当关键词不足时:使用 Elasticsearch 构建更智能的搜索
Source: Dev.to
摘要
关键词搜索在用户的查询表达方式与存储的文档不同的时候经常失效。我构建了一个基于 Elasticsearch 和向量嵌入的语义搜索系统,以弥合这一差距。在本博客中,我将逐步讲解它的工作原理、实现方式,以及当搜索开始理解意义而不仅仅是词语时所带来的变化。
我最初没有注意到的问题
起初,我以为传统的关键词搜索已经足够。它通过匹配用户查询和存储文档之间的词语来工作;如果文档包含相同的词,就会排名更高。简单且高效。
但随后我测试了下面的查询:
“Affordable laptop for students”
在我的数据集中,我有一个产品标题是:
“Budget notebook with 8 GB RAM for college use”
对人类来说,这两者显然是相关的:
- Affordable ↔ budget
- Laptop ↔ notebook
- Students ↔ college use
然而搜索引擎要么把该产品排得很低,要么根本没有返回。因为词语没有完全匹配,系统没有将它们视为相关。
我意识到,即使意义完全相同,结果也极度依赖于精确的词汇。真实用户并不以关键词思考,而是以概念思考。于是我开始思考:如果搜索比较的是意义而不是词语,会怎样?
理解语义搜索
语义搜索听起来很复杂,但核心思想出奇地直观。
将文本转换为数字 – 与其存储原始文本,我们将每个句子转化为 嵌入向量,即一系列浮点数,用来捕捉其含义。
示例:“Affordable laptop for students” → [0.021, -0.134, 0.889, …]在 Elasticsearch 中存储嵌入向量 – 使用
dense_vector字段类型,每个文档都有自己的向量。比较向量 – 我们使用 余弦相似度(或其他距离度量)来衡量两个向量在高维空间中的接近程度。角度越小 → 语义相似度越高。
k 最近邻 (kNN) – 给定查询向量后,Elasticsearch 找到 k 个最接近的存储向量。它们即被返回为最相关的结果。
因此,我们不再问 “这个文档是否包含相同的词?”,而是问 “这个文档在语义上是否接近查询?” 这种转变会彻底改变搜索的行为。
系统工作原理
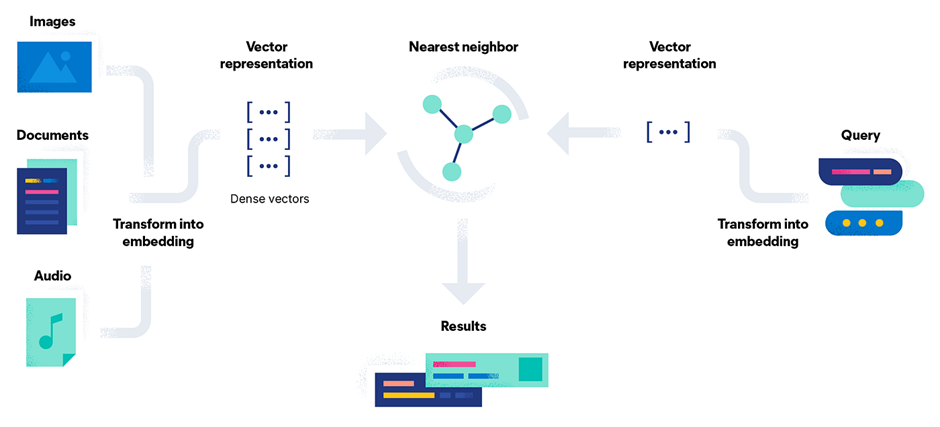
- 用户查询 → embedding – 当用户输入查询时,Transformer 模型(例如 sentence‑transformer)会在 实时 将其转换为 embedding。
- 文档 embedding 已预先存储 – Elasticsearch 中的所有文档都在
dense_vector字段里保存了 embedding,这些向量是在索引时生成的。 - kNN 检索 – Elasticsearch 执行 kNN 查询,将查询向量与所有已存向量通过余弦相似度进行比较,检索出最接近的匹配。
- 返回结果 – 将语义上最相似的文档返回给用户。
从概念上讲,这只是“在高维空间中比较距离”,尽管实现看起来相当高级。
Source: …
步骤构建
1. 部署 Elasticsearch
我在 Elastic Cloud 上部署了 Elasticsearch。使用托管服务比在本地运行实例快得多。几分钟内,我就拥有了一个可以通过 Kibana 和 Python 客户端访问的集群。
2. 创建索引映射
因为要存储向量,我定义了一个 dense_vector 字段,384 维(all‑MiniLM‑L6‑v2 sentence‑transformer 的输出维度)。
PUT products
{
"mappings": {
"properties": {
"title": { "type": "text" },
"description":{ "type": "text" },
"embedding": {
"type": "dense_vector",
"dims": 384
}
}
}
}经验教训: 如果映射中的维度数与实际向量大小不匹配,Elasticsearch 会拒绝文档。这里没有灵活性可言。
3. 生成向量
我在 Python 中使用 sentence-transformers 库:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
def embed(text: str):
return model.encode(text).tolist() # returns a list of 384 floats该模型轻量、快速,并提供强大的语义表示——非常适合小型到中型数据集。
4. 索引文档
对每个产品,我将标题和描述拼接在一起,生成向量,并将文档索引:
doc = {
"title": title,
"description": description,
"embedding": embed(f"{title} {description}")
}
es.index(index="products", id=product_id, document=doc)5. 搜索
我尝试了两种方法:
| 方法 | 描述 |
|---|---|
| 传统关键词搜索 | 对 title/description 使用 match 查询。 |
| 语义 kNN 搜索 | 使用 script_score 对 embedding 字段进行余弦相似度计算。 |
语义方法即使在查询使用同义词或不同表述时,也始终返回相关结果。
最后思考
从关键字匹配转向语义相似性,将脆弱的搜索体验转变为真正理解用户意图的系统。通过利用 sentence‑transformers 进行嵌入以及 Elasticsearch 的 dense_vector + kNN 功能,您可以构建一个强大且具备意义感知的搜索系统,而所需的基础设施开销相对较少。祝您搜索愉快!
关键字 vs. 向量搜索:我的首次实操测试
我最近构建了一个小原型,用于比较两种产品目录搜索方法:
- 关键字匹配查询 – 快速且简单,但在同义词较多的查询上表现不佳。
- k‑NN 向量查询 – 我实时为用户查询生成嵌入,并将其传递给 Elasticsearch 的 k‑NN 搜索。
相关性差异几乎立刻显现。
### Comparing the Results 结果对比
以下是我观察到的简化对比:

- 速度 – 关键字搜索略快,这是预期的。
- 相关性 – 向量搜索始终更贴合用户意图。
- 延迟 – k‑NN 查询的延迟稍高,但对于我的数据集规模仍在可接受范围内。通过调优(尤其是调整
num_candidates),性能进一步提升。
最突出的是相关性,而非速度。系统终于能够理解同义词和上下文含义。
给我最大启发的挑战
- 维度不匹配 – 索引创建后不能更改向量维度,因此我只能删除并重新构建索引。
- 查询最初较慢 – 不恰当的 k‑NN 参数调优导致延迟;减少不必要的候选检查后问题得到解决。
这些并非致命障碍,但迫使我深入了解 Elasticsearch 如何内部处理向量。
对实际使用的思考
在生产环境中,混合方式——结合关键字匹配和向量相似度——通常能提供最佳的精确率与召回率平衡。Elastic Cloud 让分布式搜索工作负载的扩展更为便捷。
潜在的使用场景包括:
- 电子商务网站
- FAQ 检索系统
- 知识库
- 支持机器人
只要用户以自然语言描述需求,语义搜索就能带来真实价值。
结论
本项目始于一个小小的挫败感:搜索结果虽然在技术上可行,却缺乏智能感。通过在 Elasticsearch 中加入向量搜索,我构建了一个能够理解意义而不仅仅是词语重叠的系统。
关键要点
- 嵌入向量非常强大,但需要谨慎配置。细小的设置错误可能导致整个系统失效。
- 相关性不仅仅是匹配文本,更在于解释用户意图。
如果你正在构建搜索系统,仅依赖关键词可能已经不够。看到语义搜索提升结果的效果后,你会很难忽视这种差异。