当防护措施超出其目的时:大规模管理防御系统的经验教训
Source: GitHub Blog
要为您提供翻译,我需要您粘贴或提供要翻译的完整文本内容。请把文章的正文(除代码块、URL 和 Markdown 语法之外的部分)贴在这里,我会按照要求保持原始格式并翻译成简体中文。
维护平台可用性
问题
有时作为 紧急响应 添加的防护措施会超出其有效期,开始阻碍合法用户。这通常发生在快速事件响应需要更广泛的控制,而这些控制并非设计为永久性的情况下。
我们的经验
- 过时的缓解措施 会降低用户体验。
- 可观测性 对防御措施和功能同样关键。
- 来自用户的及时反馈对于识别并移除陈旧的防护措施至关重要。
我们的道歉
对造成的中断我们深表歉意。我们本应更早检测并移除这些防护措施。
后续步骤
- 审查并退役所有不再需要的紧急缓解措施。
- 加强监控,以捕捉防御控制的意外副作用。
- 持续收集用户反馈,确保我们的防御保持透明且有效。
用户报告的情况
我们在社交媒体上看到有人报告在正常、低流量浏览时收到 “Too many requests” 错误——例如,从其他服务或应用点击 GitHub 链接,或仅仅是没有任何明显滥用模式的浏览。
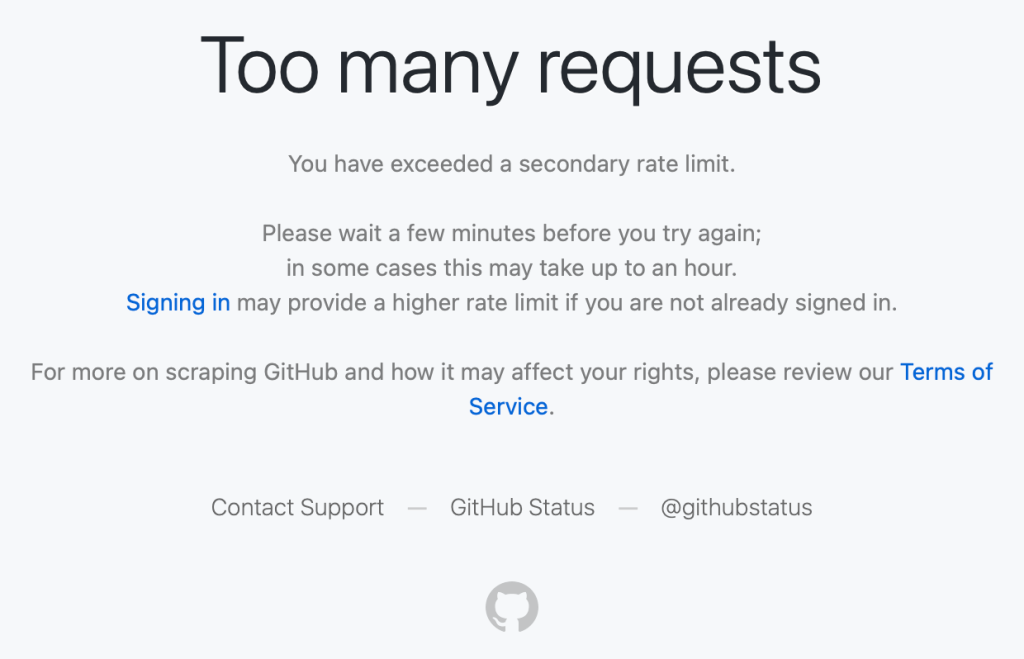
用户在正常浏览时遇到了 “Too many requests” 错误。
这些用户只发出少量正常请求,却触发了本不该适用于他们的速率限制。
Source: …
我们发现的情况
调查报告后发现根本原因:过去滥用事件期间添加的保护规则被保留下来。这些规则是根据当时与滥用流量高度相关的模式创建的。遗憾的是,同样的模式也匹配了一些合法客户端的已登出请求。
复合信号与误报
- 这些模式将业界标准的指纹识别技术与平台特定的业务逻辑相结合。
- 复合信号有时会产生误报。
关键统计
| 指标 | 数值 |
|---|---|
| 匹配可疑指纹并被阻止的请求 | 0.5 % – 0.9 %(仅当它们也触发业务逻辑规则时) |
| 同时匹配 两项 标准的请求 | 100 % 被阻止 |
| 相对于总流量的误报率 | 0.003 % – 0.004 %(约 3‑4 次/10 万请求) |
注意: 只有指纹匹配同时满足业务逻辑模式时才会被阻止。
可视化摘要
| 描述 | 图片 |
|---|---|
| 指纹匹配被阻止的比例(0.5‑0.9 % 于 60 分钟内) | 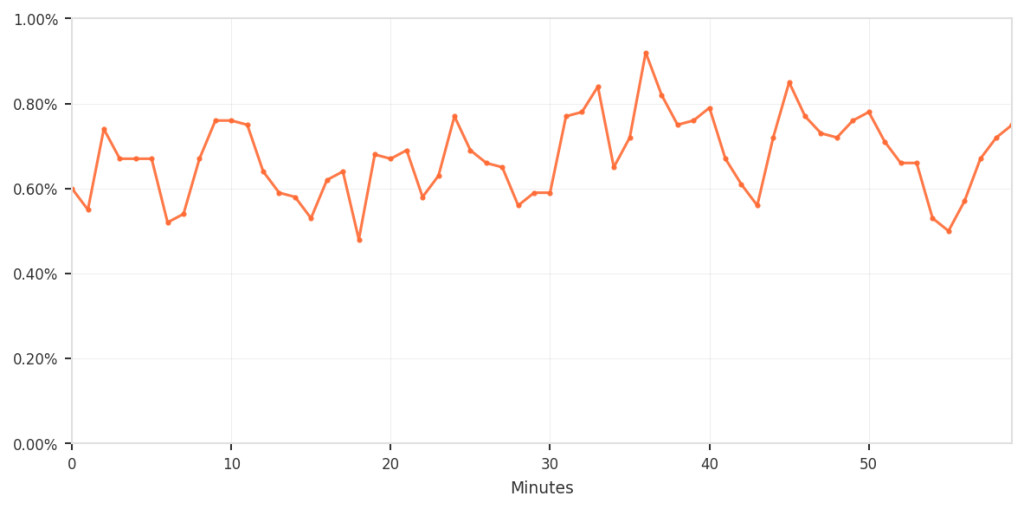 |
| 误报占总流量的比例(0.003‑0.004 %) | 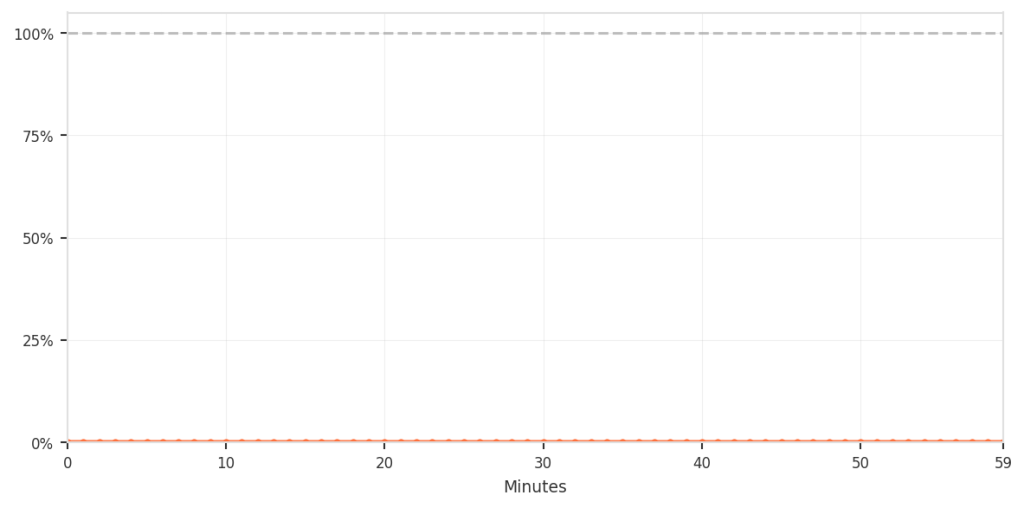 |
| 误报模式随时间的放大视图 | 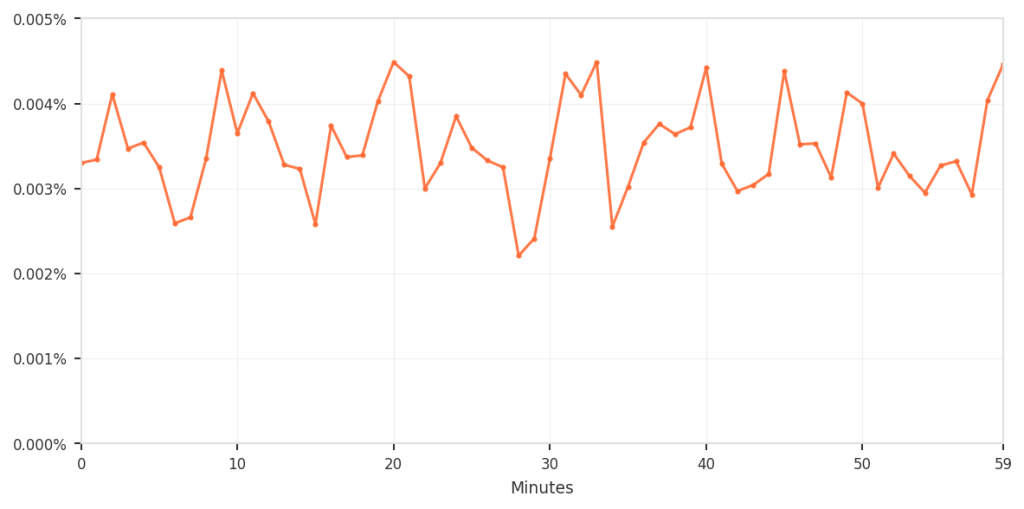 |
虽然这些比例很低,但任何错误阻止都会影响真实用户,因而是不可接受的。
为什么临时缓解措施会变成永久措施
在一次正在进行的事故中,我们必须迅速行动,常常需要接受权衡以保持服务可用。紧急控制在当时是正确的,但随着威胁模式的演变和合法使用的变化,它们并不持久。若缺乏主动维护,临时缓解措施会变成永久性的,并且其副作用会悄然累积。
追踪堆栈
当用户报告错误时,我们在多个基础设施层面追踪请求,以定位阻断发生的位置。
多层防护概览
GitHub 的自定义多层防护基础设施(基于 HAProxy 等开源项目)在多个环节实施防御:
- 边缘层 – DDoS 防护、IP 信誉、速率限制。
- 应用层 – 身份验证、每个用户/服务的速率限制。
- 服务层 – 业务逻辑校验、特定功能的限流。
- 后端层 – 资源级配额、内部安全检查。
示意图(为避免泄露具体机制而简化):
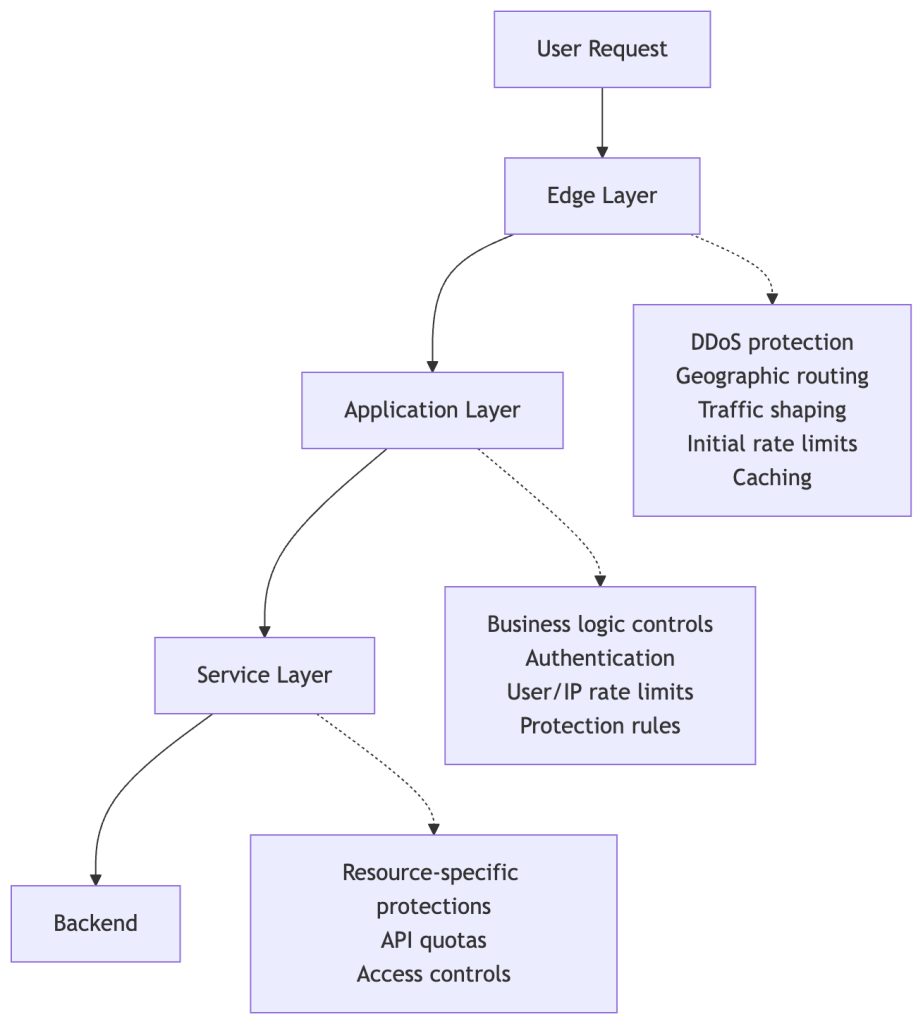
每一层都可以独立阻断或限流请求。要确定是哪一层执行了阻断,需要关联具有不同模式的日志。
调查步骤
| 步骤 | 来源 | 我们查找的内容 |
|---|---|---|
| 1️⃣ | 用户报告 | 时间戳、错误信息、观察到的行为 |
| 2️⃣ | 边缘层日志 | 请求到达前端的记录 |
| 3️⃣ | 应用层日志 | HTTP 429 “请求过多” 响应 |
| 4️⃣ | 防护规则分析 | 哪些规则匹配了该请求 |
通过从用户可见的错误回溯到底层规则配置,我们确认残留的缓解规则是误报的根源。
事故缓解的生命周期
以下图示说明了缓解措施如何超出其有效期:

出了什么问题
- 在事故期间添加的控制措施按预期工作。
- 未设置过期日期、事后审查或影响监控。
- 随着时间推移,这些规则成为技术债务,最终阻断了合法流量。
推荐做法
- 为任何紧急规则设置明确的过期日期。
- 进行事后审查,评估持续影响。
- 自动化影响监控(例如,对异常阻断率发出警报)。
- 记录所有权,以便负责的团队能够撤销或调整规则。
采用这些做法可确保临时防御保持临时性,避免对合法用户产生意外影响。
我们所做的
- Reviewed the mitigations – 将每条规则当前阻止的内容与其最初意图进行比较。
- Removed outdated rules – 删除不再有用的保护措施。
- Retained essential safeguards – 保留仍能防御持续威胁的关键控制。
我们正在构建的内容
- 更好的可视性 在所有保护层中,以追踪速率限制和阻断的来源。
- 默认将事件缓解视为临时;将其永久化应需要有意的、记录在案的决定。
- 事后实践 评估紧急控制并将其演变为可持续的、针对性的解决方案。
防御机制——即使是事件期间快速部署的——也需要与它们所保护的系统同等的关注。它们需要可观测性、文档化和主动维护。当在事件期间添加的保护措施被保留下来时,就会悄然累积成为技术债务。
感谢所有公开报告问题的朋友!你们的反馈直接促成了这些改进。 同时感谢 GitHub 各团队在调查中的付出,以及在我们运营方式中构建更好生命周期管理的努力。我们的平台、团队和社区因为彼此的协作而变得更好!
Tags
- 开发者体验
- 事件响应
- 基础设施
- 可观测性
- 站点可靠性
作者
Thomas Kjær Aabo – GitHub Traffic 团队的工程师。

Source: (保持原样,不翻译)
探索更多来自 GitHub
| Docs – 您掌握 GitHub 所需的一切,尽在一处。 | |
| GitHub – 在 GitHub 上构建下一代产品,这里是来自任何地方的任何人都能构建任何东西的场所。 | |
| Customer stories – 了解使用 GitHub 构建产品的公司和工程团队。 | |
| The GitHub Podcast – 收听涵盖开源开发者社区的话题、趋势、故事和文化的播客。 |