GCC vs Clang: Same Instructions, Different Performance (AGU Insight)
Source: Dev.to
Introduction
I noticed something interesting while running a GCC vs Clang benchmark.
- Same code. Same machine.
- Both loops are scalar (no vectorization).
Yet GCC consistently used fewer CPU cycles.
At first, this doesn’t make sense. If both:
- execute roughly the same instructions
- are not vectorised
Why is there a performance gap?
The Missing Piece: It’s Not Just Instructions
Most people focus on:
- instruction count
- vectorization
But in this case, that’s not the full story.
What actually matters more is:
- how address computations are structured
- how instructions are scheduled
- how well latency is hidden
Here is the data:
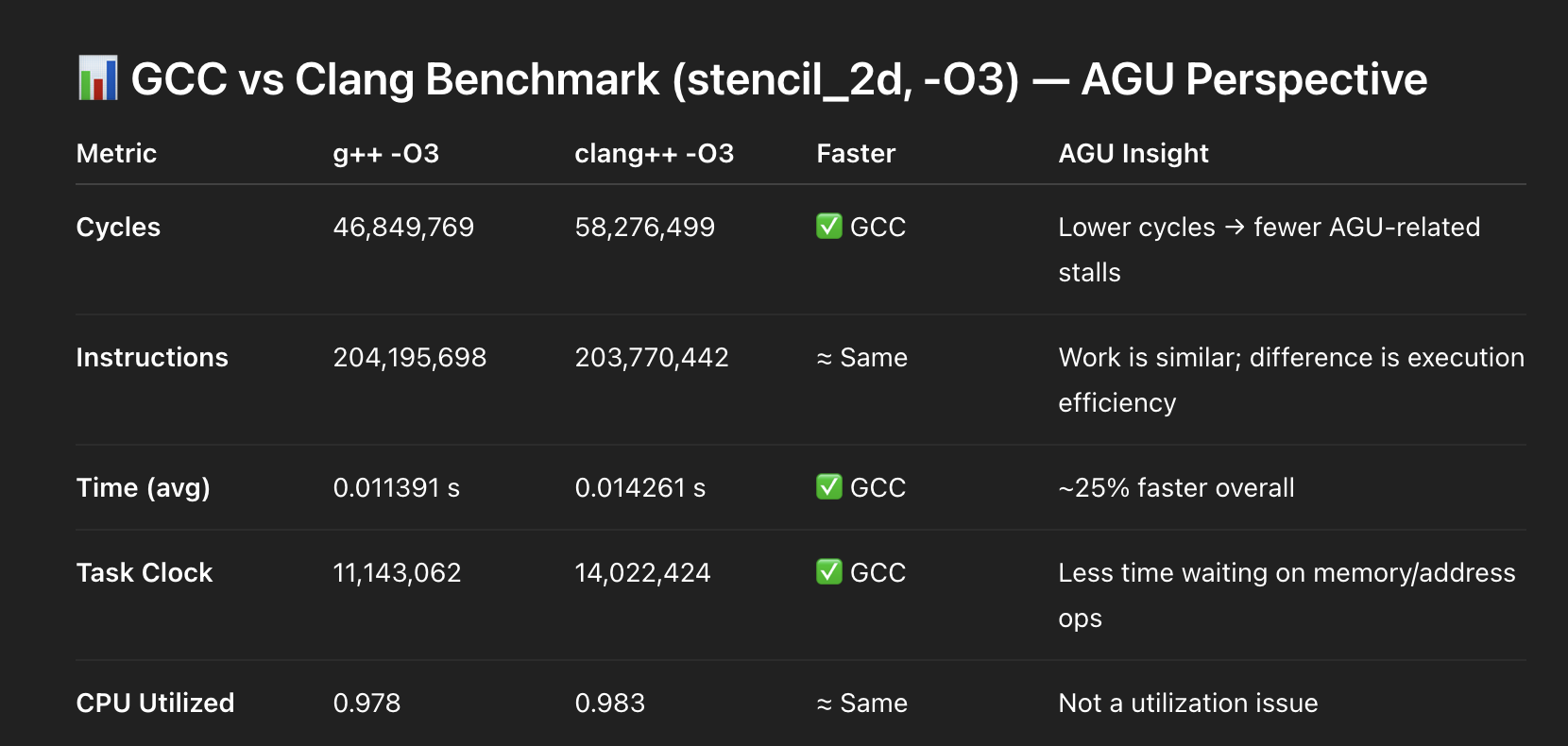
AGU Pressure (Address Generation Units)
On x86 CPUs, memory instructions rely on AGUs (Address Generation Units).
Complex addressing patterns like:
base + index * scale + offset👉 increase AGU pressure
Whereas simpler patterns like:
pointer++👉 are cheaper and easier for the CPU to execute efficiently
What I Observed
GCC
- Generates simpler addressing patterns
- Reduces AGU contention
- Keeps execution more consistent
Clang
- Shows higher AGU pressure
- More stalls
- Less efficient scheduling (in this case)
Key Takeaway
It’s not just about what instructions exist. It’s about how efficiently the compiler feeds the CPU pipeline.
Same instruction count ≠ same performance.
Why This Matters
In tight loops, the following can matter as much as (or more than) vectorization:
- AGU pressure
- Addressing patterns
- Instruction scheduling
Want to Dive Deeper?
Discussion
Have you seen cases where similar assembly and the same instruction count still result in very different performance? I’d love to hear your observations.