为什么蛋白质会折叠以及 GPU 如何帮助我们折叠
Source: Hacker News
在谈 AI 之前,我们必须先谈谈为什么蛋白质如此复杂
你知道有多疯狂吗?就在你阅读此文时,你体内大约有 20,000 种不同类型的蛋白质在工作。不是说总共只有 20,000 种蛋白质,而是 20,000 种类型。实际的蛋白质分子数量?数十亿。如果把所有细胞算进去,甚至是数万亿。
每一种都有特定的功能和特定的形状。如果 哪怕一种 类型折叠错误,都可能导致阿尔茨海默症、囊性纤维化、镰状细胞贫血、帕金森病、亨廷顿病、疯牛病,或其他数千种蛋白质错误折叠疾病。
你的身体每天在大约 37 万亿个细胞里完美地合成这些蛋白质,数十亿次——没有使用手册,也没有车间。
数十年来,科学家们一直在尝试仅凭氨基酸序列 预测 蛋白质会折叠成什么形状。整个职业生涯、诺贝尔奖、超级计算机都投入到了这个问题上。随后,AI 公司在 2020 年出现,声称已经解决了这个问题,并且的确取得了快速进展。
现在我们不仅在预测形状,还在 设计 全新蛋白质,这些蛋白质可以分解塑料、捕获二氧化碳,或以极高的精度定位癌细胞。
但在深入 NVIDIA 的角色之前,先来了解一下蛋白质到底是什么,以及为什么折叠是如此艰巨的挑战。
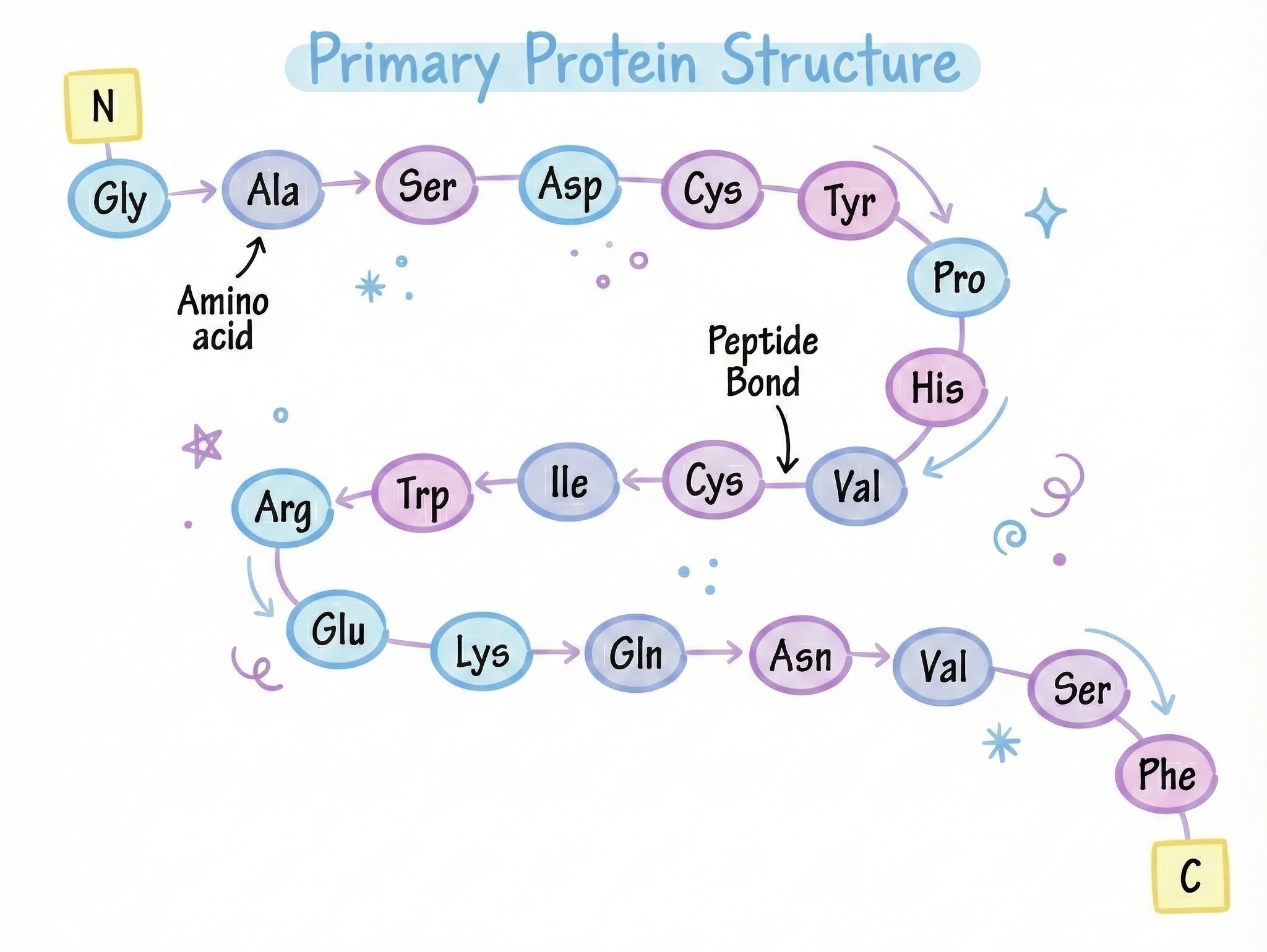
蛋白质 101:生命的乐高积木(只不过更复杂,而且它们会自我组装)
回想中心法则:DNA → RNA → 蛋白质。信息单向流动(逆转录病毒除外)。
蛋白质是一条氨基酸链,折叠成特定的三维形状,而这个形状决定了蛋白质的功能。
链 → 折叠 → 形状 → 功能。
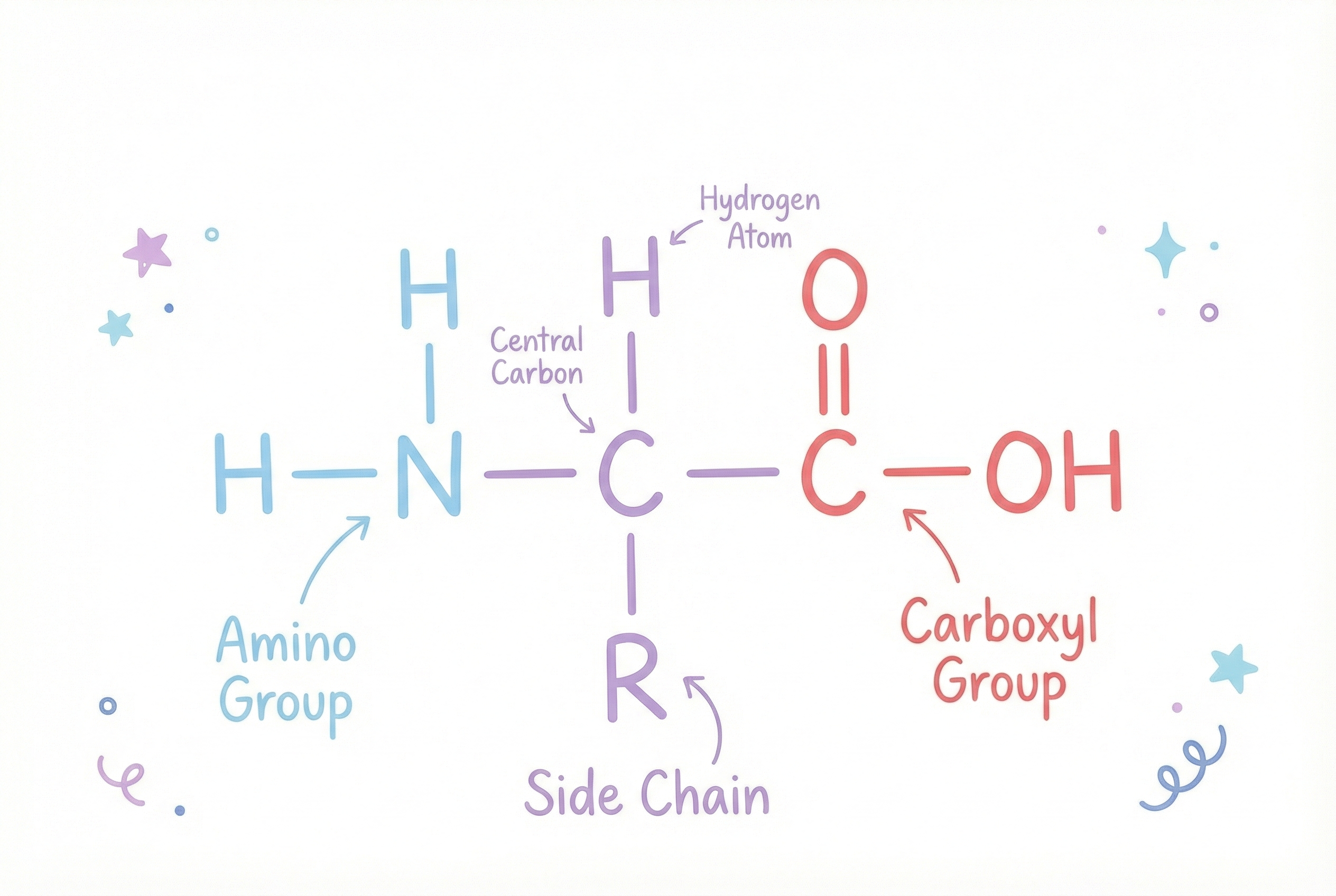
氨基酸:写就你身体所有功能的 20 字母字母表
人体用 20 种标准氨基酸 来构建蛋白质(还有少数非标准氨基酸,但我们暂时不讨论)。把它们想象成字母,组合成能执行功能的机器。
每个氨基酸都有共同的主干:
- 氨基基团 (NH₂)
- 羧基基团 (COOH)
- 连接在中心碳上的氢原子
…以及一个独特的 侧链(R 基团),赋予每种氨基酸不同的“性格”。
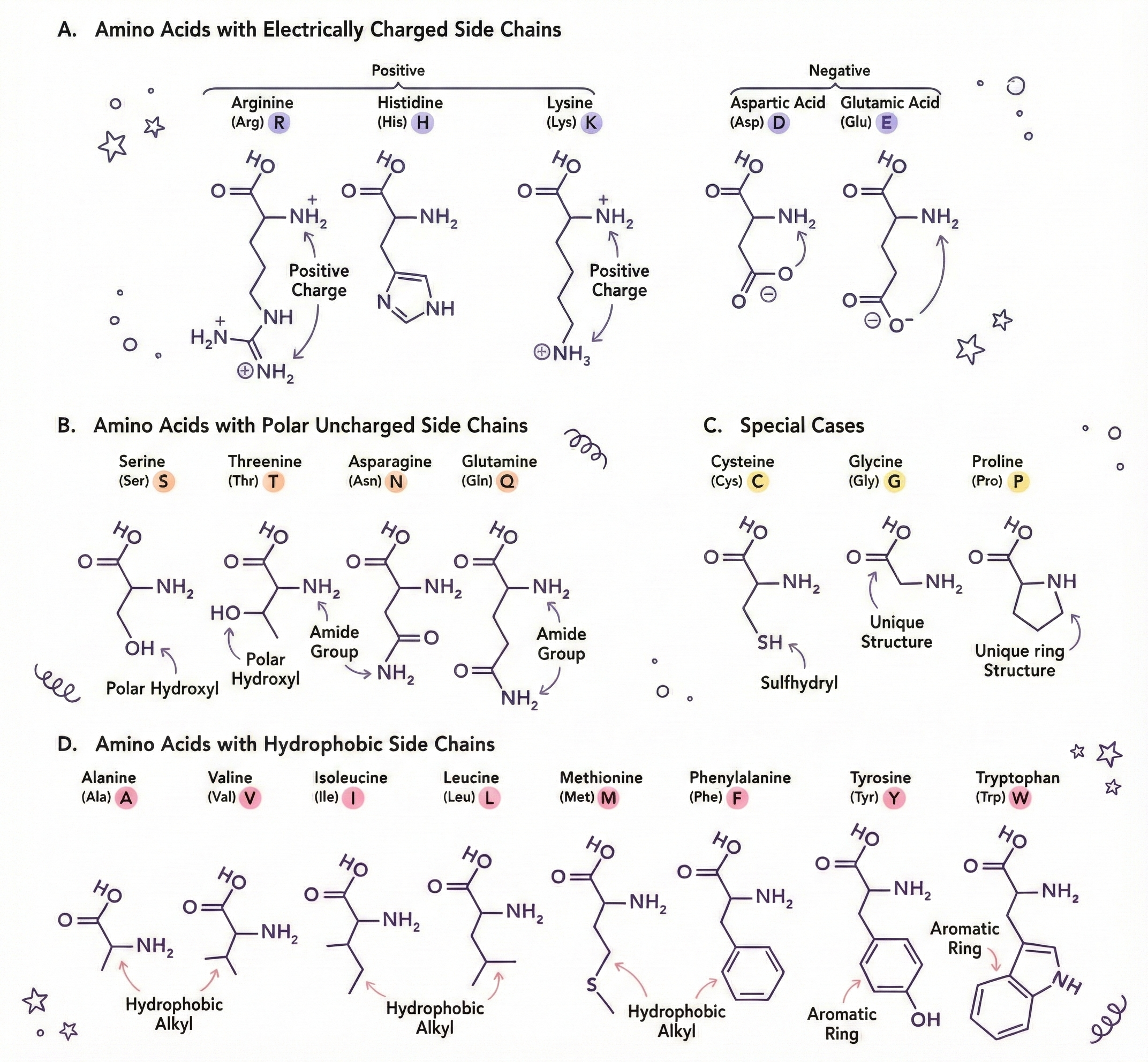
让我向你介绍几种氨基酸(它们都有性格)
- 甘氨酸(Glycine) – 最小;侧链只有一个氢原子。灵活且善于合作。
- 脯氨酸(Proline) – 环状结构会产生弯折;是迫使链条弯曲的“叛逆者”。
- 半胱氨酸(Cysteine) – 含硫;两个半胱氨酸可以形成二硫键 (S‑S),相当于化学订书钉。
- 色氨酸(Tryptophan) – 大而笨重;通常埋在蛋白质核心,因为它是疏水的。
- **天冬氨酸(Aspartic acid)& 谷氨酸(Glutamic acid) – 带负电;排斥其他负电,吸引正电。
- **赖氨酸(Lysine)& 精氨酸(Arginine) – 带正电;吸引负电基团,稳定结构。
- 苯丙氨酸(Phenylalanine)、亮氨酸(Leucine)、异亮氨酸(Isoleucine)、缬氨酸(Valine) – 疏水性;它们倾向于聚集在远离水的地方。
侧链决定了:
- 親水性 vs. 疏水性
- 电荷(正、负、中性)
- 大小(影响包装)
- 刚性 vs. 柔性
- 化学反应性
组合爆炸:可能性的天文数字
典型蛋白质含有 200–400 个氨基酸;有些如肌联蛋白(titin)甚至有 34,350 个。
对于一个仅有 100 个氨基酸的普通蛋白质,其可能的序列数是 20¹⁰⁰ ≈ 1.27 × 10¹³⁰。
- 可观测宇宙的原子数:约 10⁸⁰
- 可观测宇宙的恒星数:约 10²⁴
因此,100 残基序列的可能性大约比宇宙中的原子多 10⁵⁰ 倍。绝大多数序列根本不会折叠成功,而是聚集或被降解。进化在 35 亿年的时间里进行了一场巨大的暴力搜索,才找到了少数可行的折叠方式。
我们没有这么长的时间尺度,所以必须用更聪明的方法在 现在 设计蛋白质。
折叠:魔法发生的地方(也是一切可能出错的地方)
当核糖体完成蛋白质的翻译后,它会释放出一条长而线性的 多肽链。主链由重复的 NH‑CHR‑CO 单元通过 肽键 连接:
...—NH—CHR—CO—NH—CHR—CO—NH—CHR—CO—...侧链(R 基团)从主链上伸出。合成完成后,链条立即开始探索构象,寻找由其序列决定的能量最低的三维结构。这个折叠过程快速、协同,是功能实现的关键——但也极易出错,进而导致疾病。