플리토, AI 다국어 인식률 개선 위한 아랍어 음성 데이터 수집 프로젝트 착수
Source: VentureSquare
인공지능 데이터 및 솔루션 전문 기업 플리토가 아랍어 음성 데이터 수집 프로젝트를 시작
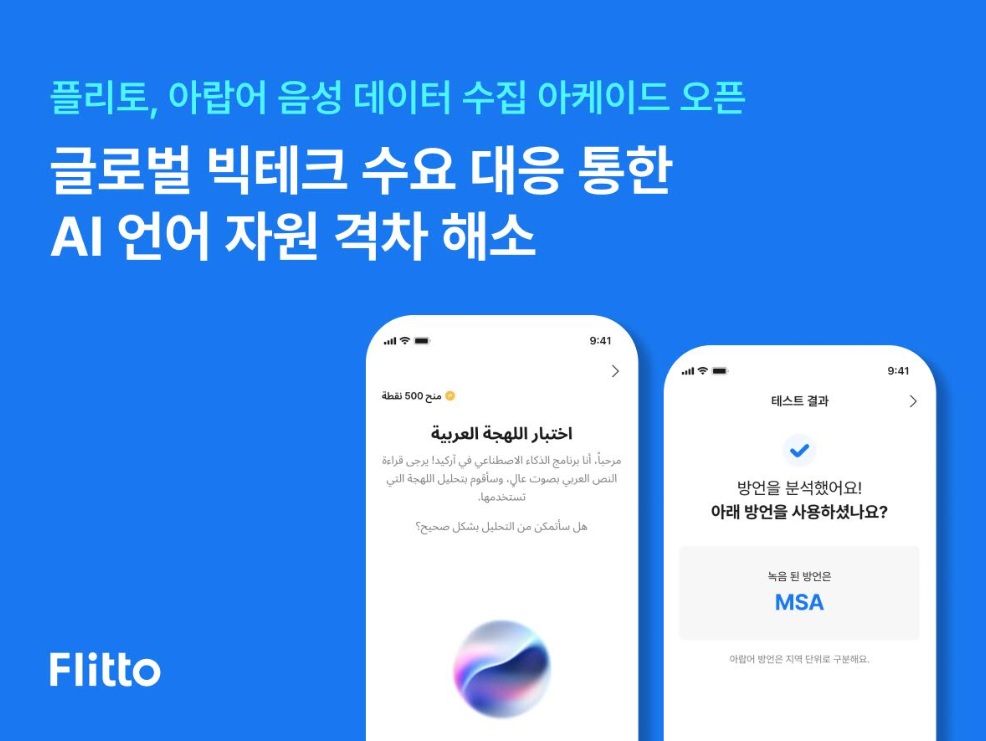
플리토(https://www.flitto.com/portal/ko)는 AI 모델의 다국어 인식률 향상을 위해 고품질 아랍어 음성 데이터를 수집하는 신규 프로젝트를 10일 발표했다.
-
프로젝트 목표
음성인식(STT) 모델에서 상대적으로 낮은 인식률을 보이는 아랍어(표준어 MSA 외 30개 이상 방언)의 성능 개선. -
특징
- 일상 대화에서 표준어와 방언이 혼용되는 코드 스위칭 현상이 빈번해 AI 학습 데이터 구축 난이도가 높음.
- 플리토 모바일 앱에 탑재된 ‘아케이드’ 기능을 활용해 음성 데이터 수집 이벤트 진행.
- 참여자는 제시된 문장을 읽고 녹음 → AI가 방언 유형을 판별.
- 방언 구분이 불확실하면 추가 문장을 제시해 재참여를 유도, 데이터 정확도 향상.
-
배경
글로벌 빅테크 기업을 중심으로 다국어 음성 데이터 수요가 지속적으로 증가하고 있어, 실제 프로젝트 요청뿐 아니라 잠재 수요에 선제적으로 대응하기 위해 추진. -
기대 효과
발화자의 억양·발음·어휘 선택 등 언어적 다양성을 반영한 학습용 데이터 구축 → AI 학습 편향 완화 및 실제 사용 환경에서 높은 인식률 구현.
이정수 플리토 대표
“아랍어는 전 세계 4억 명 이상이 사용하는 주요 언어지만 AI 학습용 데이터는 상대적으로 부족한 저자원 언어입니다. 이번 프로젝트를 통해 실제 사용 맥락을 충실히 반영한 데이터를 구축해 글로벌 AI 모델의 아랍어 인식 품질 향상에 기여하겠습니다.”
- 관련 기사 더 보기
Pluto Launches Project to Collect Arabic Voice Data to Improve AI Multilingual Recognition
Pluto, an artificial‑intelligence data and solutions company, announced on the 10th that it has launched a new project to collect high‑quality Arabic speech data to improve the multilingual recognition rate of AI models.
-
Project goal
Improve the performance of Arabic in speech‑to‑text (STT) models, where recognition rates have been relatively low. -
Key points
- Arabic includes the standard language (MSA) plus over 30 dialects; frequent code‑switching makes data collection challenging.
- The “Arcade” voice‑data collection feature in Pluto’s mobile app is used for an Arabic speech‑data collection event.
- Participants read presented sentences and record their voices; the AI system analyzes the recordings to determine dialect type.
- If the dialect is unclear, additional sentences are offered to encourage re‑participation, boosting data accuracy.
-
Why now
Demand for multilingual voice data continues to grow, especially among global big‑tech companies. Pluto is acting proactively to meet both current project requests and potential future demand. -
Expected impact
The collected data will reflect linguistic diversity—intonation, pronunciation patterns, vocabulary choices—allowing Pluto to mitigate AI learning bias caused by resource disparities and to develop a dataset that delivers high recognition rates in real‑world environments.
Lee Jeong‑su, CEO of Pluto
“Arabic is a major language used by over 400 million people worldwide, yet it remains a low‑resource language for AI training. Through this project we will build data that faithfully reflects actual Arabic usage, helping improve Arabic recognition quality in global AI models.”
- See more related articles
プリトがAI多言語認識率を改善するためのアラビア語音声データ収集プロジェクトを開始
人工知能データとソリューションの専門企業であるPlitoは、AIモデルの多言語認識率向上のために高品質アラビア語音声データを収集する新規プロジェクトを開始したと10日、明らかにした。
-
プロジェクトの目的
音声認識(STT)モデルで比較的低い認識率を示すアラビア語の性能改善。 -
特徴
- 標準語(MSA)に加えて30以上の方言が存在し、コードスイッチングが頻繁に起こるためデータ構築が難しい。
- プリトのモバイルアプリに搭載された音声データ収集機能「アーケード」を活用し、アラビア語音声データ収集イベントを実施。
- 参加者は提示された文章を読み録音し、AIが発話データを分析して方言タイプを判別。
- 方言が不確実な場合は追加文章を提示し、再参加を促すことでデータ精度を向上。
-
背景
グローバルビッグテック企業を中心に多言語音声データの需要が増加しており、実際のプロジェクト要求だけでなく潜在需要に先んじて対応するために本プロジェクトを推進。 -
期待効果
発話者のイントネーション、発音パターン、語彙選択など言語的多様性を反映した学習用データを構築し、言語資源の偏差によるAI学習偏向を緩和。実使用環境でも高い認識率を実現できるデータセットへと高度化する計画。
イ・ジョンス・プリト代表
「アラビア語は全世界4億人以上が使用する主要言語だが、AI学習用データは相対的に不足した低資源言語です。今回のプロジェクトを通じて、実際の使用状況を忠実に反映したデータを構築し、グローバルAIモデルのアラビア語認識品質向上に寄与します。」
- 関連記事をもっと見る
Pluto启动项目,收集阿拉伯语语音数据以改进人工智能多语言识别技术
人工智能数据和解决方案公司 Pluto 于 10 日宣布,已启动一项新项目,旨在收集高质量的阿拉伯语语音数据,以提高人工智能模型的多语言识别率。
- 本项目旨在提升阿拉伯语在语音转文本(STT)模型中的识别率,该语言的识别率一直相对较低。除了标准语 MSA 之外,阿拉伯语还有 30 多种方言。由于日常对话中标准语和方言频繁切换,阿拉伯语的语码转换使得构建人工智能训练数据变得十分困难。
- Pluto 正在开展一项阿拉伯语语音数据采集活动,该活动利用其移动应用程序内置的 “Arcade” 语音数据采集功能。参与者朗读呈现的句子并录制自己的声音,人工智能系统会分析语音数据以确定方言类型。如果方言类型不明确,系统会提供额外的句子以鼓励参与者再次参与,从而提高数据的准确性。
- 该公司解释说,之所以推进这个项目,是为了积极响应潜在需求以及实际项目请求,因为对多语言语音数据的需求持续增长,尤其是在全球大型科技公司中。
- Pluto 认为,此次数据收集将有助于创建反映语言多样性的训练数据,包括说话者的语调、发音模式和词汇选择。基于此,Pluto 计划减轻语言资源差异造成的 AI 学习偏差,并开发一个能够在真实环境中实现高识别率的数据集。
Pluto 公司首席执行官 李正洙 表示:“阿拉伯语是全球超过 4 亿人使用的主要语言,但它是一种资源匮乏的语言,用于人工智能训练的数据相对不足。” 他补充道:“通过这个项目,我们将构建能够真实反映阿拉伯语实际使用语境的数据,从而为提升全球人工智能模型中阿拉伯语识别的质量做出贡献。”
- 查看更多相关文章
Pluto lance un projet de collecte de données vocales arabes pour améliorer la reconnaissance multilingue par l’IA
Pluto, une société spécialisée dans les données et les solutions d’intelligence artificielle, a annoncé le 10 qu’elle avait lancé un nouveau projet visant à collecter des données vocales arabes de haute qualité afin d’améliorer le taux de reconnaissance multilingue des modèles d’IA.
- Ce projet visait à améliorer les performances de l’arabe, une langue dont les taux de reconnaissance vocale sont relativement faibles. Outre l’arabe standard moderne (MSA), l’arabe compte plus de 30 dialectes. L’alternance codique, où l’arabe standard et les dialectes sont fréquemment utilisés dans les conversations quotidiennes, rend cette langue difficile à appréhender pour la constitution de données d’entraînement pour l’IA.
- Pluto organise une collecte de données vocales en arabe grâce à la fonctionnalité « Arcade » intégrée à son application mobile. Les participants lisent des phrases et enregistrent leur voix. Le système d’IA analyse ensuite ces données pour déterminer le dialecte. Si le dialecte est incertain, des phrases supplémentaires sont proposées afin d’encourager une nouvelle participation et ainsi améliorer la précision des données.
- L’entreprise a expliqué qu’elle avait entrepris ce projet pour répondre de manière proactive à la demande potentielle ainsi qu’aux demandes de projets réelles, car la demande de données vocales multilingues continue de croître, notamment parmi les grandes entreprises technologiques mondiales.
- Pluto estime que cette collecte de données permettra de créer un ensemble de données d’entraînement reflétant la diversité linguistique, notamment l’intonation, les schémas de prononciation et le vocabulaire des locuteurs. Fort de ces informations, Pluto prévoit d’atténuer les biais d’apprentissage de l’IA liés aux variations des ressources linguistiques et de développer un ensemble de données capable d’atteindre des taux de reconnaissance élevés en situation réelle.
Lee Jeong‑su, PDG de Pluto, a déclaré : « L’arabe est une langue majeure parlée par plus de 400 millions de personnes dans le monde, mais c’est une langue aux ressources limitées, avec des données relativement insuffisantes pour l’entraînement des IA. » Il a ajouté : « Grâce à ce projet, nous contribuerons à améliorer la qualité de la reconnaissance de l’arabe dans les modèles d’IA mondiaux en constituant des données qui reflètent fidèlement le contexte d’utilisation réel de l’arabe. »
- Voir plus d’articles connexes