将分散的知识转化为可信的智能:Stack Internal 2026.3
Source: Stack Overflow Blog
2026年4月28日

采集功能现已正式发布
您已经在 Stack Internal 打下了坚实的基础,但要通过新内容进行刷新并让其他部门加入,不应成为手动的障碍。采集功能现在可以让您快速为实例注入结构化、已验证的知识,这些知识否则会在各自的工具中形成信息孤岛。
但此版本不仅仅是为了节省时间,更是为了让您的技术上下文对需要它的工具可访问。通过提供持续的专家审阅知识流,采集引擎确保您的 AI 工具真正可靠,减少将资深工程师从高价值工作中拉走的重复“肩膀拍打”。
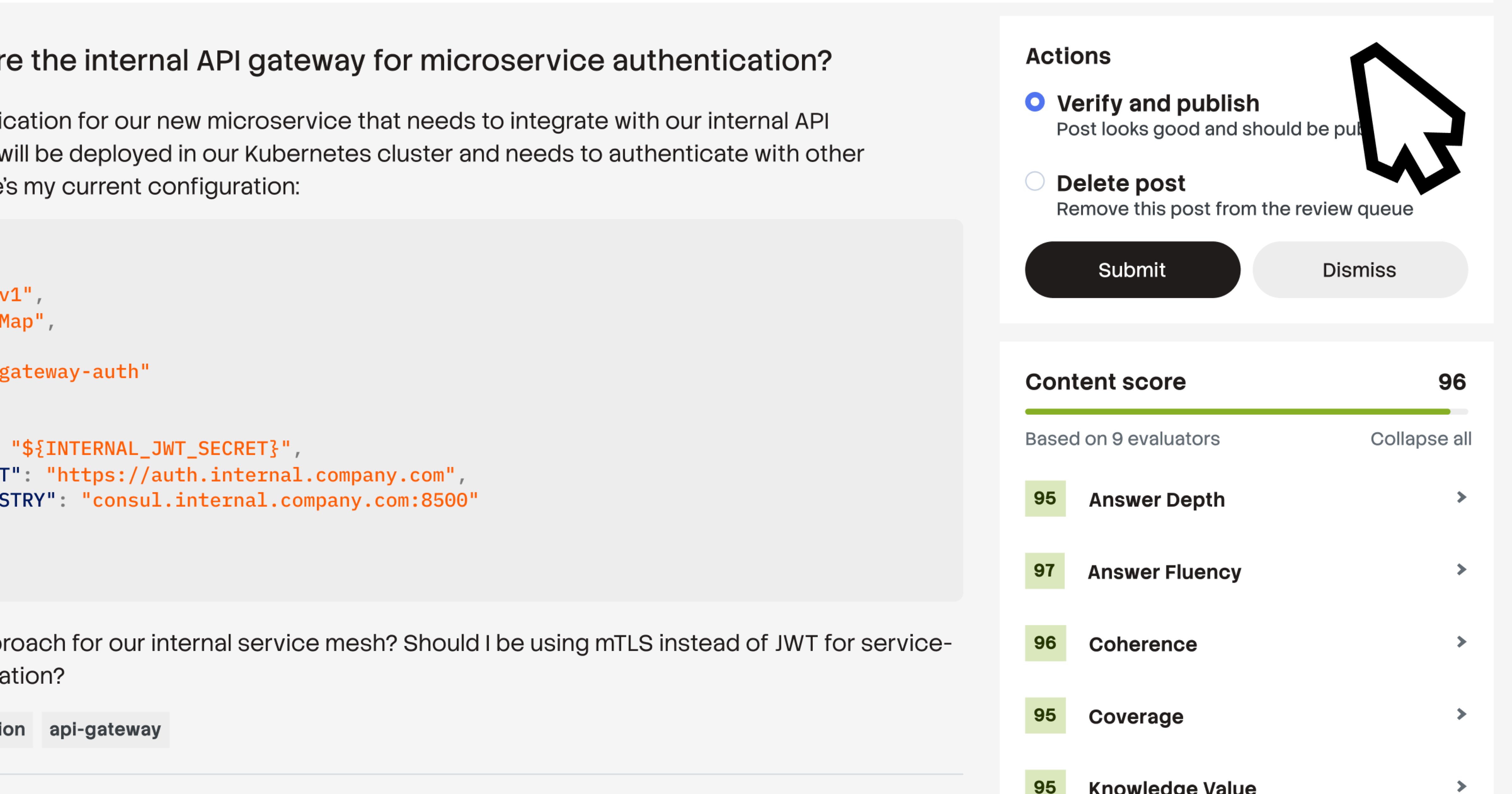
将噪声转化为高信号帖子
采集的 AI 流程会智能地对原始文本进行分块、清洗并转换为结构化、原子化的问答对。这些帖子会自动标记、映射到用户,并在路由给专家进行最终审查前进行置信度打分。通过将碎片化、非结构化的内容转化为已验证的知识单元,您的机构数据既适用于人工发现,也适用于 AI 检索。
大规模摄取孤立内容
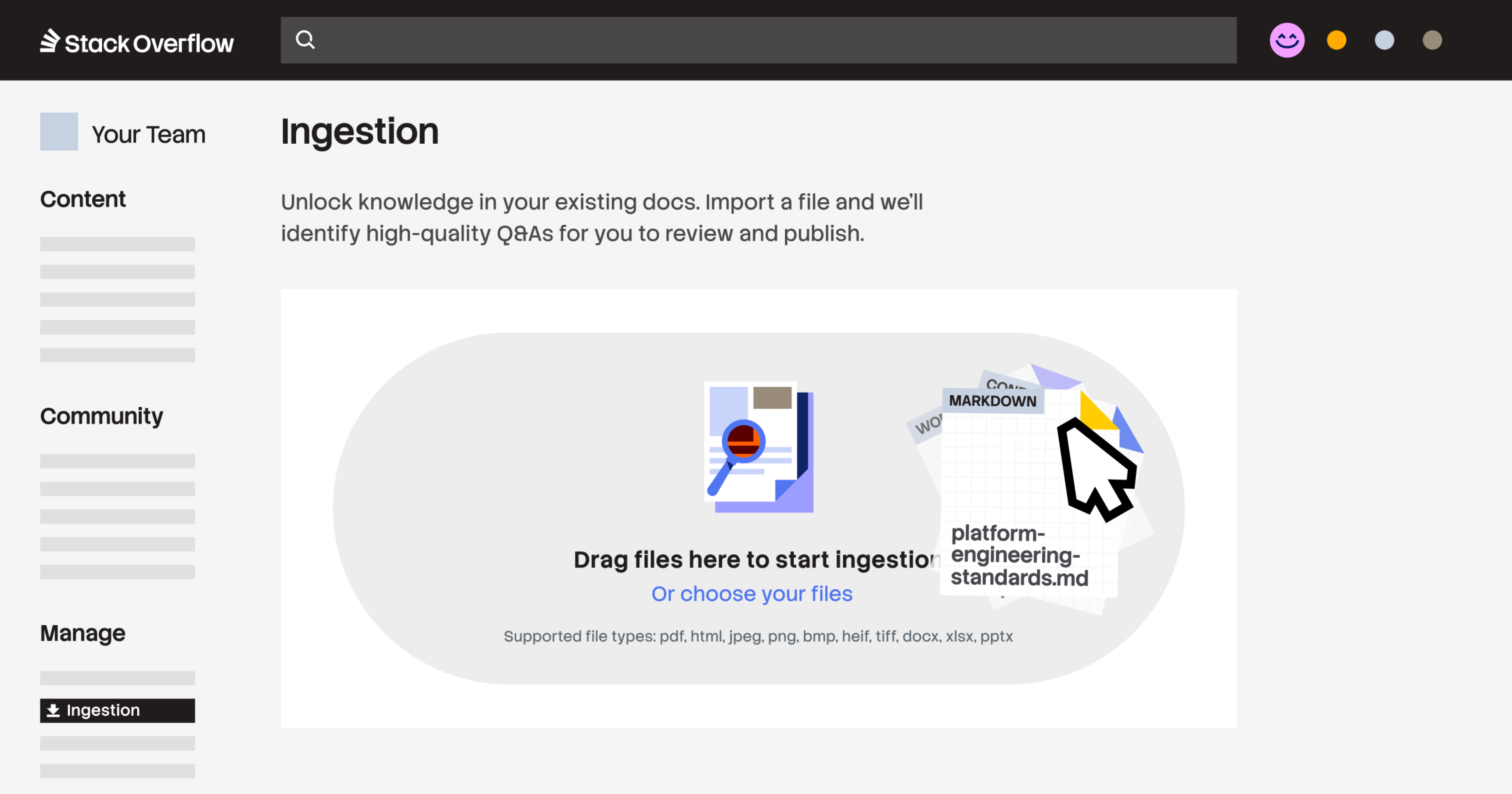
采集支持上传 PDF、HTML、Markdown 文件、图片(.jpeg、.jpg、.png、.bmp、.heif、.tiff)以及 Microsoft Office 文档(.docx、.xlsx、.pptx)。您可以通过 POST /ingest/file API 端点自动化大批量迁移,或直接将文件拖拽到网页界面中。这几乎瞬间将组织各处的原始数据集中并结构化到一个已验证的位置。
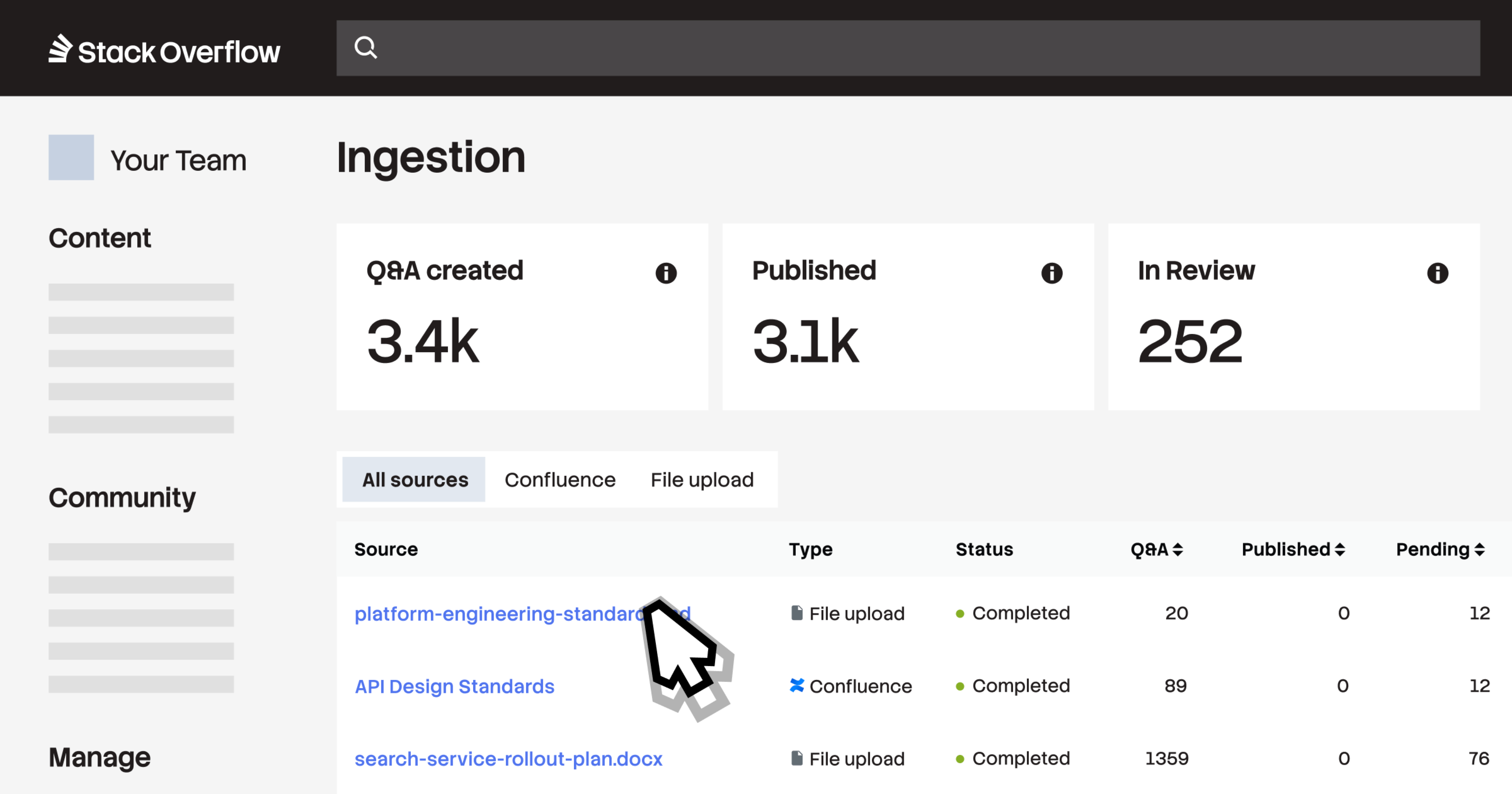
让主题专家进行验证,而非策划
采集引擎通过预结构化、标记和置信度打分自动生成问答对的“第一稿”,使主题专家(SME)、管理员和版主能够直接进入高质量内容的批准环节,而无需从头编写。通过将工作负载从手动策划转向专家验证,您可以确保只有可信的知识进入团队和 AI 工具。
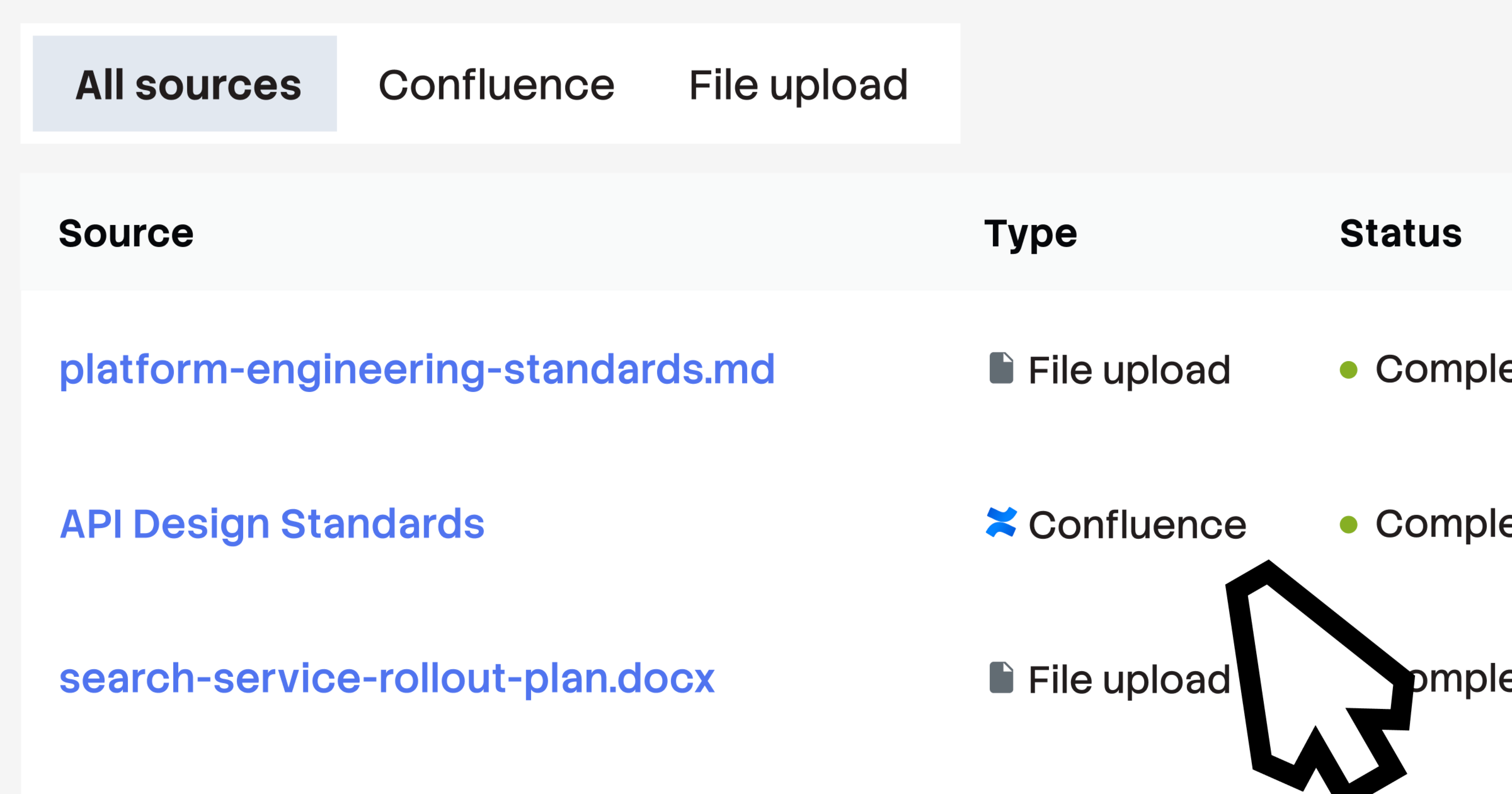
激活您的 Confluence 数据
此版本还包含一个 Confluence Cloud 连接器,可让您将 Stack Internal 直接连接到选定的 Confluence 空间。连接后,采集引擎会将静态、长篇的 Confluence 页面转换为 SME 验证的问答对,便于大规模发现、信任和维护。每个生成的帖子都包含指向原始 Confluence 页面 的直接链接。
使用 MCP 关闭上下文循环
一旦验证并发布,所有转换后的问答帖子都可通过 Stack Internal MCP 服务器在您的 AI 工具和 IDE 中访问。这将在团队已有的工作环境中呈现专家审阅的上下文,确保摄取的数据被主动更新并用于推动更好的技术决策和智能输出。
获取访问权限并了解更多
要开始使用 Ingestion,请在管理员设置中启用它(有关详细信息,请参阅此指南)。所有客户每月可免费获得 100 Knowledge Objects(已批准的问答对)。如需更大容量,请联系您的 Stack Overflow 客户代表。
想了解 Stack Internal 2026.3 版本更新的更多信息,请阅读发行说明。