UC San Diego 实验室借助 NVIDIA DGX B200 系统推进生成式 AI 研究
Source: NVIDIA AI Blog
2025年12月17日,作者 Zoe Kessler

Hao AI 实验室如何使用 DGX B200?

Hao AI 实验室成员与 NVIDIA DGX B200 系统合影。
随着 DGX B200 现已全面向 Hao AI 实验室以及加州大学圣地亚哥分校计算、信息与数据科学学院的 San Diego Supercomputer Center 社区开放,研究机会无限。
“DGX B200 是 NVIDIA 迄今为止最强大的 AI 系统之一,这意味着它的性能位居全球前列,” 加州大学圣地亚哥分校 Halıcıoğlu 数据科学研究所和计算机科学与工程系助理教授 Hao Zhang 说。 “它让我们能够比使用前代硬件更快地进行原型设计和实验。”
DGX B200 加速的项目
-
FastVideo – 训练一系列视频生成模型,能够在 五秒 内根据文本提示生成五秒钟的视频。研究阶段同样使用 NVIDIA H200 GPU 与 DGX B200 配合。
-
Lmgame‑bench – 一个基准测试套件,将大型语言模型(LLM)与流行的在线游戏(如 Tetris 和 Super Mario Bros)进行对决。用户可以评估单个模型,或让两个模型相互竞争以比较性能。
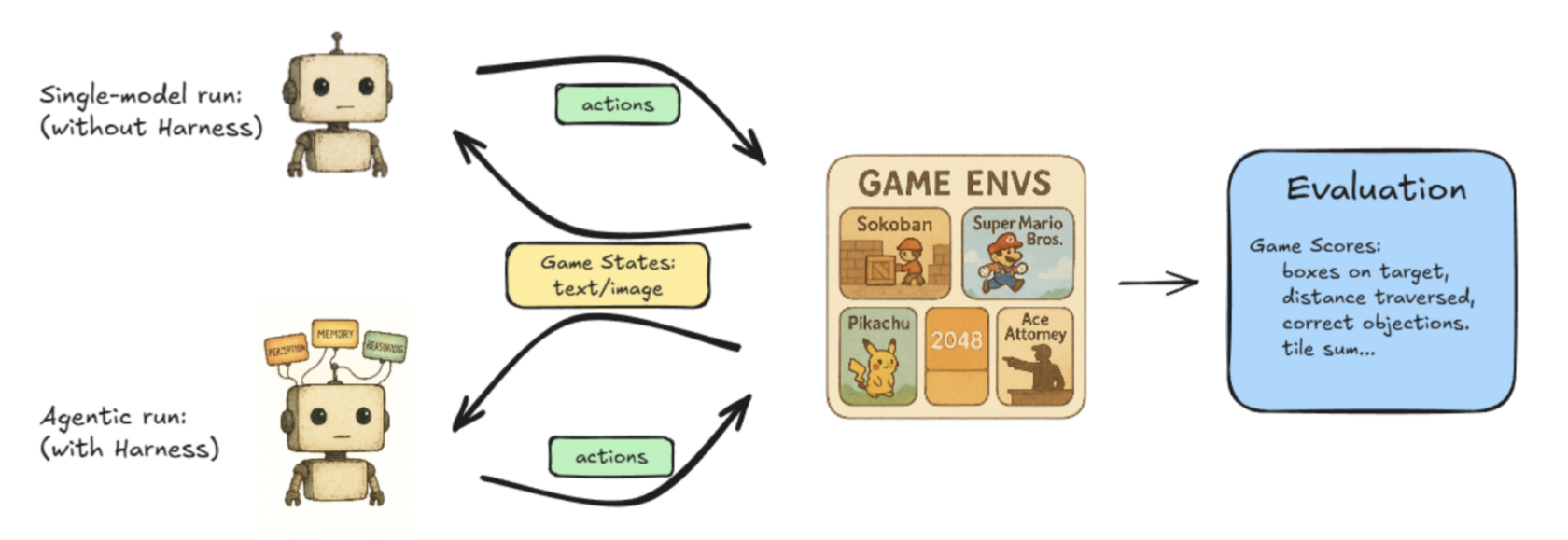
Hao AI 实验室的 Lmgame‑Bench 项目的示意工作流。 -
低延迟 LLM 服务 – 正在进行的工作探索在大型语言模型上实现实时响应的新技术。
“我们目前的研究利用 DGX B200 探索低延迟 LLM 服务的下一前沿,得益于系统提供的强大硬件规格,” 加州大学圣地亚哥分校计算机科学博士生 Junda Chen 说。
DistServe 对去耦合推理的影响
Disaggregated inference 使大规模 LLM 服务引擎能够在保持 用户感知延迟 在可接受范围内的同时,最大化 整体系统吞吐量。
为什么去耦合推理很重要
- 优化“goodput” 而不是单纯的原始吞吐量。
- 将系统性能与真实用户体验对齐。
吞吐量 vs. Goodput
| 指标 | 定义 | 捕获的内容 | 权衡 |
|---|---|---|---|
| Throughput(吞吐量) | 整个系统每秒生成的 tokens 数量。 | 成本效率(tokens / $)。 | 忽略延迟;更高的吞吐量可能会增加用户感知的延迟。 |
| Goodput(有效吞吐) | 在满足用户指定的延迟目标(SLO)的前提下的吞吐量。 | 同时考虑成本效率 和 服务质量。 | 在速度与响应性之间取得平衡,提供更全面的系统健康视图。 |
关键要点
- 单纯的 Throughput 不足以反映用户实际体验的延迟。
- Goodput 融入了延迟约束,是 LLM 服务工作负载的更优度量。
- 通过聚焦 goodput,DistServe 实现了 最佳效率 和 理想的模型输出,而不牺牲用户体验。
开发者如何实现最佳 Goodput?
当用户在 LLM 系统中发出请求时,系统会获取用户输入并生成第一个 token(prefill)。随后,它会一次又一次地生成输出 token,基于过去请求的结果预测每个 token 的后续行为。这个过程称为 decode。

历史上,prefill 和 decode 通常在同一块 GPU 上运行,但 DistServe 背后的研究人员发现,将它们拆分到不同的 GPU 上可以最大化 goodput。
“之前,如果把这两个任务放在同一块 GPU 上,它们会相互竞争资源,这会导致从用户角度来看变慢,”陈说。“现在,如果我把任务拆分到两套不同的 GPU——一套负责计算密集型的 prefill,另一套负责内存密集型的 decode——我们就可以根本消除两者之间的干扰,使两个任务都运行得更快。”
这个过程被称为 prefill/decode 解耦,即将 prefill 与 decode 分离以获得更高的 goodput。
- 提高 goodput 并使用解耦推理方法可以在不牺牲低延迟或高质量模型响应的前提下,实现工作负载的持续扩展。
- NVIDIA Dynamo —— 一个开源框架,旨在以最低成本实现最高效率的生成式 AI 模型加速和扩展 —— 支持解耦推理的规模化。
除了这些项目之外,UC San Diego 正在进行跨部门合作(例如在医疗保健和生物学领域),利用 NVIDIA DGX B200 进一步优化一系列研究项目,研究人员持续探索 AI 平台如何加速创新。
了解更多关于 NVIDIA DGX B200 系统的信息。
分类与标签
分类:
标签:
相关 NVIDIA 新闻
| 图片 | 标题 |
|---|---|
 | 如何使用 Unsloth 在 NVIDIA GPU 上微调 LLM |
 | 为 AI 干杯:ADAM 机器人调酒师在拉斯维加斯金骑士比赛上调制饮品 |
 | 随着 AI 越来越复杂,模型构建者依赖 NVIDIA |
 | 在云端与卡普空的《怪物猎人故事》系列一起踏上冒险之旅 |
 | 可选的 NVIDIA 软件实现数据中心舰队管理 |
敬请关注 NVIDIA 在 AI 创新和研究突破方面的更多更新。