当 LLM 选择下一个 Token 时到底发生了什么🤯
发布: (2026年1月12日 GMT+8 11:16)
3 分钟阅读
原文: Dev.to
Source: Dev.to
核心概念
给定一个提示,模型会预测每个可能的下一个 token 的概率分布。
例如:
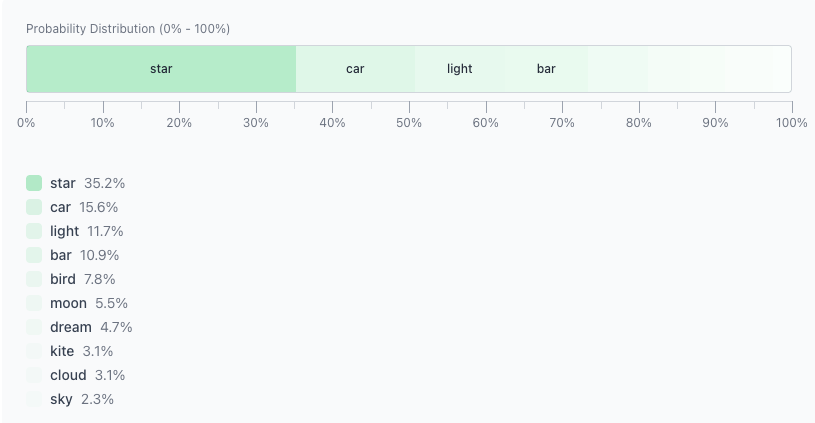
Twinkle twinkle little此时,模型会为每个候选 token 分配一个概率。你可以想象它们被排列在 0–100 的刻度上:
- 概率越高 → 片段越大
- 概率越低 → 片段越小
采样:实际发生的过程
接下来是 采样。一种实用的思考方式:
- 生成一个随机数。
- 看它落在哪个片段。
- 输出对应的 token。
因为 “star” 的片段最大,它是最可能的结果:
Twinkle twinkle little star温度(Temperature)、Top‑p 和 Top‑k 只影响这一步采样。
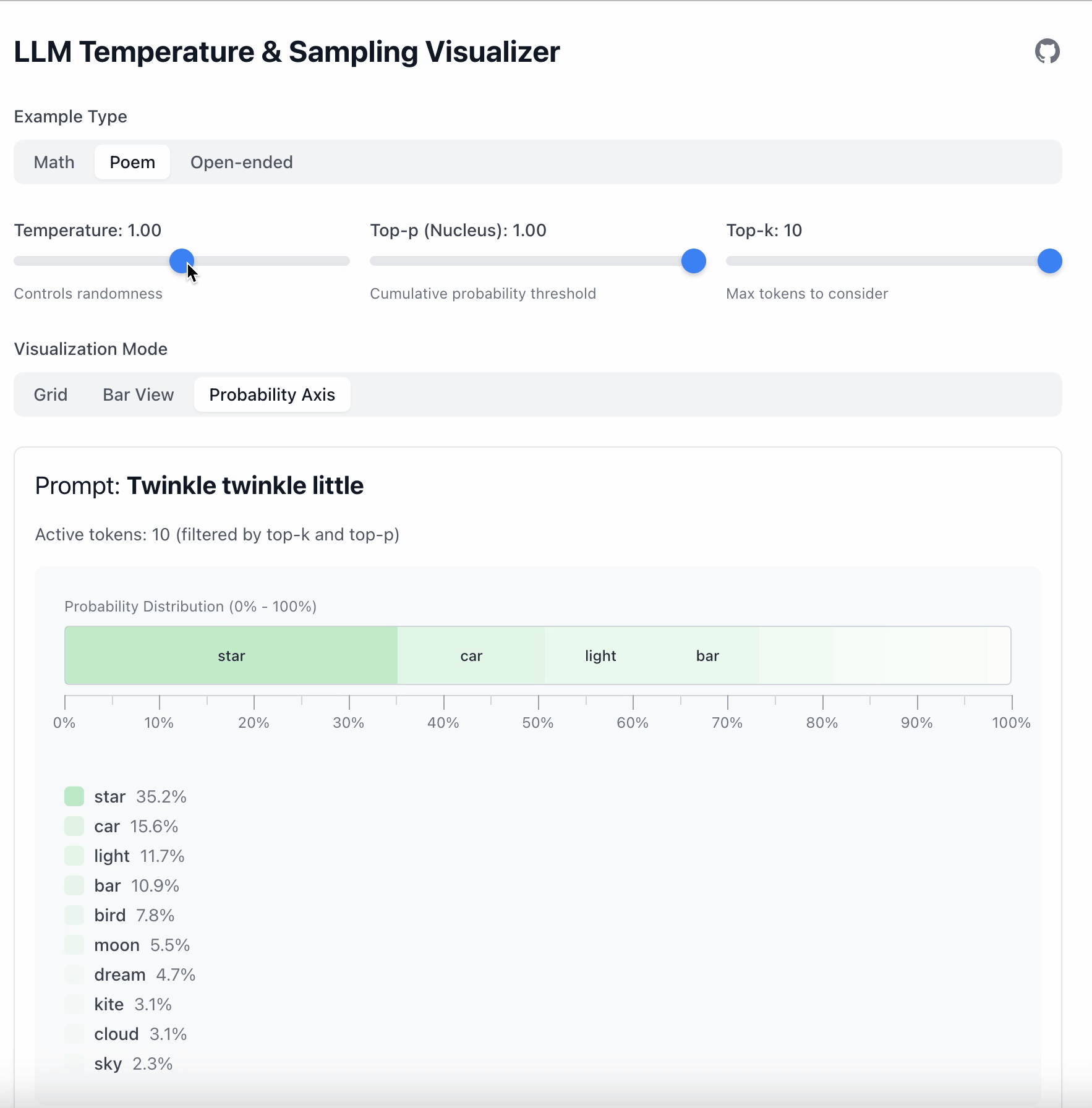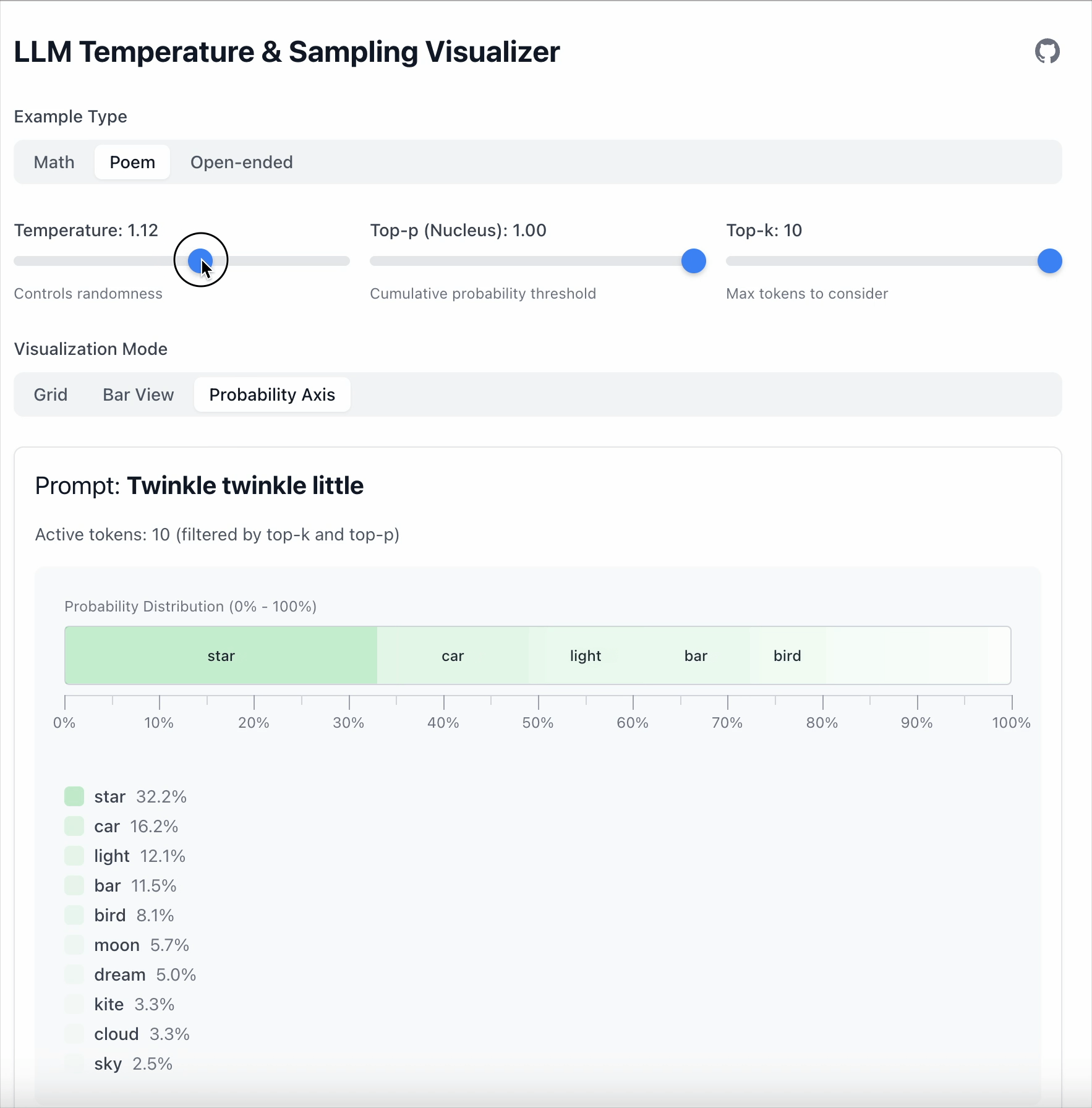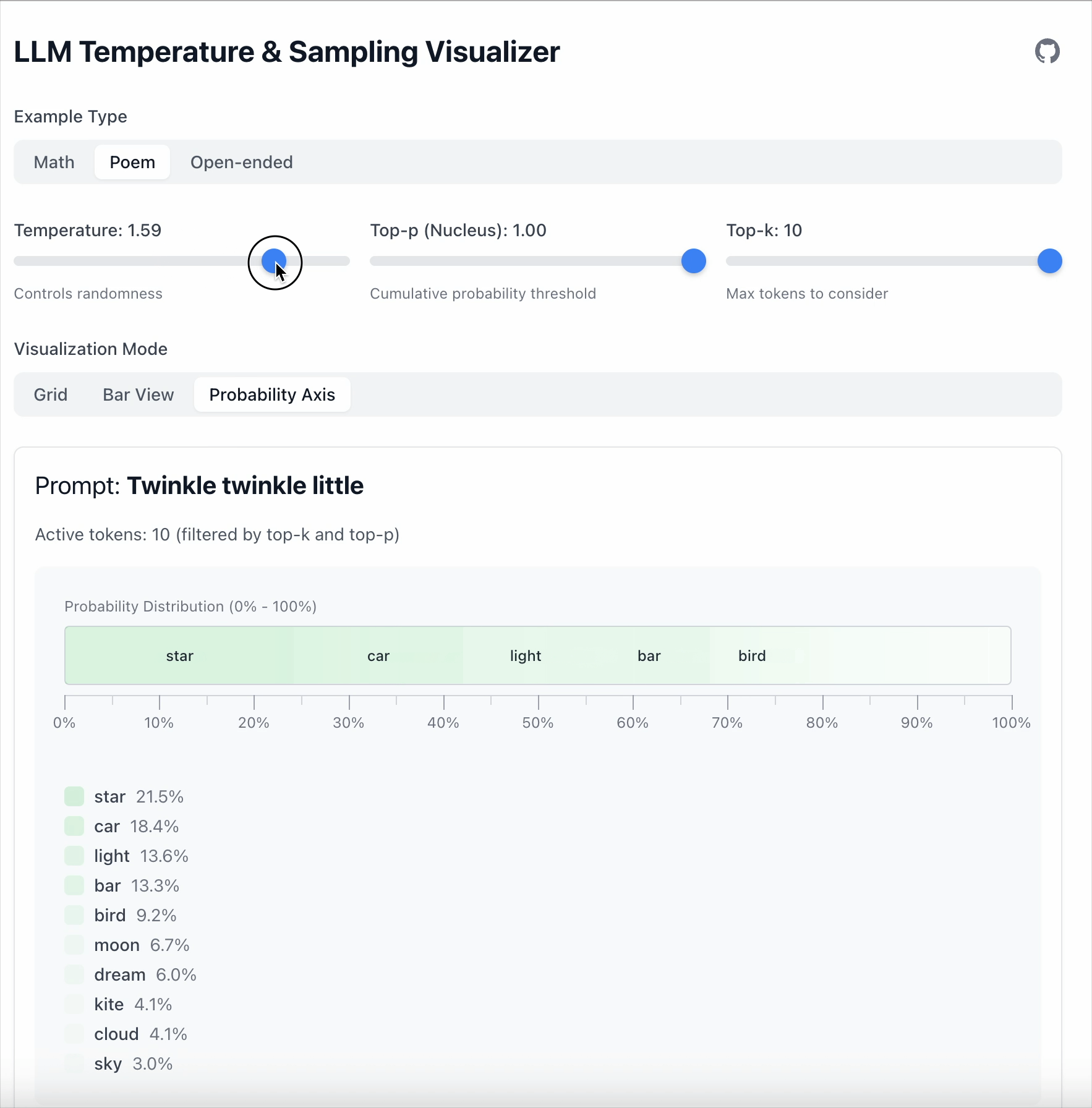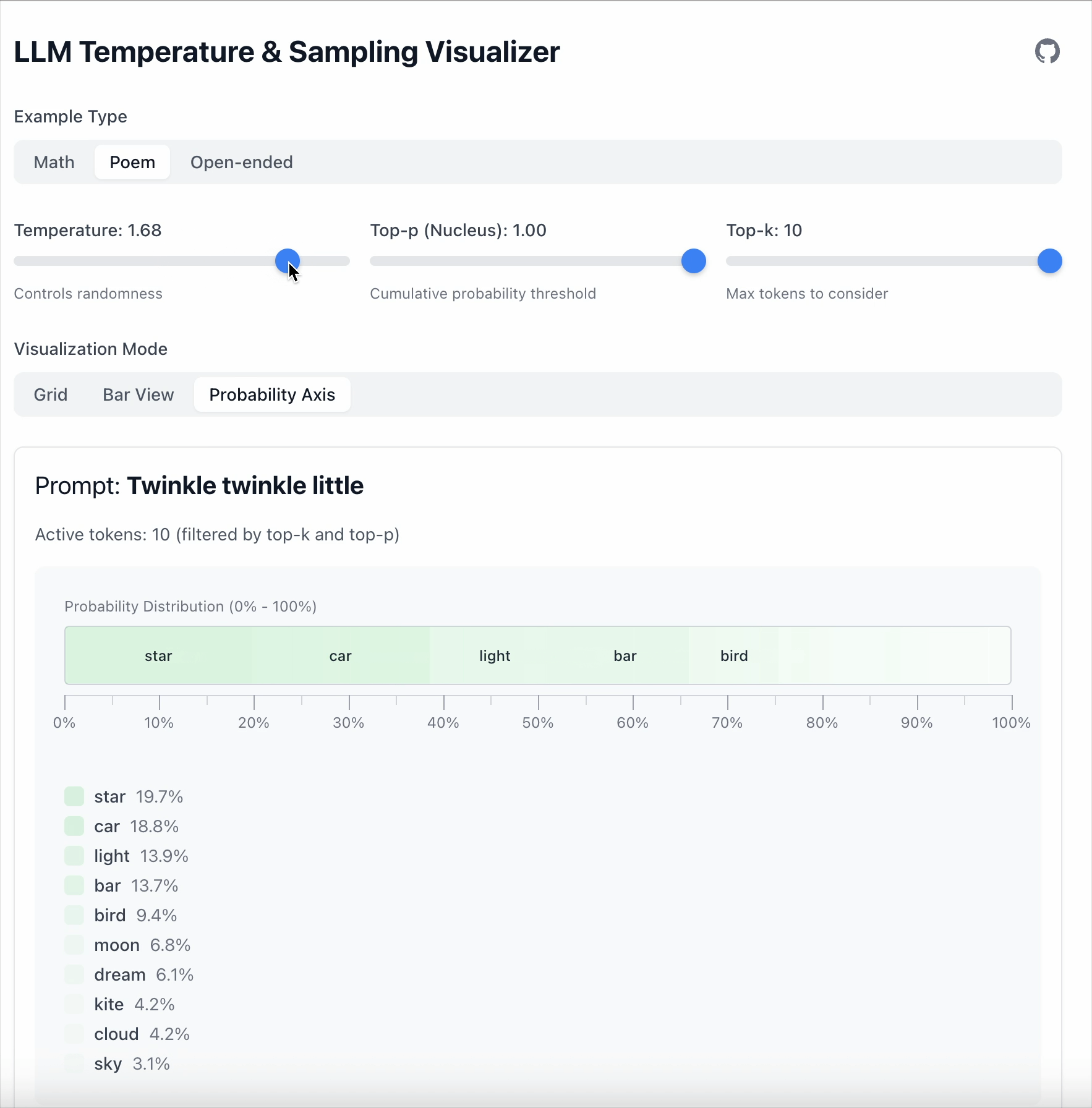
从这里起我们使用默认值:
- Temperature = 1
- Top‑p = 1
- Top‑k = 10
并一次只更改一个参数。
温度(Temperature)
温度只做一件事:拉伸或压平概率差异。
- 温度低 → 偏好强烈 → 输出稳定
- 温度高 → 分布更平坦 → 随机性更大
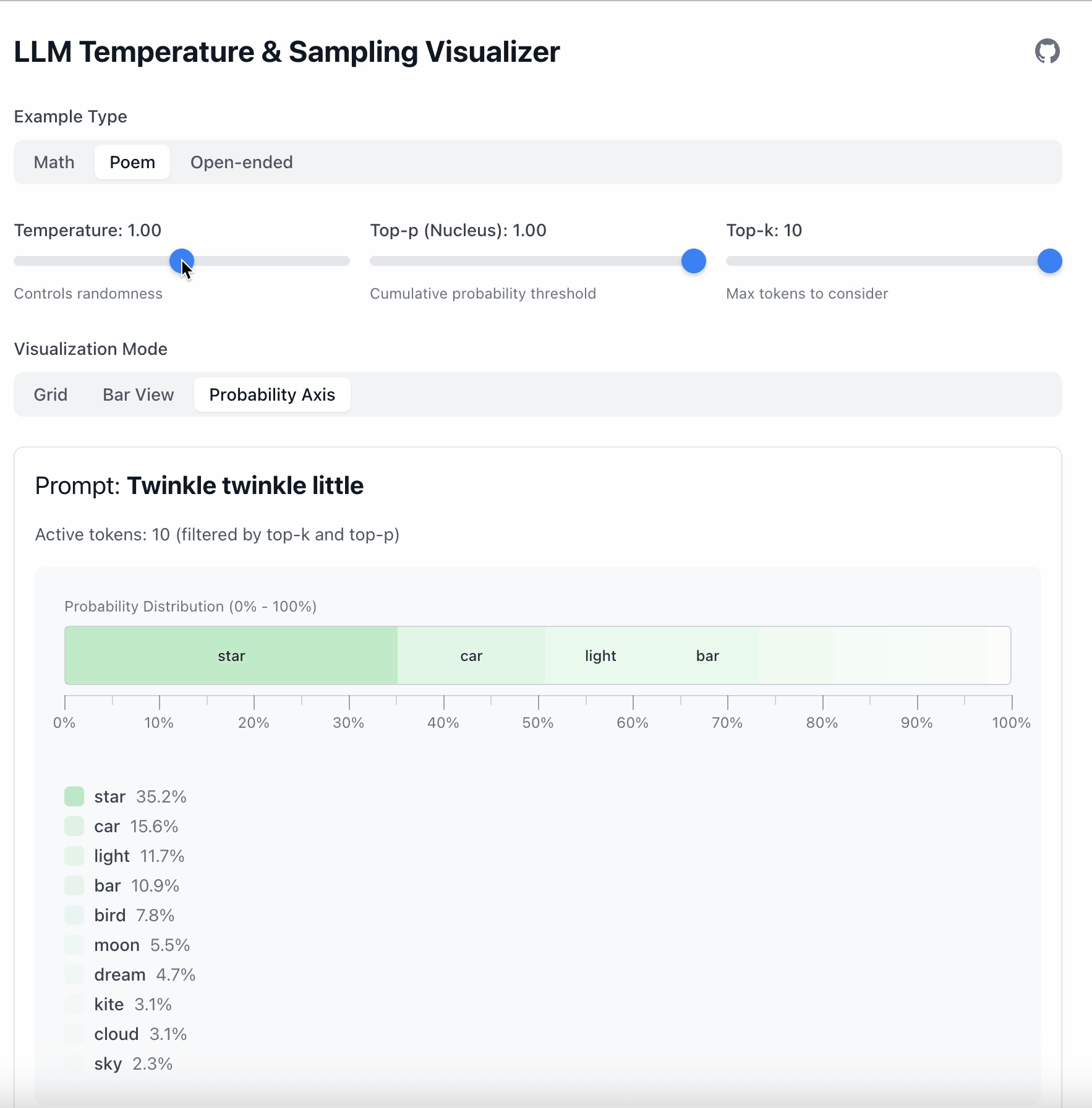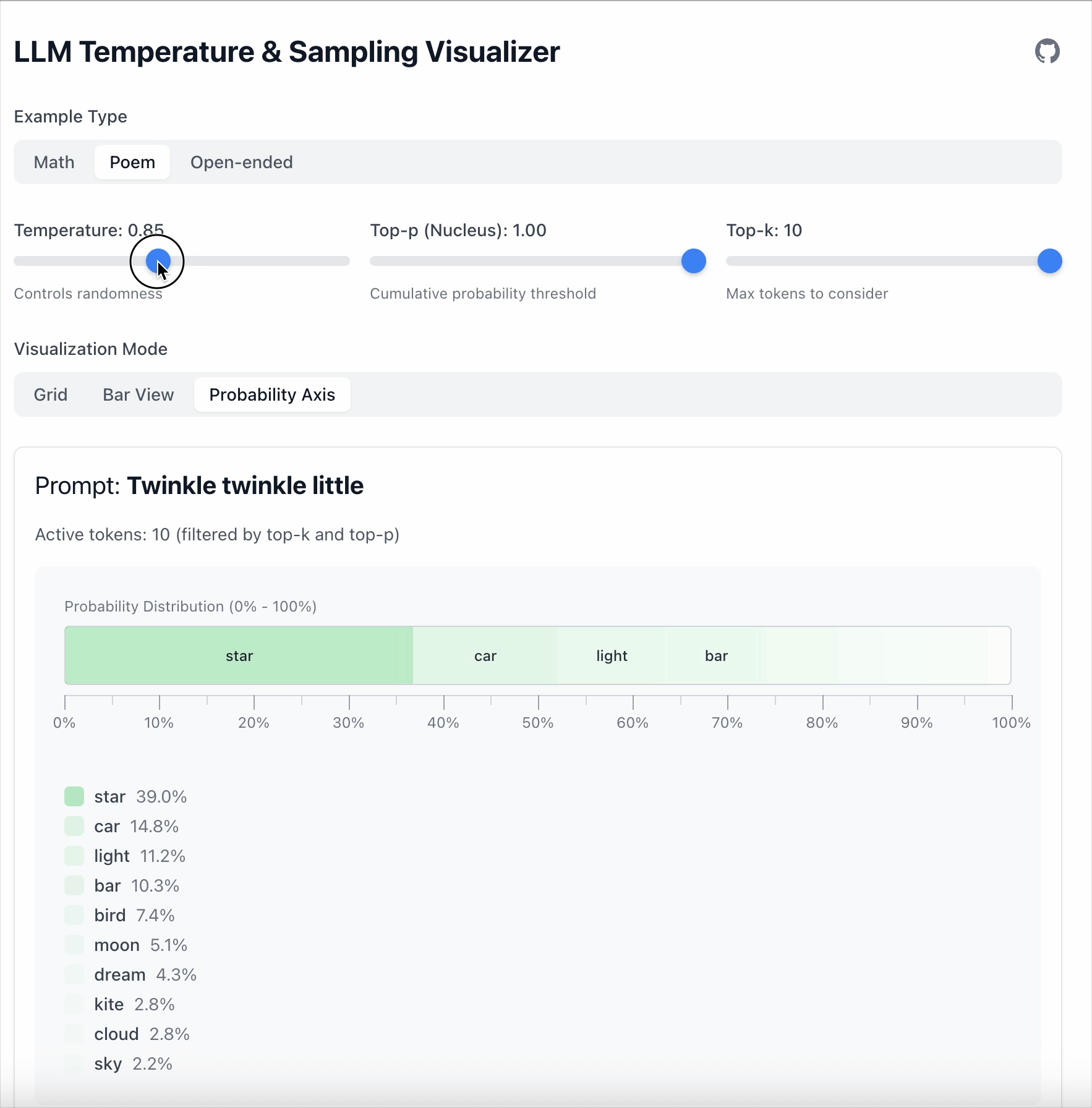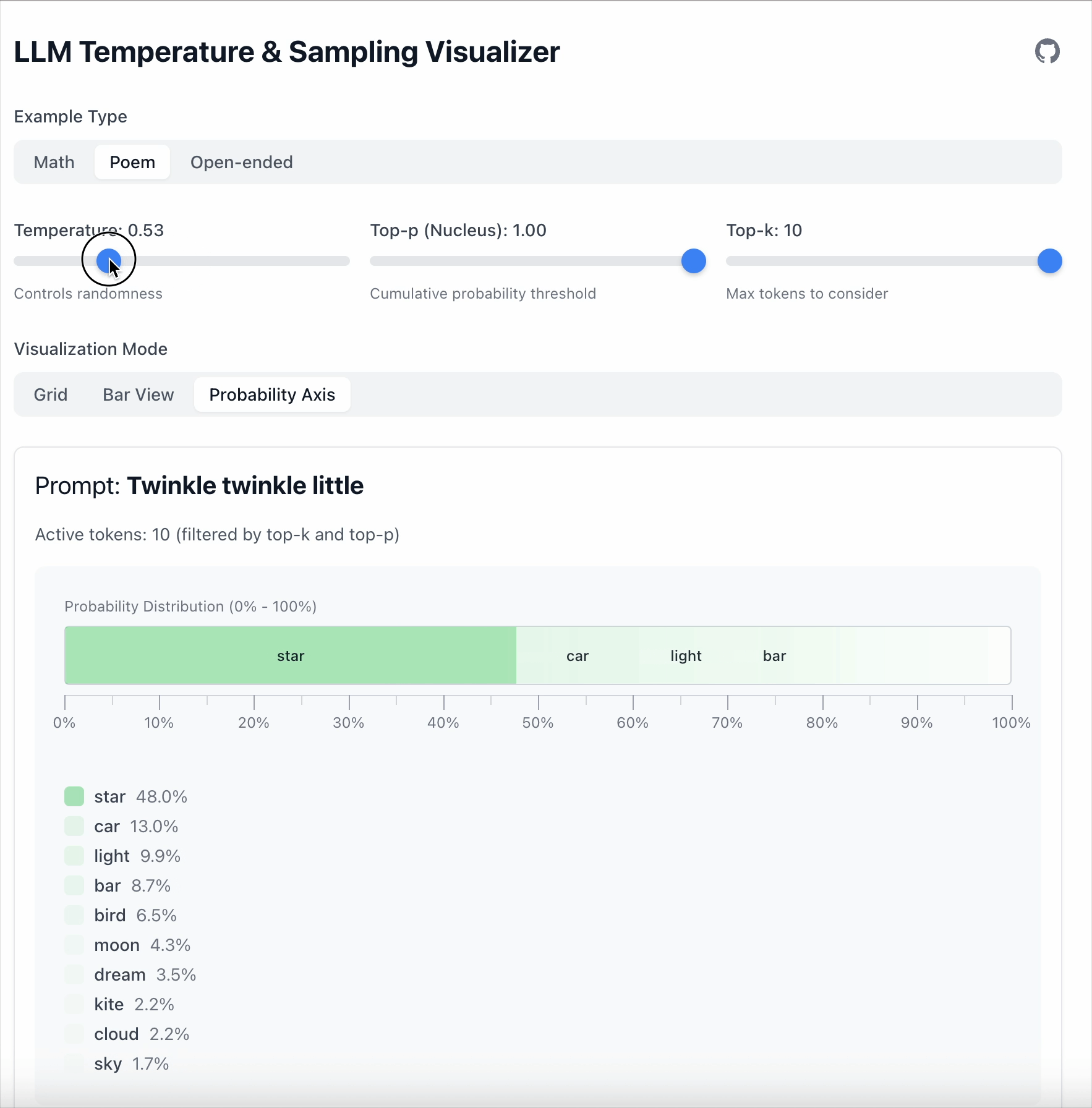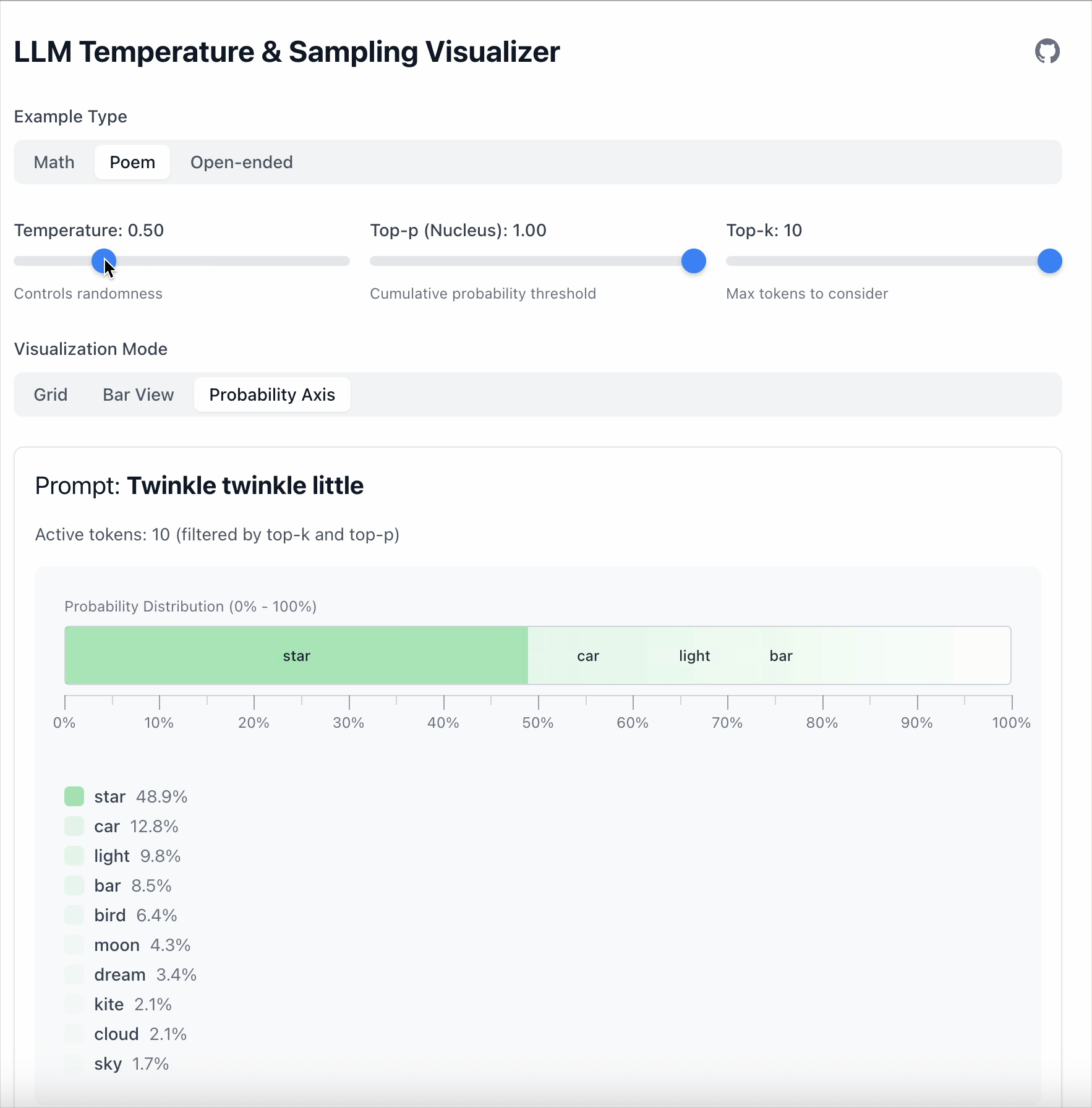
在本例中,“star” 与 “car” 之间的差距是 19.6。
- 当 Temperature = 0.5 时,差距扩大到 36.1。
- 当 Temperature = 1.68 时,低概率 token 变得更具竞争力。
关键点: 温度不会删除 token,只是改变模型对不同 token 的偏好强度。
Top‑p(核采样)
Top‑p 控制 保留多少概率质量。过程很直接:
- 从概率最高的 token 开始。
- 不断加入 token,直到累计概率 ≥ Top‑p。
- 丢弃其余 token。
当 Top‑p = 0.6 时,只保留覆盖 60 % 总概率的 token。
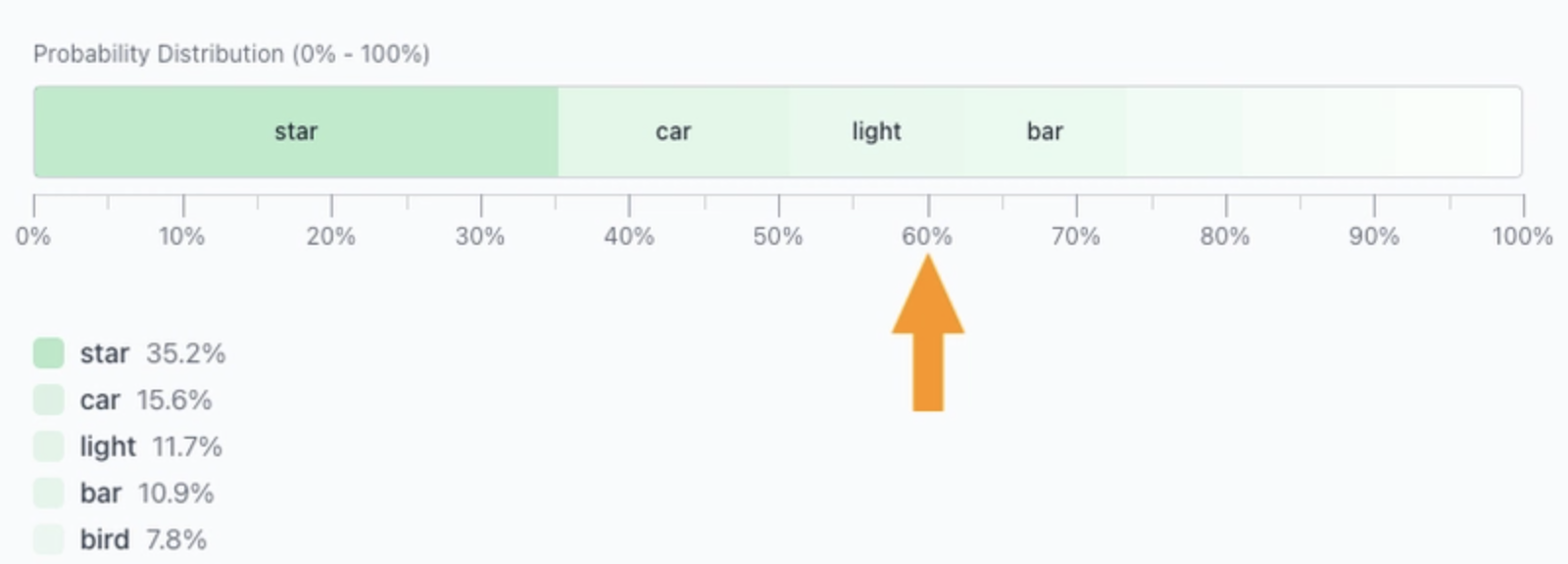
剩余的 token 随后会重新归一化:
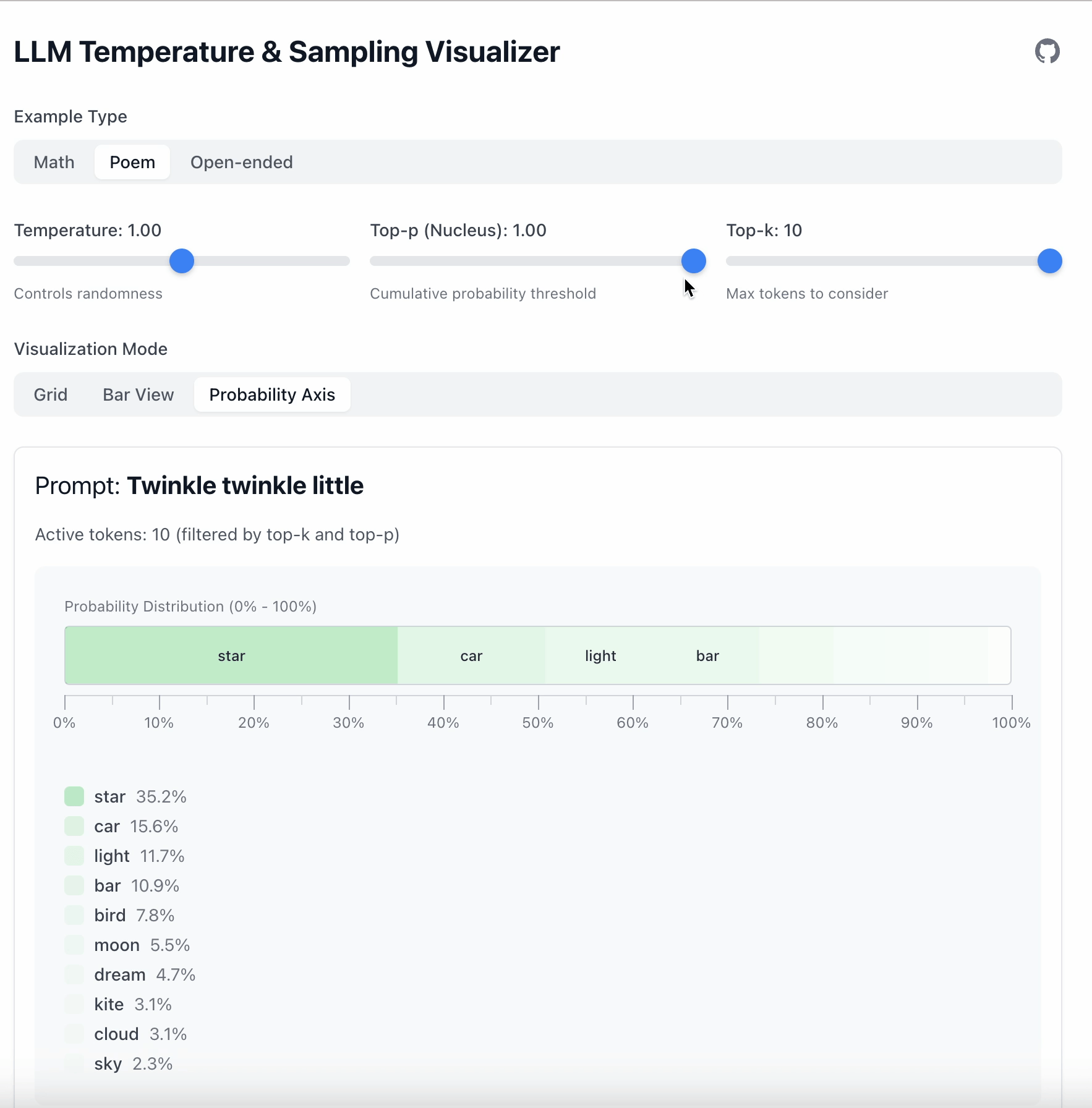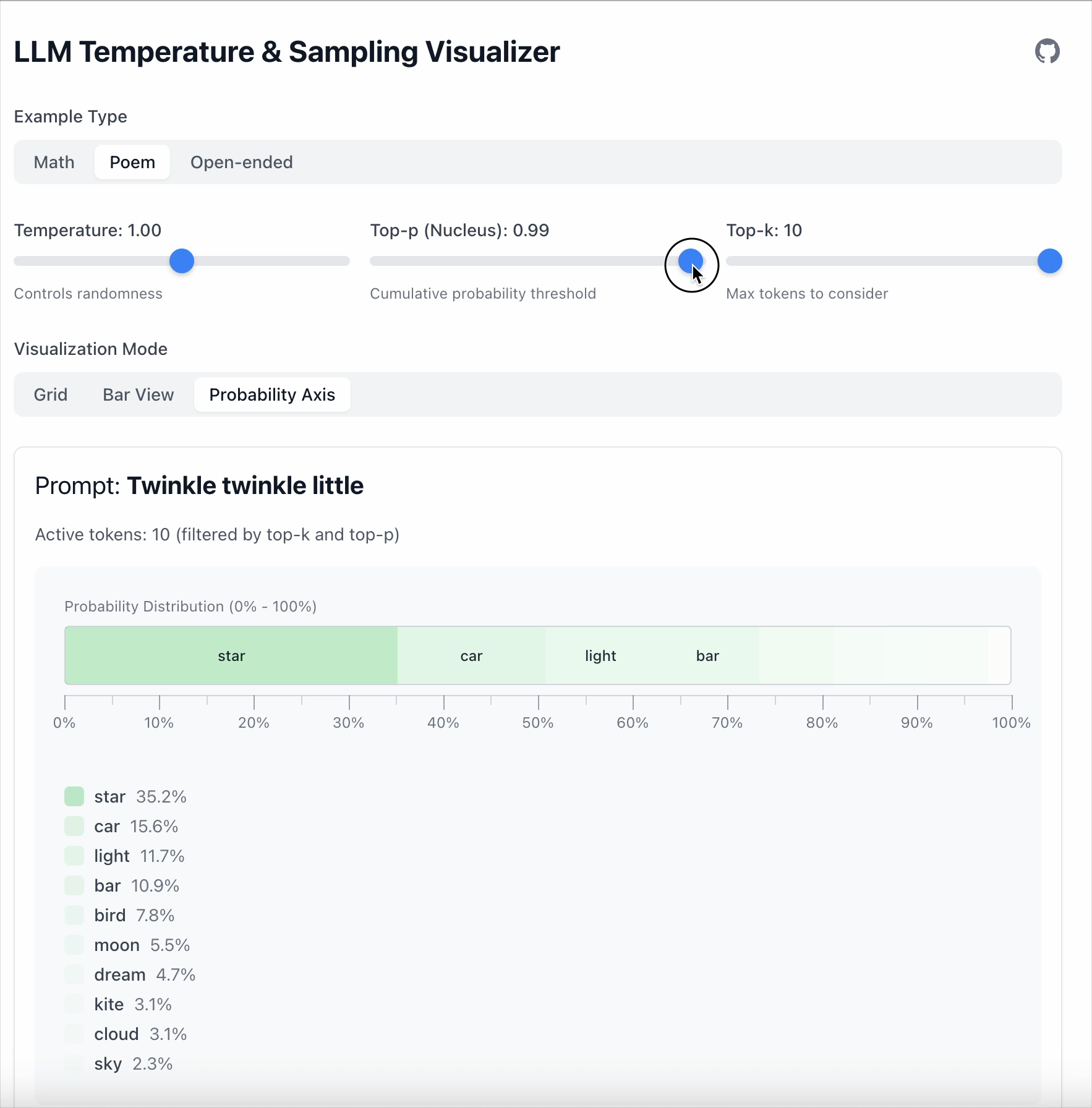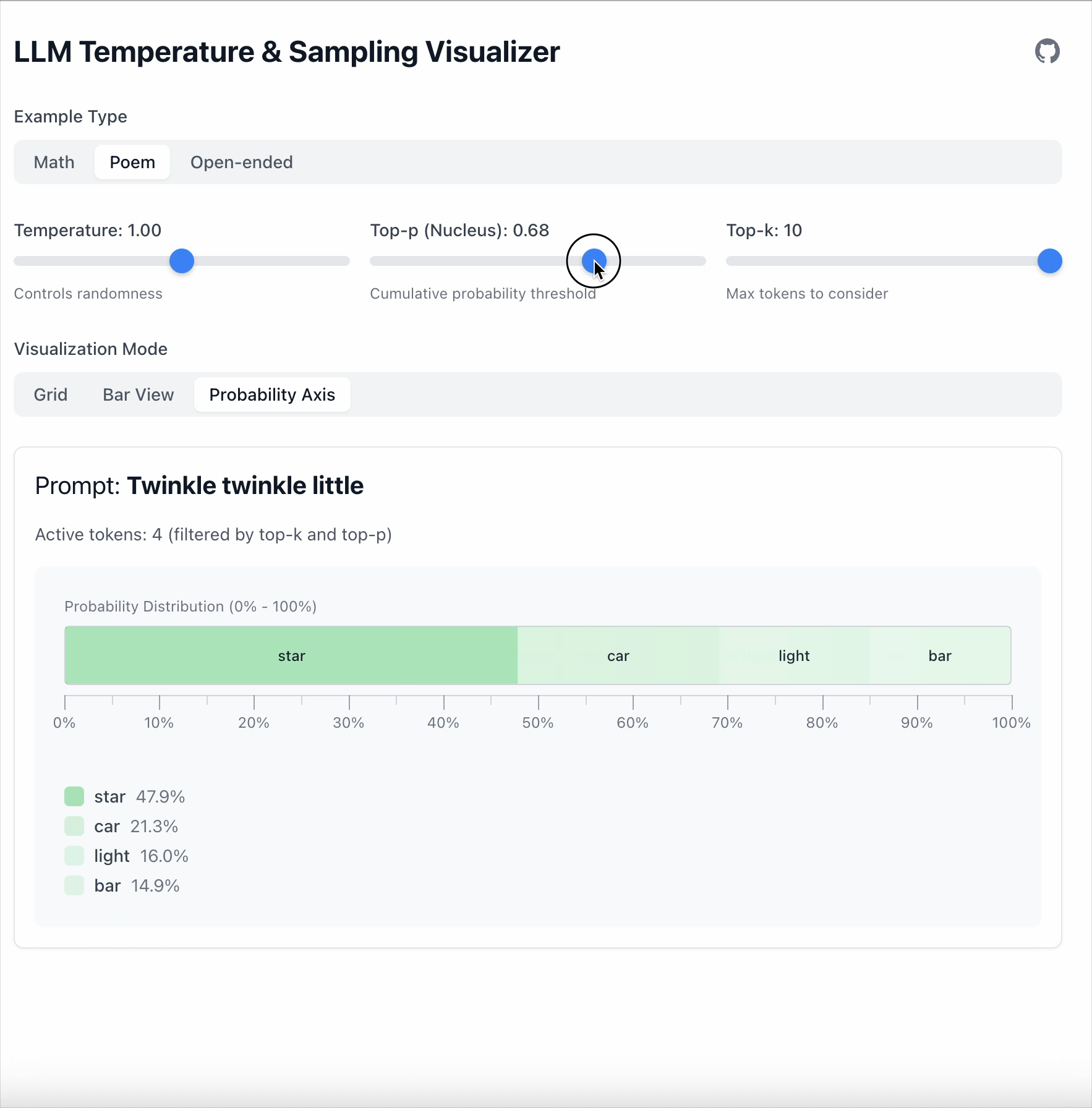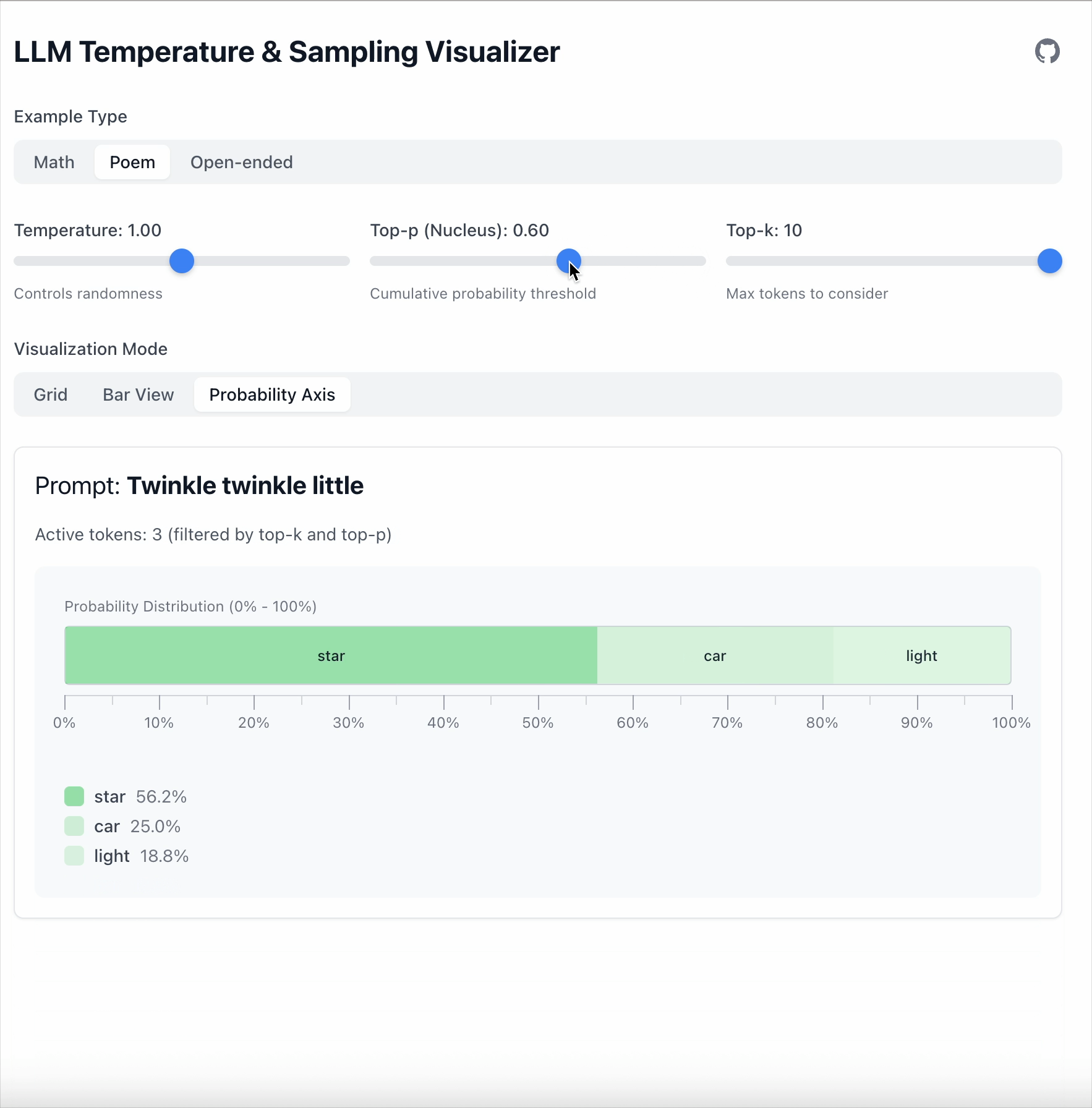
- token 的数量是动态的。
- 分布越尖锐,保留的 token 越少。
Top‑k
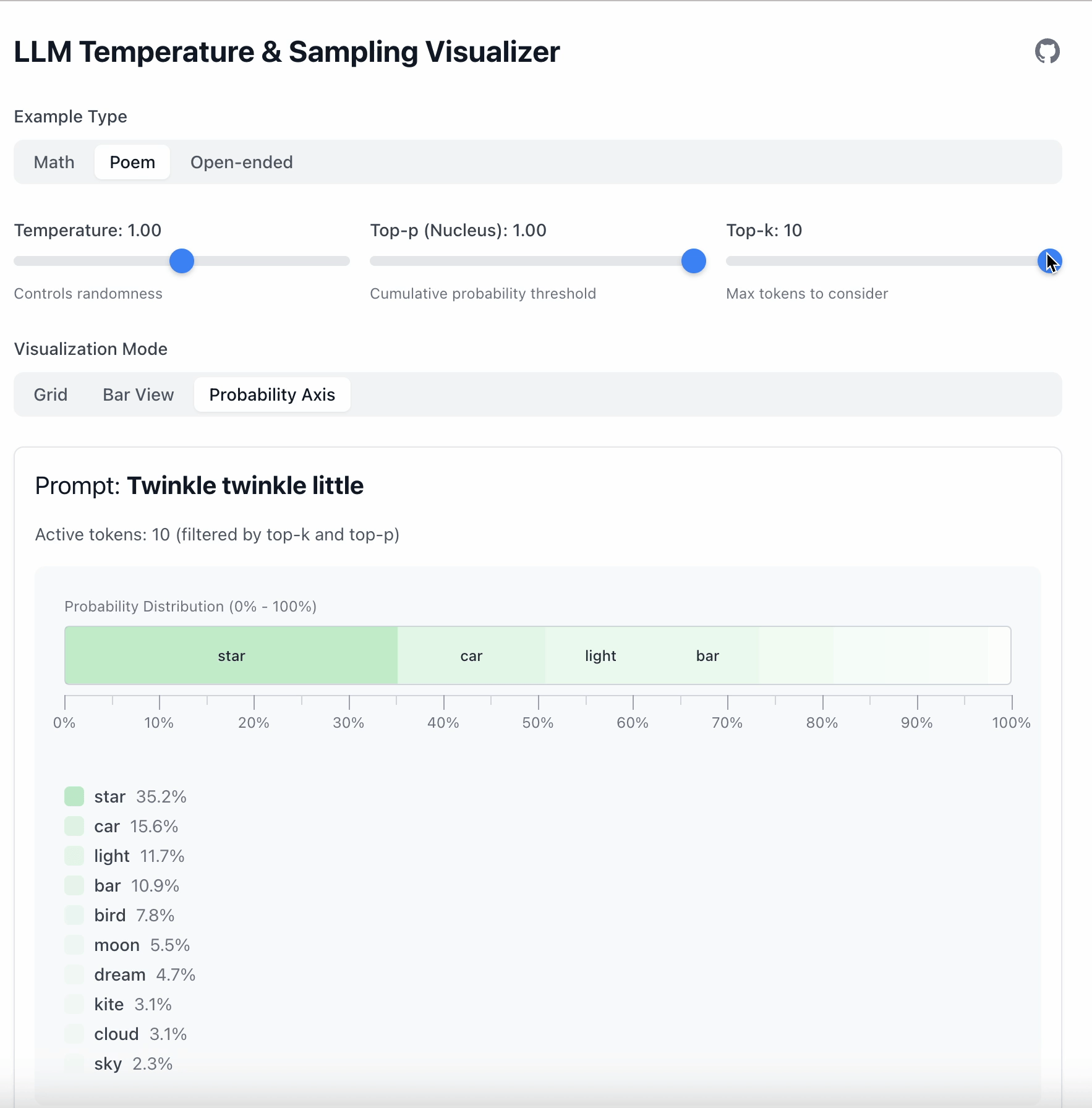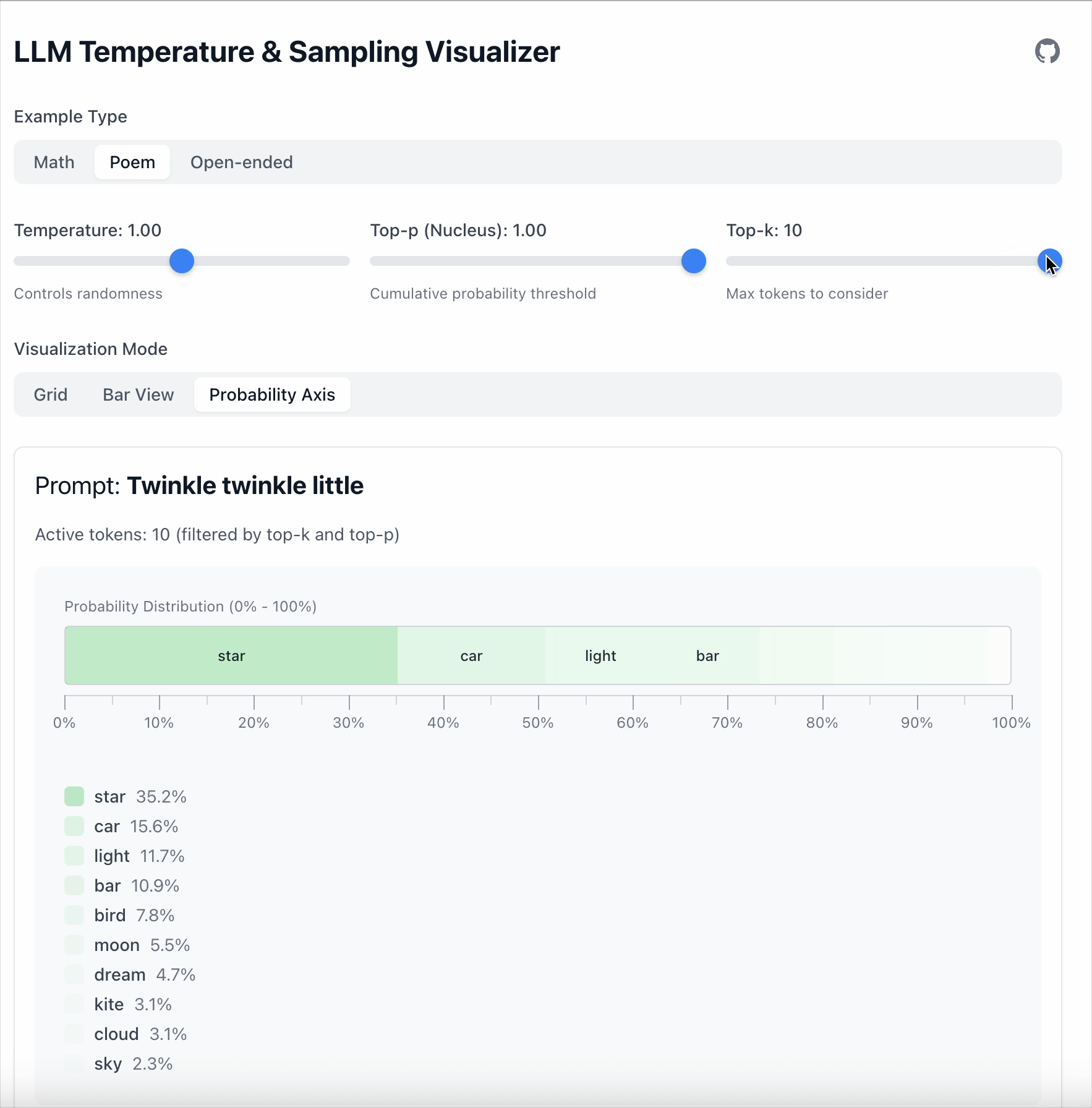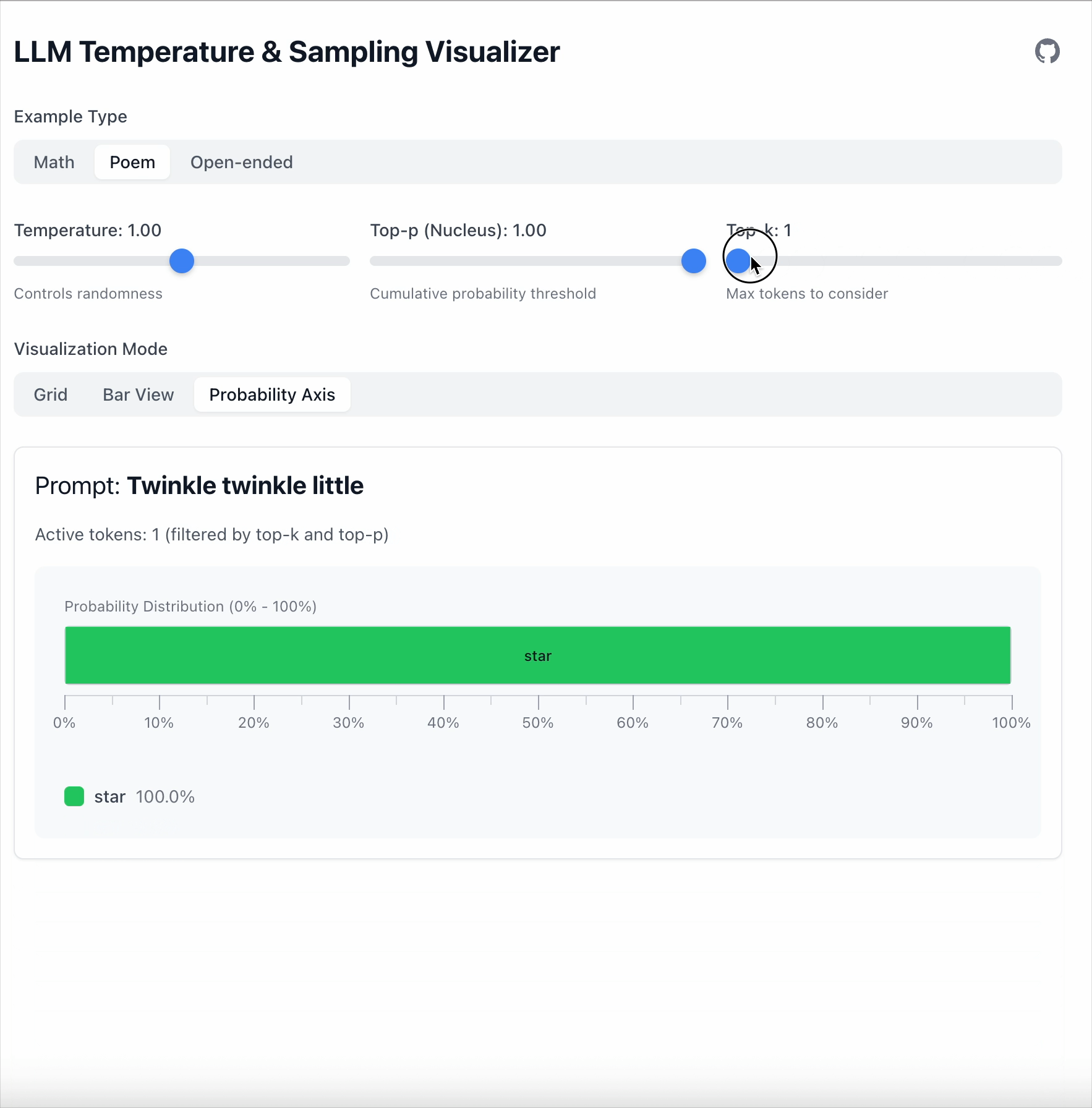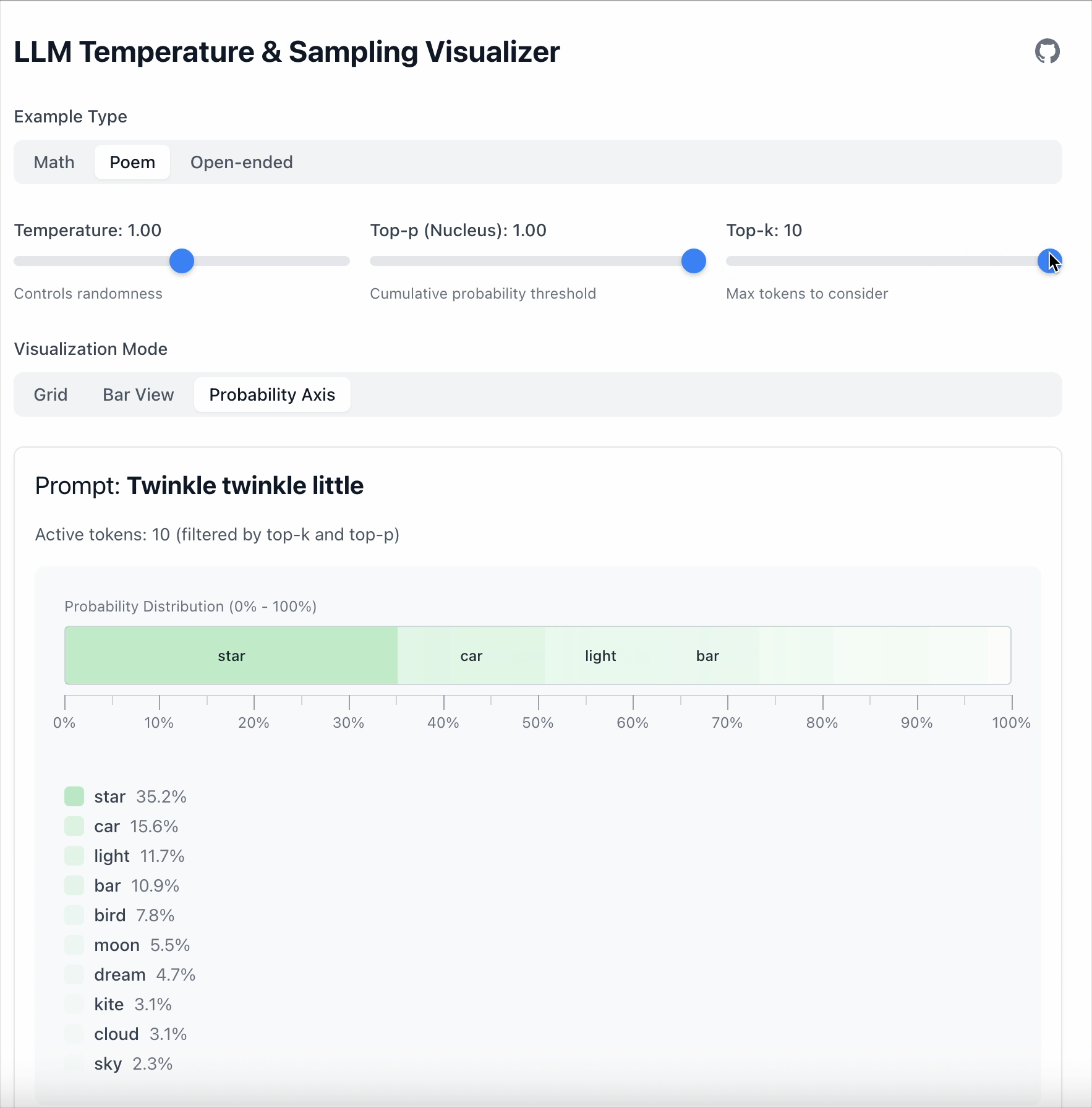
Top‑k 更简单:只保留前 K 个 token。
- Top‑k = 1 → 总是选取概率最高的 token。
- Top‑k = 5 → 从前 5 个 token 中采样。
- 其余全部忽略。
一句话概括:
- Top‑k 限制数量。
- Top‑p 限制概率质量。
演示
本文中的所有可视化均来自 LLM Sampling Visualizer:
👉
如果采样参数感觉抽象,花五分钟使用这个工具可以比阅读更多文字更快建立直观感受。