A Guide to Fine-Tuning FunctionGemma
Source: Google Developers Blog
Overview
In the world of Agentic AI, the ability to call tools translates natural language into executable software actions. Last month we released FunctionGemma, a specialized version of our Gemma 3 270M model explicitly fine‑tuned for function calling. It is designed for developers building fast and cost‑effective agents that turn natural language into executable API actions.
Specific applications often require specialist models. In this post we demonstrate how to fine‑tune FunctionGemma to handle tool‑selection ambiguity—situations where a model must choose between one or more seemingly similar functions to call. We also introduce the FunctionGemma Tuning Lab, a demo tool that makes this process accessible without writing a single line of training code.
Why Fine‑Tune for Tool Calling?
If FunctionGemma already supports tool calling, why is fine‑tuning still useful?
The answer lies in context and policy—a generic model doesn’t know your business rules. Common reasons to fine‑tune include:
Resolving selection ambiguity
A user might ask, “What is the travel policy?” A base model could default to a public Google search, whereas an enterprise‑specific model should query the internal knowledge base.Ultra‑specialization
Train the model to master niche tasks or proprietary formats that aren’t present in public data, such as handling domain‑specific mobile actions (e.g., controlling device features) or parsing internal APIs to generate complex regulatory reports.Model distillation
Use a large model to generate synthetic training data, then fine‑tune a smaller, faster model to execute that workflow efficiently.
The Case Study: Internal Docs vs. Google Search
Dataset
bebechien/SimpleToolCalling (Hugging Face TRL)
The Challenge
We needed a model that can route a query to the correct tool:
| Tool | Purpose |
|---|---|
search_knowledge_base | Internal documents |
search_google | Public information |
Example:
- Generic query: “What are the best practices for writing a simple recursive function in Python?” → should use Google.
- Policy query: “What is the reimbursement limit for travel meals?” → should use internal knowledge base.
The Solution
- Dataset preparation – The dataset contains conversations that require a choice between the two tools.
- Train‑test split – We keep a test set separate to evaluate on unseen data, ensuring the model learns routing logic rather than memorising examples.
When the base FunctionGemma model was evaluated with a 50 %/50 % split, it frequently chose the wrong tool or suggested “discussing” the policy instead of issuing a function call.
⚠️ Critical Note on Data Distribution
How you split the data is as important as the data itself.
from datasets import load_dataset
# Load the raw dataset
dataset = load_dataset("bebechien/SimpleToolCalling", split="train")
# Convert to conversational format
dataset = dataset.map(
create_conversation,
remove_columns=dataset.features,
batched=False,
)
# 50 % train – 50 % test (no shuffling)
dataset = dataset.train_test_split(test_size=0.5, shuffle=False)Why this matters
- The guide used a 50/50 split with
shuffle=Falsebecause the original dataset is already shuffled. - If your source data is ordered by category (e.g., all
search_googleexamples first, then allsearch_knowledge_base), disabling shuffling will train the model on only one tool and test it on the other, causing catastrophic performance.
Best practice
- Verify that the source data is mixed.
- If the ordering is unknown, set
shuffle=True(or shuffle before splitting) to guarantee a balanced representation of all tools during training.
The Result
The model was fine‑tuned with SFTTrainer (Supervised Fine‑Tuning) for 8 epochs. The loss curve shows rapid adaptation to the new routing logic:
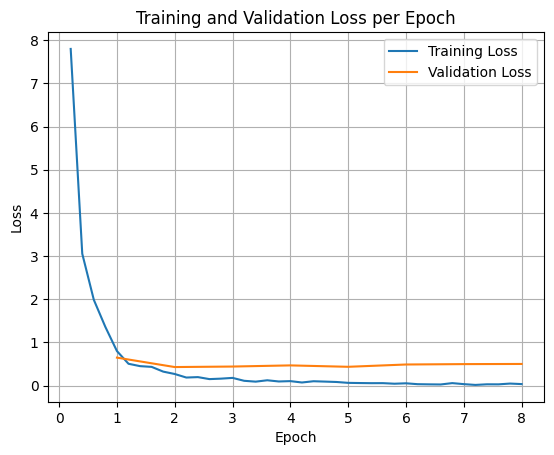
After fine‑tuning, the model reliably follows enterprise policy. For example, the query:
“What is the process for creating a new Jira project?”
now yields the correct function call:
call:search_knowledge_base{query:Jira project creation process}The model has learned to distinguish internal‑policy questions from public‑information queries and to invoke the appropriate tool automatically.
Introducing the FunctionGemma Tuning Lab
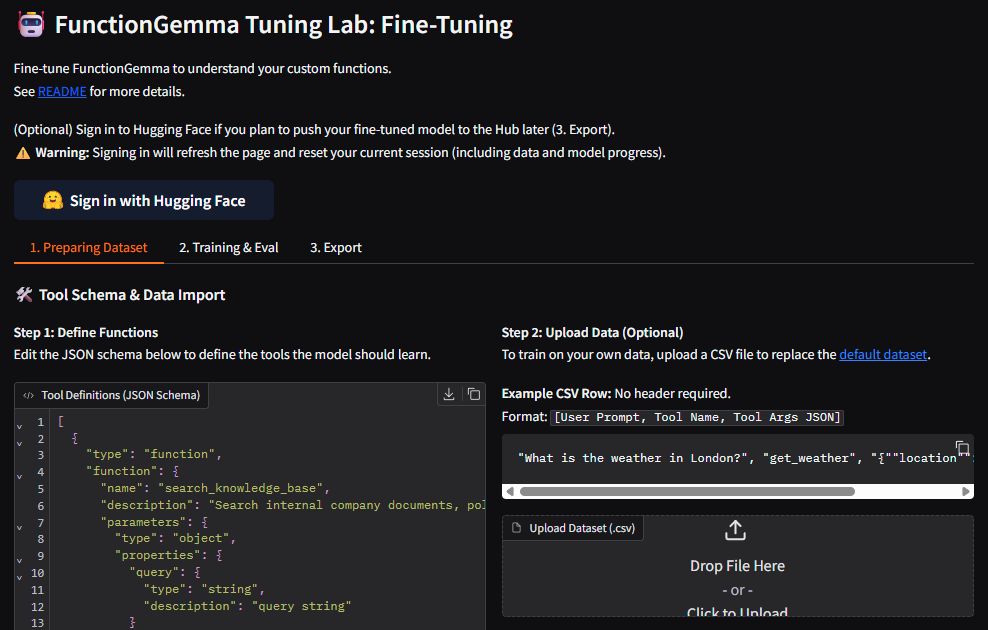
The FunctionGemma Tuning Lab is a user‑friendly demo hosted on Hugging Face Spaces. It streamlines the entire process of teaching the model your specific function schemas.
Key Features
- No‑Code Interface – Define function schemas (JSON) directly in the UI; no Python scripts required.
- Custom Data Import – Upload a CSV containing User Prompt, Tool Name, and Tool Arguments.
- One‑Click Fine‑Tuning – Adjust learning rate and epochs with sliders and start training instantly. Default settings work well for most use cases.
- Real‑Time Visualization – Watch training logs and loss curves update live to monitor convergence.
- Auto‑Evaluation – The lab automatically evaluates performance before and after training, giving immediate feedback on improvements.
Getting Started with the Tuning Lab
To run the lab locally, clone the repository with the Hugging Face CLI and start the app:
hf download google/functiongemma-tuning-lab --repo-type=space --local-dir=functiongemma-tuning-lab
cd functiongemma-tuning-lab
pip install -r requirements.txt
python app.pyThat’s it—you’re ready to fine‑tune FunctionGemma without writing any code!
Conclusion
Whether you choose to write your own training script using TRL or to use the demo visual interface of the FunctionGemma Tuning Lab, fine‑tuning is the key to unlocking the full potential of FunctionGemma. It transforms a generic assistant into a specialized agent capable of adhering to strict business logic and handling complex, proprietary data structures.
Thanks for reading!