谁审计审计员?构建 LLM-as-a-Judge 以实现 Agentic Reliability
发布: (2026年4月17日 GMT+8 00:12)
5 分钟阅读
原文: Dev.to
Source: Dev.to
开始之前
先决条件: 已有的代理工作流(参见 MCP 法医系列)以及一个高推理模型(Claude 3.5 Opus 或 GPT‑4o)来充当法官。
1. “黄金数据集”
在对代理进行评分之前,我们需要一个答案键。创建 tests/golden_dataset.json;它包含“真实答案”——我们已知存在错误的情景。
{
"test_id": "TC-001",
"input": "The Great Gatsby, 1925",
"expected_finding": "Page count mismatch: Observed 218, Standard 210",
"severity": "high"
}导演注: 在企业环境中,“可靠性”是“权限”的前置条件。在能够证明代理不会产生 5 万美元的幻觉错误之前,你是得不到扩展预算的。该框架提供了内部说服所需的数据。
2. 法官的评分标准
一个好的法官需要超越简单的“是/否”的评分标准。我们从以下维度打分:
- 精确度(Precision): 它只找到了真实错误吗?
- 召回率(Recall): 它找到了所有真实错误吗?
- 推理(Reasoning): 它是否解释了为何标记该记录?
3. 为弹性而重构
我们消除了一个常见的“高级别”陷阱:硬编码代理逻辑。系统提示从 Python 客户端迁移到专用的 config/prompts.yaml。将 指令 与 执行 解耦提升了可观测性,并让我们能够对不同提示版本进行 A/B 测试,以观察哪种在特定模型上产生最高准确率。
4. 实现:评估循环
我们向仓库中添加了 evaluator.py(GitHub 链接)。它不仅运行代理,还监控它们的“生命体征”。
- 错误透明度: 被吞掉的异常被结构化日志取代。如果提供者失败,事件会被记录以便诊断,而不是静默失败。
- 握手(Handshake): 循环运行取证团队,收集它们的日志,并将完整包提交给高推理的法官代理。
评估‑优化器蓝图
此图展示了从“代码能运行吗?”到 “智能是否达到质量门槛?” 的转变。闭环系统是我们在通过为更简单的任务选择更小模型来进行财政优化之前的必备条件。
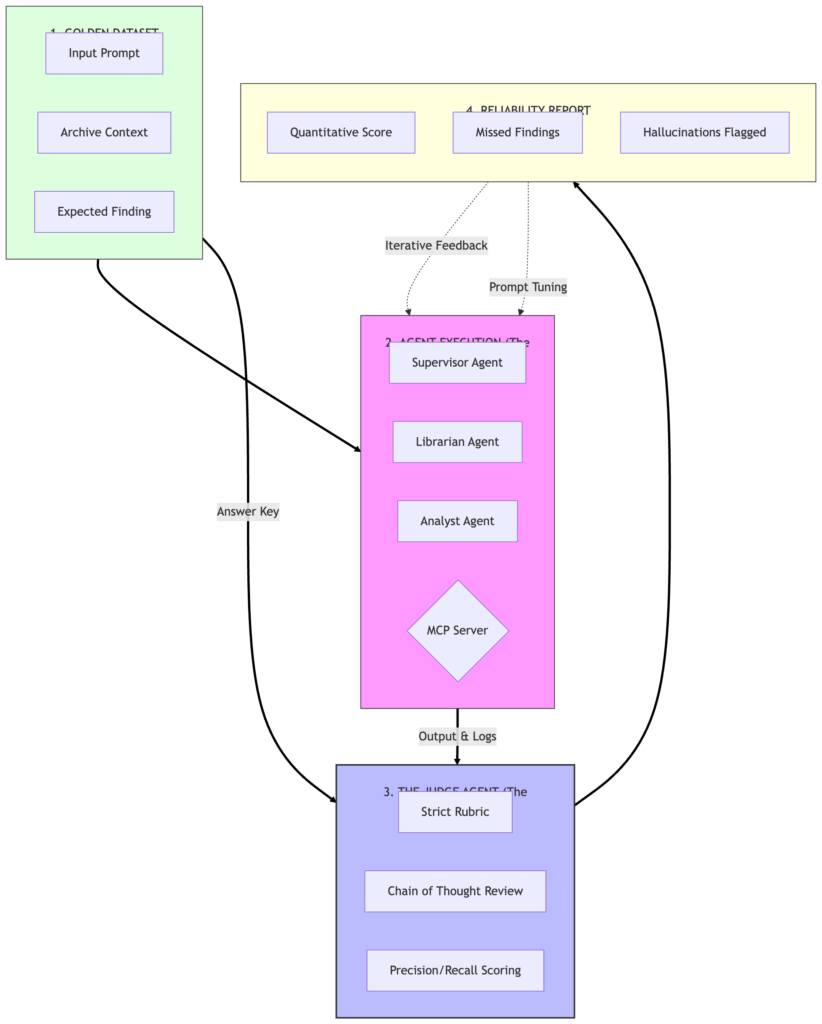
导演层面的洞察:“准确率 vs. 成本”曲线
作为导演,我关心的不仅是“每 token 成本”。我需要可辩护性。如果取证审计受到质疑,我必须展示历史准确率。实现此评估器让我们从“凭感觉检查”转向量化的可靠性分数,从而能够为部署设定 最低质量门槛。如果模型更新或提示更改导致准确率下降 2 %,法官将阻止部署。
生产级 AI 系列
- 第 1 篇: 法官代理 — 您正在阅读此篇
- 第 2 篇: 会计师(认知预算与模型路由) — 即将发布
- 第 3 篇: 守护者(人机交互握手) — 即将发布
想了解基础内容?请查看之前的系列:零粘合 AI 网格与 MCP。