使用 LiteRT 解锁 Qualcomm NPU 的峰值性能
Source: Google Developers Blog
现代智能手机配备了复杂的 SoC(系统级芯片),包括 CPU、GPU 和 NPU,使得在设备端实现的生成式 AI(GenAI)体验比仅靠服务器的方案更具交互性和实时性。GPU 是最常见的 AI 加速器,约有 90 % 的 Android 设备配备了它。然而,仅依赖 GPU 会导致性能瓶颈,尤其是在构建复杂、交互式的 GenAI 体验时。
想象一下,一款计算密集型的文本到图像生成模型在设备上运行,同时还要处理实时摄像头画面并进行基于机器学习的分割。即使是最强大的移动 GPU 也会在这种组合负载下捉襟见肘,导致画面卡顿,用户体验受损。

NPU(神经处理单元)是一种高度专用的处理器,提供 数十 TOPS(每秒万亿次运算)的 AI 计算能力——远超现代移动 GPU 的承载上限。它在每 TOP 的 功耗效率 也显著优于 CPU 和 GPU,这对电池供电的设备至关重要。超过 80 % 的最新 Qualcomm SoC 已内置 NPU。NPU 与 GPU、CPU 并行工作,承担重度 AI 计算任务,释放 GPU 用于渲染,CPU 用于主线程逻辑。这种并发实现了现代 AI 应用所需的流畅、响应式性能。
引入 LiteRT Qualcomm AI Engine Direct 加速器
为了将 NPU 能力引入 LiteRT(Google 的高性能设备端 ML 框架),我们宣布 LiteRT Qualcomm AI Engine Direct(QNN)加速器,该加速器由 Google 与 Qualcomm 合作开发,取代了之前的 TFLite QNN delegate。
统一且简化的移动部署工作流
开发者不再需要:
- 与低层、厂商特定的 SDK 打交道。LiteRT 与 SoC 编译器和运行时集成,提供统一、简洁的 API。
- 针对单个 SoC 版本进行适配。LiteRT 抽象了不同 SoC 之间的碎片化,提供单一工作流,可一次性面向多款设备部署。
模型可以通过提前编译(AOT)或设备端编译的方式,在所有受支持的设备上部署,简化了从 Qualcomm AI Hub 等渠道获取的预训练 .tflite 模型的集成。
业界领先的设备端性能
该加速器支持广泛的 LiteRT ops,最大化 NPU 利用率,实现 完整模型委托——这是获得最佳性能的关键。它包含针对大型语言模型(LLM)和生成式 AI 模型的专用内核和优化,为 Gemma、FastVLM 等模型提供 SOTA(业界最新)性能。
卓越性能,真实世界成果
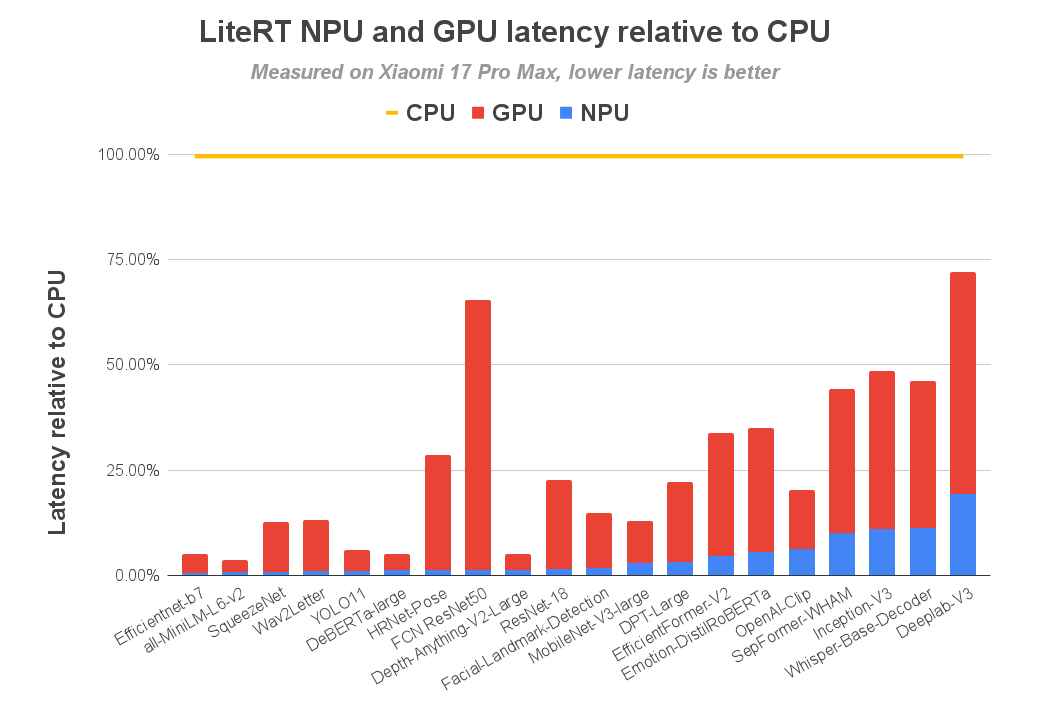
我们在 72 个典型的 ML 模型(视觉、音频、NLP)上对新 LiteRT QNN 加速器进行了基准测试。亮点如下:
- 相比 CPU 提升 最高 100 倍,相比 GPU 提升 最高 10 倍。
- 支持 90 种 LiteRT ops,使 72 个模型中有 64 个 能够完整委托给 NPU。
- 在 Snapdragon 8 Elite Gen 5 上,56 个模型的推理时间低于 5 ms(使用 NPU),而 CPU 只能让 13 个模型达到该水平。
释放 NPU 在 LLM 推理中的全部潜能
我们使用 LiteRT 对 FastVLM‑0.5B 研究模型(业界最先进的设备端视觉模型)进行 AOT 编译和 NPU 推理基准测试。
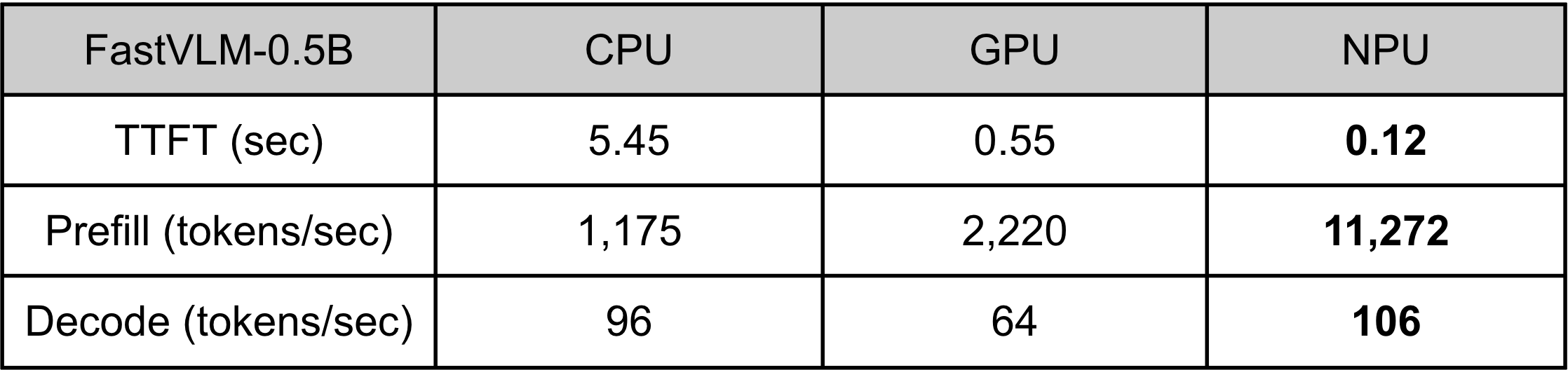
该模型采用 int8 权重量化 与 int16 激活量化,从而激活 NPU 的高速 int16 内核。我们还为性能关键的 Transformer 层(尤其是 Attention 机制)添加了 专用 NPU 内核,确保高效执行。
在 Snapdragon 8 Elite Gen 5 NPU 上,FastVLM 达到:
- 首 token 响应时间(TTFT): 0.12 s(针对 1024×1024 图像)。
- 预填充阶段吞吐量 > 11 000 token/s。
- 解码阶段吞吐量 > 100 token/s。
这些吞吐量足以支撑流畅的实时交互体验,已在现场理解演示中实现,对周围环境进行实时处理和描述。
3 步快速上手
使用 LiteRT 的统一工作流,在不同 Qualcomm SoC 版本上将 .tflite 模型部署到 NPU。可从 Qualcomm AI Hub 下载预训练的生产级模型。
-
(可选)针对目标 SoC 进行 AOT 编译
离线编译.tflite模型,以降低设备端初始化时间和峰值内存占用,尤其是大模型。使用主机上的 LiteRT 为所有受支持的 SoC 或特定版本进行编译。 -
部署已编译的模型
将编译产物拷贝到 Android 设备,并通过 LiteRT 的运行时 API 加载。框架会在可用时自动选择 NPU delegate。 -
运行推理
在设备端执行模型。LiteRT 负责张量分配、内存管理以及 NPU 执行,提供上述性能提升。