3 Ways NVIDIA Is Powering the Industrial Revolution
Source: NVIDIA AI Blog
The NVIDIA accelerated computing platform is leading supercomputing benchmarks once dominated by CPUs, enabling AI, science, business and computing efficiency worldwide.
Moore’s Law has run its course, and parallel processing is the way forward. With this evolution, NVIDIA GPU platforms are now uniquely positioned to deliver on the three scaling laws — pretraining, post‑training and test‑time compute — for everything from next‑generation recommender systems and large language models (LLMs) to AI agents and beyond.
- How NVIDIA has transformed the foundation of computing
- AI pretraining, post‑training and inference are driving the frontier
- How hyperscalers are using AI to transform search and recommender systems
The CPU‑to‑GPU Transition: A Historic Shift in Computing
At SC25, NVIDIA founder and CEO Jensen Huang highlighted the shifting landscape. Within the TOP100, a subset of the TOP500 list of supercomputers, over 85 % of systems use GPUs. This flip represents a historic transition from the serial‑processing paradigm of CPUs to massively parallel accelerated architectures.
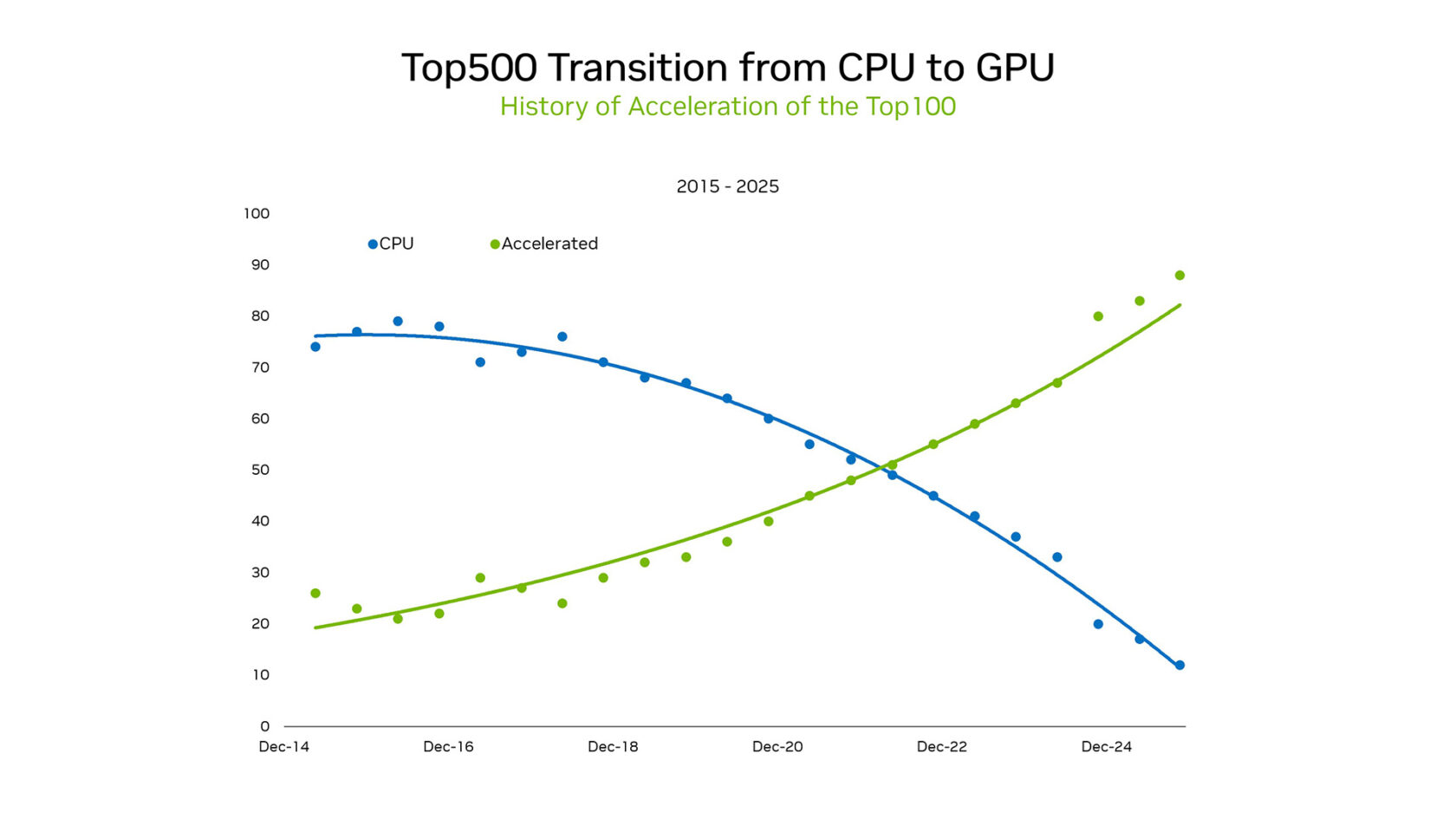
Before 2012, machine learning was based on programmed logic. Statistical models ran efficiently on CPUs as a corpus of hard‑coded rules. This changed when AlexNet running on gaming GPUs demonstrated that image classification could be learned from examples. Parallel processing on GPUs driving a new wave of computing made exascale practical without untenable energy demands.
Recent results from the Green500, a ranking of the world’s most energy‑efficient supercomputers, underscore the contrast between GPUs and CPUs. The top five performers were all NVIDIA GPUs, delivering an average of 70.1 gigaflops per watt, while the top CPU‑only systems provided 15.5 flops per watt on average. This 4.5× differential highlights the massive TCO advantage of moving to GPUs.
Researchers can now train trillion‑parameter models, simulate fusion reactors and accelerate drug discovery at scales CPUs alone could never reach.
Another measure of the CPU‑versus‑GPU differential arrived with NVIDIA’s results on the Graph500. NVIDIA delivered a record‑breaking 410 trillion traversed edges per second, using 8,192 NVIDIA H100 GPUs to process a graph with 2.2 trillion vertices and 35 trillion edges. The next best result required roughly 150,000 CPUs for the same workload, illustrating huge hardware‑footprint reductions.
NVIDIA also showcased at SC25 that its AI supercomputing platform is far more than GPUs—networking, CUDA libraries, memory, storage and orchestration are co‑designed to deliver a full‑stack platform.

Enabled by CUDA, NVIDIA is a full‑stack platform. Open‑source libraries and frameworks in the CUDA‑X ecosystem drive big speedups. Snowflake recently announced an integration of NVIDIA A10 GPUs to supercharge data‑science workflows. Snowflake ML now comes preinstalled with NVIDIA cuML and cuDF libraries to accelerate popular ML algorithms.
With this native integration, Snowflake’s users can accelerate model development cycles with no code changes required. NVIDIA’s benchmark runs show 5× less time for Random Forest and up to 200× for HDBSCAN on NVIDIA A10 GPUs compared with CPUs.
As it stands, GPUs are the logical outcome of efficiency math and the catalyst for a new paradigm. But CUDA‑X and many open‑source software libraries and frameworks are where much of the magic happens.

What began as an energy‑efficiency imperative has matured into a scientific platform: simulation and AI fused at scale. The leadership of NVIDIA GPUs in the TOP100 is both proof of this trajectory and a signal of what comes next—breakthroughs across every discipline.
The Three Scaling Laws Driving AI’s Next Frontier
The change from CPUs to GPUs is not just a milestone in supercomputing. It’s the foundation for the three scaling laws that represent the roadmap for AI’s next workflow: pretraining, post‑training and test‑time scaling.
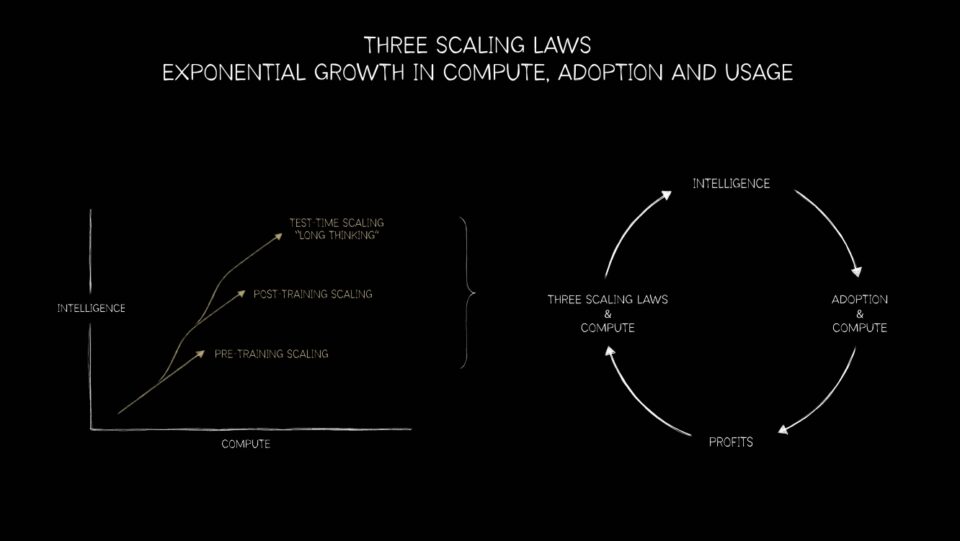
Pre‑training scaling
Pre‑training scaling was the first law to assist the industry. Researchers discovered that as datasets, parameter counts and compute grew, model performance improved predictably. Doubling the data or parameters meant leaps in accuracy and versatility.
On the latest MLPerf Training benchmarks, the NVIDIA platform delivered the highest performance on every test and was the only platform to submit on all tests. Without GPUs, the “bigger is better” era of AI research would have stalled under power budgets and time constraints.
Post‑training scaling
Post‑training scaling extends the story. Once a foundation model is built, it must be refined—tuned for industries, languages or safety constraints. Techniques like reinforcement learning from human feedback, pruning and distillation require enormous additional compute, sometimes rivaling pre‑training itself. GPUs provide the horsepower, enabling continual fine‑tuning and adaptation across domains.
Test‑time scaling
Test‑time scaling, the newest law, may prove the most transformative. Modern models powered by mixture‑of‑experts architectures can reason, plan and evaluate multiple solutions in real time. Chain‑of‑thought reasoning, generative search and agentic AI demand dynamic, recursive compute—often exceeding pre‑training requirements. This stage will drive exponential demand for inference infrastructure—from data centers to edge devices.
Together, these three laws explain the demand for GPUs for new AI workloads. Pre‑training scaling has made GPUs indispensable.