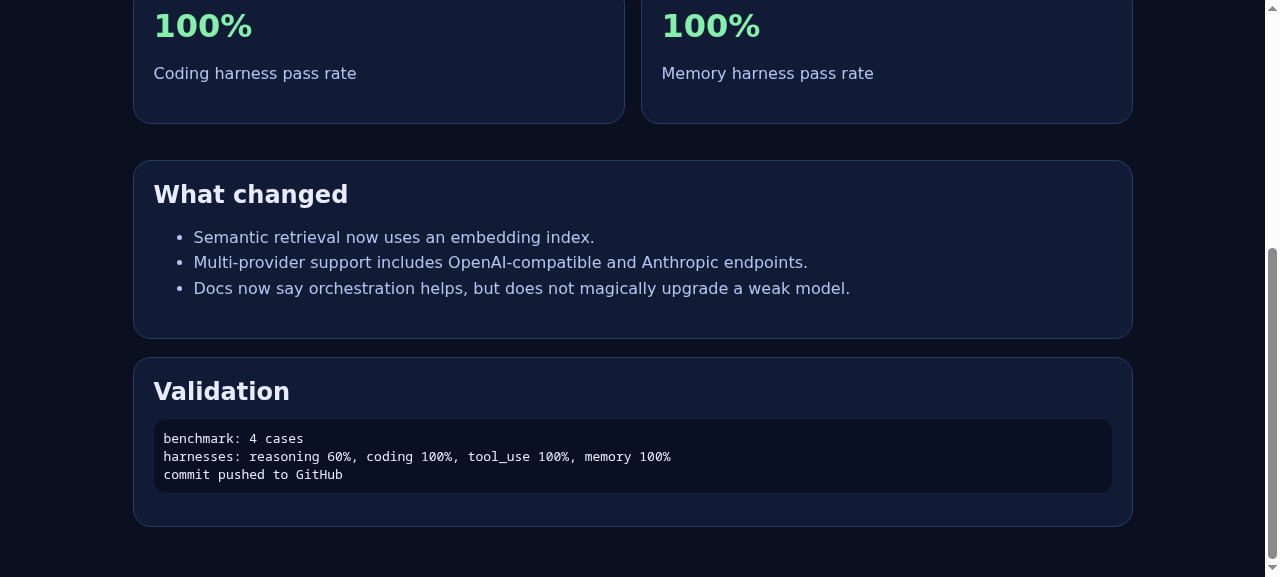
Importance of Orchestration
If a base model is bad at reasoning, orchestration will not magically make it frontier‑grade. You can improve its behavior, reliability, recall, and workflow quality, but you cannot conjure missing intelligence out of nowhere.
What orchestration can do is make a decent model much more useful:
- It sees less irrelevant text.
- It retrieves the right context more often.
- It can call tools instead of guessing.
- It can be checked and scored.
- Its traces can become training data later.
Validation Results
Live report: https://zo.pub/man42/llm-foundry
Screenshots
- Top: https://zo.pub/man42/llm-foundry/top.png
- Mid: https://zo.pub/man42/llm-foundry/mid.png
- Bottom: https://zo.pub/man42/llm-foundry/bottom.png
{kind=link}
{kind=link}
{kind=link}
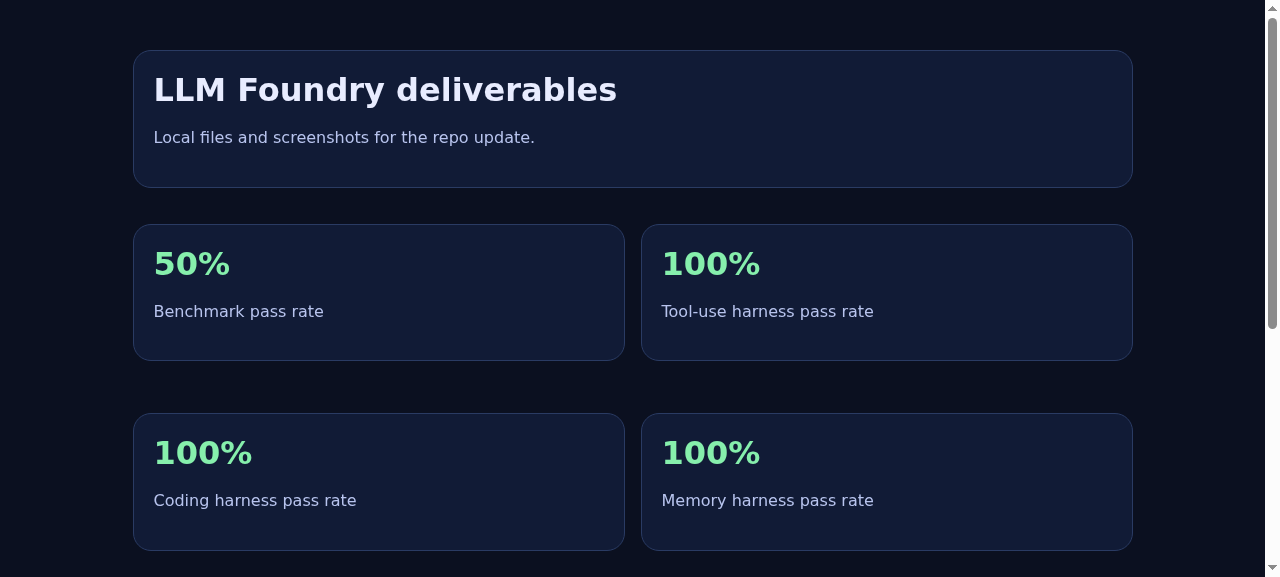
Benchmark Summary
| Metric | Pass Rate |
|---|---|
| Benchmark overall | 50 % |
| Reasoning harness | 60 % |
| Coding harness | 100 % |
| Tool‑use harness | 100 % |
| Memory harness | 100 % |
The benchmark pass rate is not a brag; it is a baseline. The point is that the system is measurable, and therefore improvable.
Memory System Improvements
The retrieval layer is now embedding‑based, allowing the system to look for relevant context semantically rather than by literal word match. This matters when task wording changes but the meaning does not, making it harder for the assistant to miss useful information due to phrasing differences.
Goals and Infrastructure
The goal is not just a “model wrapper” but a practical operating layer for LLM work:
- A model can be local or remote.
- The backend can be OpenAI‑compatible or Anthropic.
- Memory can be compacted and reused.
- Traces can become training data.
- Benchmarks can tell you whether anything improved.
This infrastructure makes a model usable for long jobs, research, and product workflows.
Repository
- GitHub repo: https://github.com/AmSach/llm-foundry
- GitHub profile: https://github.com/AmSach
- Proof pack: https://zo.pub/man42/llm-foundry