TIL:真实世界的分布式系统中的拜占庭将军问题
发布: (2026年1月12日 GMT+8 00:02)
3 分钟阅读
原文: Dev.to
Source: Dev.to

前言
在学习 Raft 算法时,拜占庭故障通常被排除在外。出乎意料的是,CloudFlare 去年十一月的事故报告把真实世界的拜占庭问题作为标题。我将借此整理一些思考。
什么是拜占庭故障
在分布式系统中,不同计算机之间通过 共识通信 数据确认过程进行交互。它要求计算机报告它们将要执行的操作或为某个 leader 投票。
如果一台计算机向一部分成员 A 说了一件事,而向另一部分成员 B 说了另一件事,导致整个群体无法达成共识或进入意外状态,这就称为 拜占庭故障。
许多共识算法(如 Paxos、Raft)最初假设不存在拜占庭故障,因为处理它们会把共识的复杂度提升到另一个层次。
参考文章
关于 CloudFlare 的恢复机制
在探讨更复杂的问题之前,CloudFlare 的事故报告中有一个有趣的视角:他们如何看待系统维护的备份机制。
服务备份机制
- 每项服务是一系列机架服务器。
- 每台机器有两个交换机。
- 每个机架有两个或以上的电源供电设备。
- 每台服务器使用 RAID‑10 备份机制(RAID 1 + RAID 0)。
- 每个机架至少包含三台机器。
发生的问题
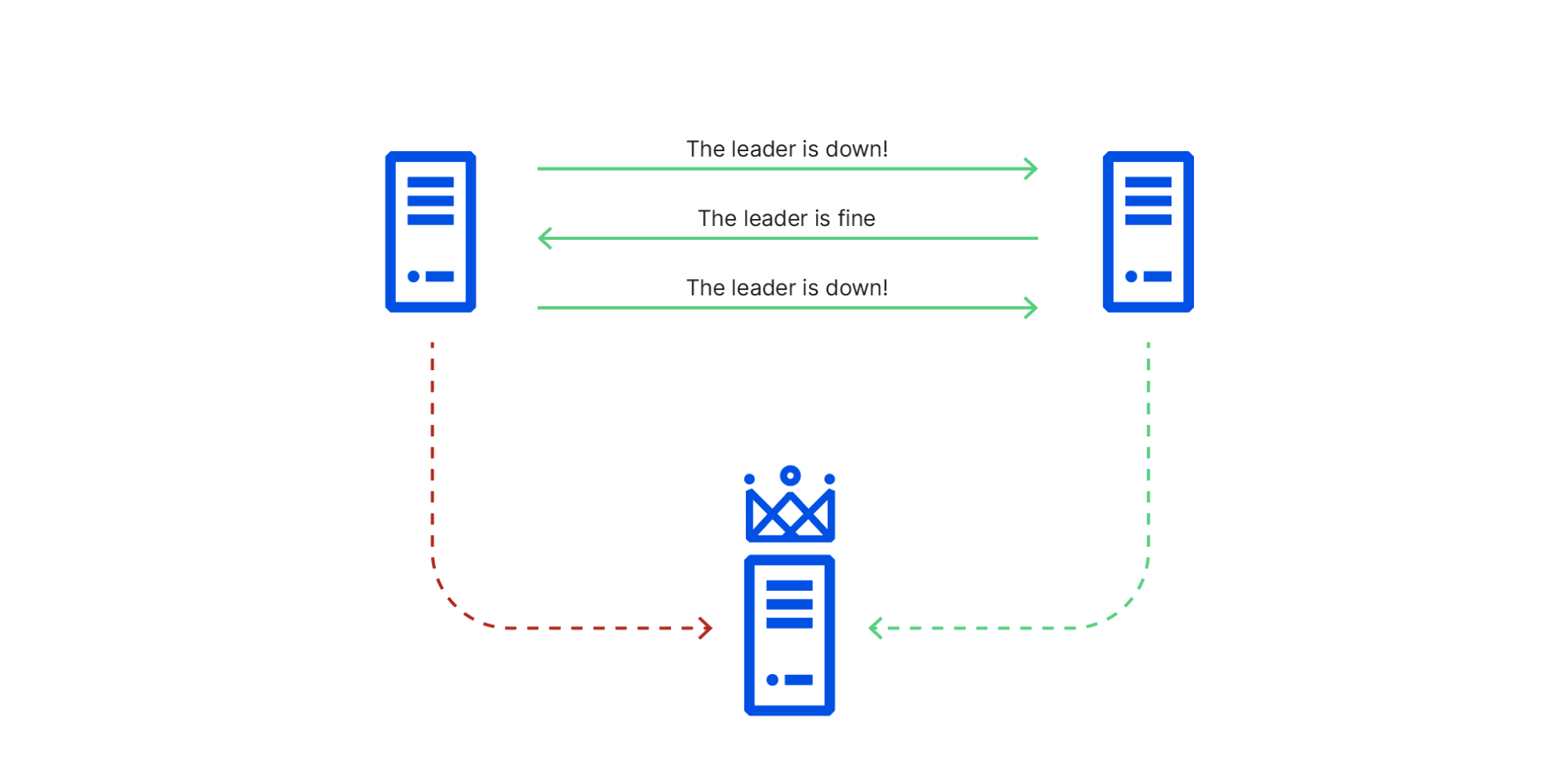
图片说明:左上为 Server 1,右上为 Server 2,下方为 Server 3,且 Server 3 也是 Leader。
- Server 1 与 Server 2 之间的网络问题导致它们的信息不一致。
- Server 1 认为 Leader(Server 3)已离线。
- Server 2 认为 Leader 正常运行。
- 正是这种不一致让 CloudFlare 将该事件标记为 拜占庭故障。
参考
- Cloudflare Dashboard and Cloudflare API service issues
- A Byzantine failure in the real world (Cloudflare blog)
- Raft does not Guarantee Liveness in the face of Network Faults
- Wiki: Byzantine Generals Problem (Chinese)
- Raft lecture (Raft user study) by Diego Ongaro
- The Cloudflare Blog
- Improving the Resiliency of Our Infrastructure DNS Zone
- Link aggregation – Wikipedia
- The power of the adversary
- Pull requests · etcd-io/etcd
- Understanding the Byzantine Generals’ Problem (Medium)
- 拜占庭將軍問題 – 維基百科 (Chinese)
- Raft Consensus Algorithm