是时候在2026年了解Google TPU了
Source: Dev.to
是时候在 2026 年学习 Google TPU 了
Google 的张量处理单元(TPU)已经从最初的实验性硬件发展成了机器学习基础设施的核心组成部分。无论你是研究人员、工程师,还是对深度学习感兴趣的学生,了解 TPU 的工作原理以及如何在自己的项目中使用它们,都将为你打开新的可能性。
什么是 TPU?
- 专用加速器:TPU 是为加速矩阵运算(尤其是大规模的线性代数)而设计的 ASIC(专用集成电路)。
- 高吞吐量:相较于传统的 CPU 和 GPU,TPU 在执行大批量的张量乘法时能够提供更高的 FLOPS(每秒浮点运算次数)。
- 与 TensorFlow 紧密集成:虽然现在也支持 PyTorch、JAX 等框架,但 TensorFlow 仍是 TPU 的“原生”生态系统。
TPU 的演进
| 代数 | 发布时间 | 关键特性 |
|---|---|---|
| TPU v1 | 2016 | 仅支持 8 位整数推理,主要用于 Google Search。 |
| TPU v2 | 2017 | 引入 16 位浮点运算,支持训练和推理。 |
| TPU v3 | 2018 | 使用液体冷却,提升至 420 TFLOPS。 |
| TPU v4 | 2021 | 更高的内存带宽,支持混合精度(bfloat16)。 |
| TPU v5e | 2024 | 面向边缘计算的低功耗版本。 |
| TPU v6 | 2026(预计) | 集成 AI 加速的专用网络,支持跨区域分布式训练。 |
注:以上时间线基于公开信息和行业预测,实际发布时间可能会有所不同。
为什么在 2026 年仍然值得学习 TPU?
- 成本效益:在 Google Cloud 上使用 TPU 的计费模式已经变得更加透明,按秒计费让小规模实验也变得经济。
- 生态系统成熟:TensorFlow 2.x、JAX、以及最新的
tf.distributeAPI 已经为多 TPU 集群提供了即插即用的支持。 - 行业需求:从自然语言处理(LLM)到大规模图像生成,越来越多的企业将训练任务迁移到 TPU,以获得更快的迭代速度。
- 跨平台兼容:Google 正在推动 TPU‑Edge(如 Coral 系列)与云端 TPU 的统一编程模型,使得模型可以无缝从云端迁移到边缘设备。
如何在 Google Cloud 上启动一个 TPU 实例
下面的示例展示了使用 gcloud 命令行工具创建一个单节点 TPU(v4)的最小步骤。代码块保持原样,不进行翻译。
gcloud compute tpus tpu-vm create my-tpu \
--zone=us-central1-b \
--accelerator-type=v4-8 \
--version=tpu-vm-base以上命令会在
us-central1-b区域创建一个包含 8 块 TPU v4 芯片的虚拟机(TPU‑VM)。
在 TPU‑VM 中运行 TensorFlow 示例
# 连接到 TPU‑VM
gcloud compute tpus tpu-vm ssh my-tpu --zone=us-central1-b
# 在 VM 中克隆示例仓库
git clone https://github.com/tensorflow/models.git
cd models/official/vision/image_classification
# 安装依赖
pip install -r requirements.txt
# 使用 TPU 进行训练
python3 trainer.py \
--tpu=my-tpu \
--model_dir=gs://my-bucket/tpu-checkpoints \
--batch_size=1024 \
--train_steps=10000常见问题(FAQ)
| 问题 | 解答 |
|---|---|
| TPU 与 GPU 的主要区别是什么? | GPU 更通用,适用于图形渲染和多种并行计算;TPU 专注于张量运算,尤其在大规模矩阵乘法上更高效。 |
| 我可以在本地机器上模拟 TPU 吗? | 是的,Google 提供了 tf.experimental.dtensor 和 torch_xla 的本地模拟器,但性能与真实硬件有显著差距。 |
| 是否必须使用 TensorFlow? | 虽然 TensorFlow 是最原生的支持,但通过 torch-xla、jax 以及 tf.experimental,你可以在 PyTorch 和 JAX 中使用 TPU。 |
| 如何调试 TPU 程序? | 使用 tf.profiler、tensorboard 以及 tpu_profiler 插件可以可视化计算图和硬件利用率。 |
结论
在 2026 年,TPU 已经不再是仅限于大型科研机构的专属资源。借助 Google Cloud 的弹性计费、成熟的开发工具链以及不断扩展的边缘生态,任何人都可以在几分钟内启动并运行大规模的机器学习工作负载。无论你是想训练下一个大型语言模型,还是在边缘设备上部署实时推理,掌握 TPU 的基本概念和使用方法都将为你的 AI 项目提供强大的算力支撑。
**现在就动手尝试吧——**只需几行命令,你就能在云端体验前沿的 AI 加速技术。祝你玩得开心,模型训练顺利!
Gemini、Veo 和 Nano Banana 很惊艳,但它们只是软件。
让我们来聊聊让它们成为可能的硬件
先决条件
计算机只需要两样东西即可运行:
- Processor – 大脑
- RAM – 工作台
当你打开酷炫的 AI IDE 时:
- 应用数据从 SSD 移动到 RAM。
- 你进行某些操作。
- Processor 从 RAM 中获取 instructions。
- 它执行这些指令并将结果 back 写回 RAM。
- Video Card (GPU) 从 RAM 读取数据并在屏幕上显示。
一台计算机 可以 在没有 GPU(使用终端)的情况下工作,但 不能 在没有 CPU & RAM 的情况下工作。
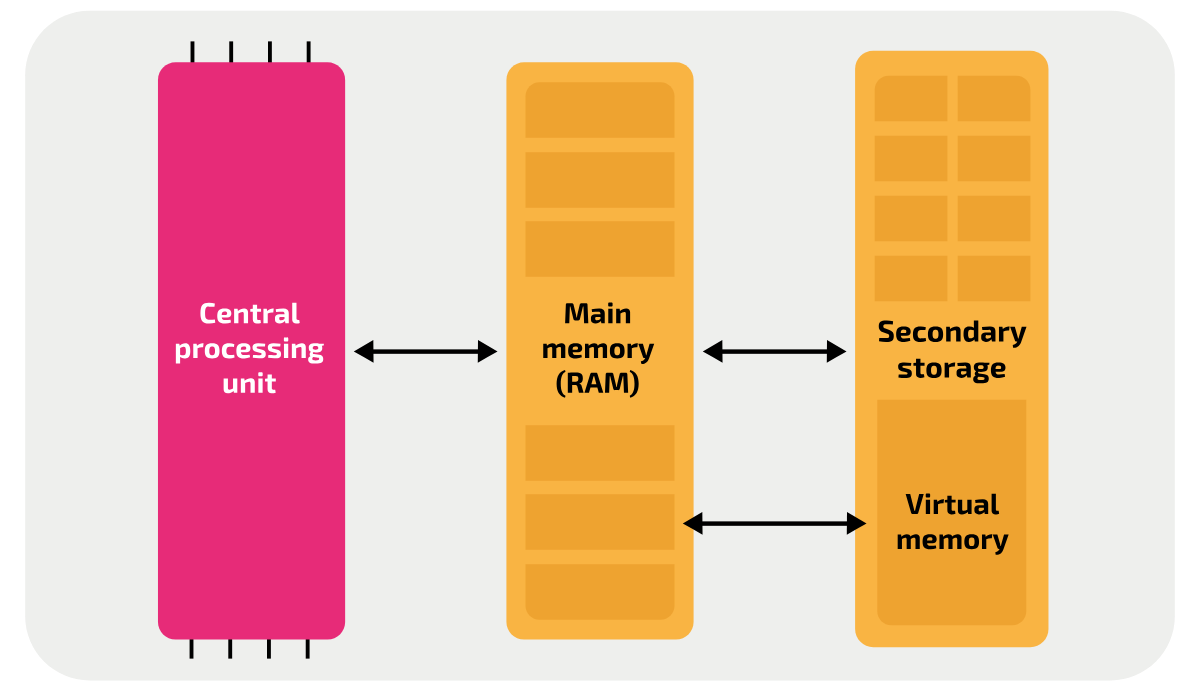
PU – Processing Unit
Processing Unit — 电子电路,根据指令对数据进行操作。物理上,它是 数十亿个晶体管 组成的逻辑门(AND、OR、NOT)。
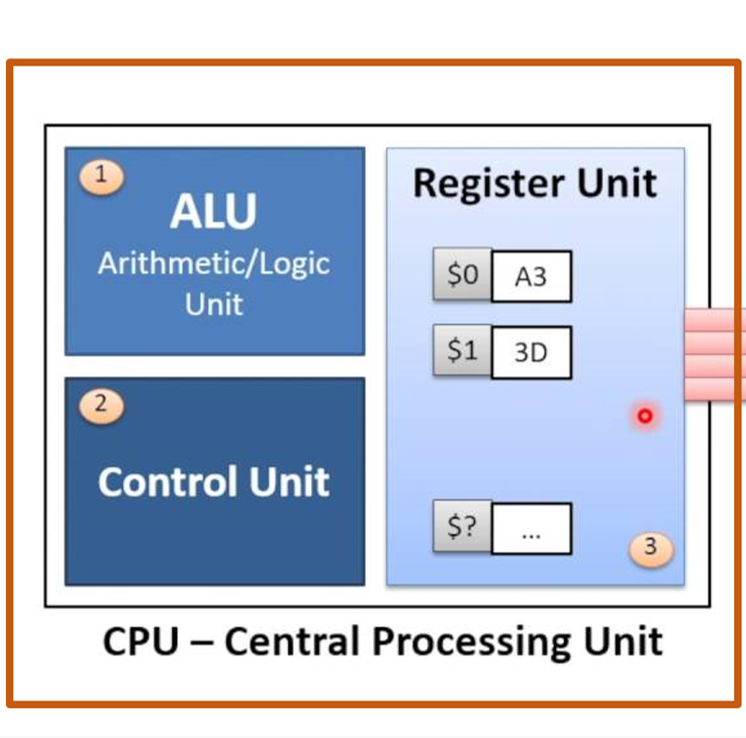
关键组件
- ALU(算术逻辑单元) – 计算器。执行数学运算(加法、乘法,……)。
- Control Unit(控制单元) – 交通警察。指挥数据流动。
- Registers / Cache – 超高速 内部存储(容量小,通常为 10–200 KB),将数据保持在靠近 ALU 的位置。
三种类型
| 类型 | 描述 | 架构 | 角色 | 座右铭 |
|---|---|---|---|---|
| CPU (中央处理器) | 通用型 | 核心少,极其复杂且智能 | 串行处理——适合逻辑、操作系统和顺序任务 | “我可以做任何事,但一次只能做一件。” |
| GPU (图形处理器) | 并行型 | 成千上万的小而简单的核心 | 并行处理——为图形和在海量数据集上同时进行的简单数学运算而设计 | “我不能运行操作系统,但我可以一次解决 10 000 道简单数学题。” |
| ASIC (专用集成电路) | 专用型 | 为单一任务定制设计 | 对特定算法实现最高效率 | “我只做一件事,但我比任何人都更快、更便宜。” |
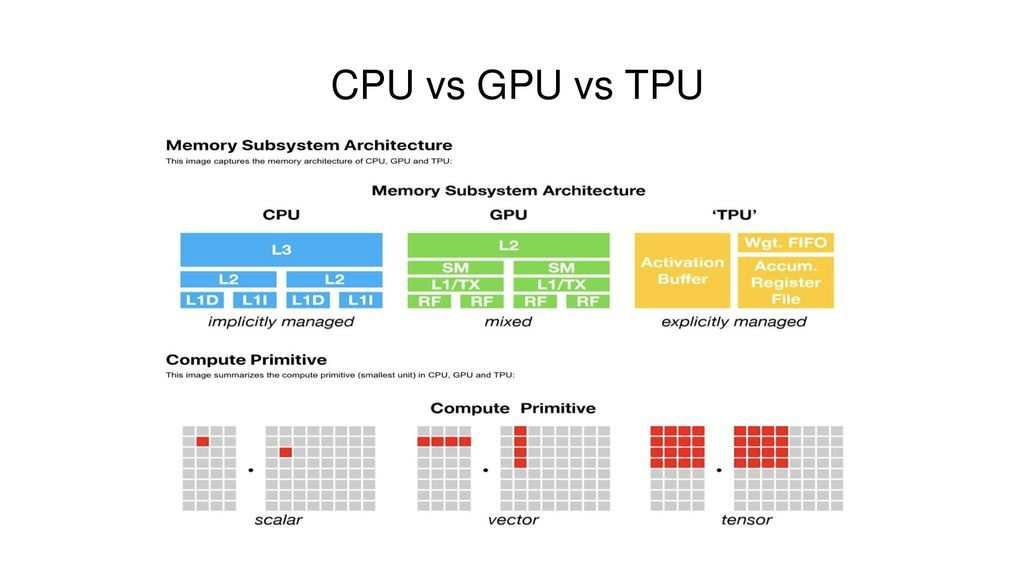
历史
在 2013 年,Google 的 Jeff Dean 和 Jonathan Ross 认识到 CPUs and GPUs 在即将到来的 AI 规模下结构上 inefficient。一个单一指标让问题变得清晰:每位用户每天三分钟的 Android 语音搜索将迫使 Google 将数据中心容量翻倍。
- 虽然 GPUs 比 CPUs faster,但它们仍携带 architectural baggage,导致在 AI 领域能效低下。
- 因此 Google 自行打造了定制硅片(ASIC)。十五个月后,TPU(Tensor Processing Unit)诞生。
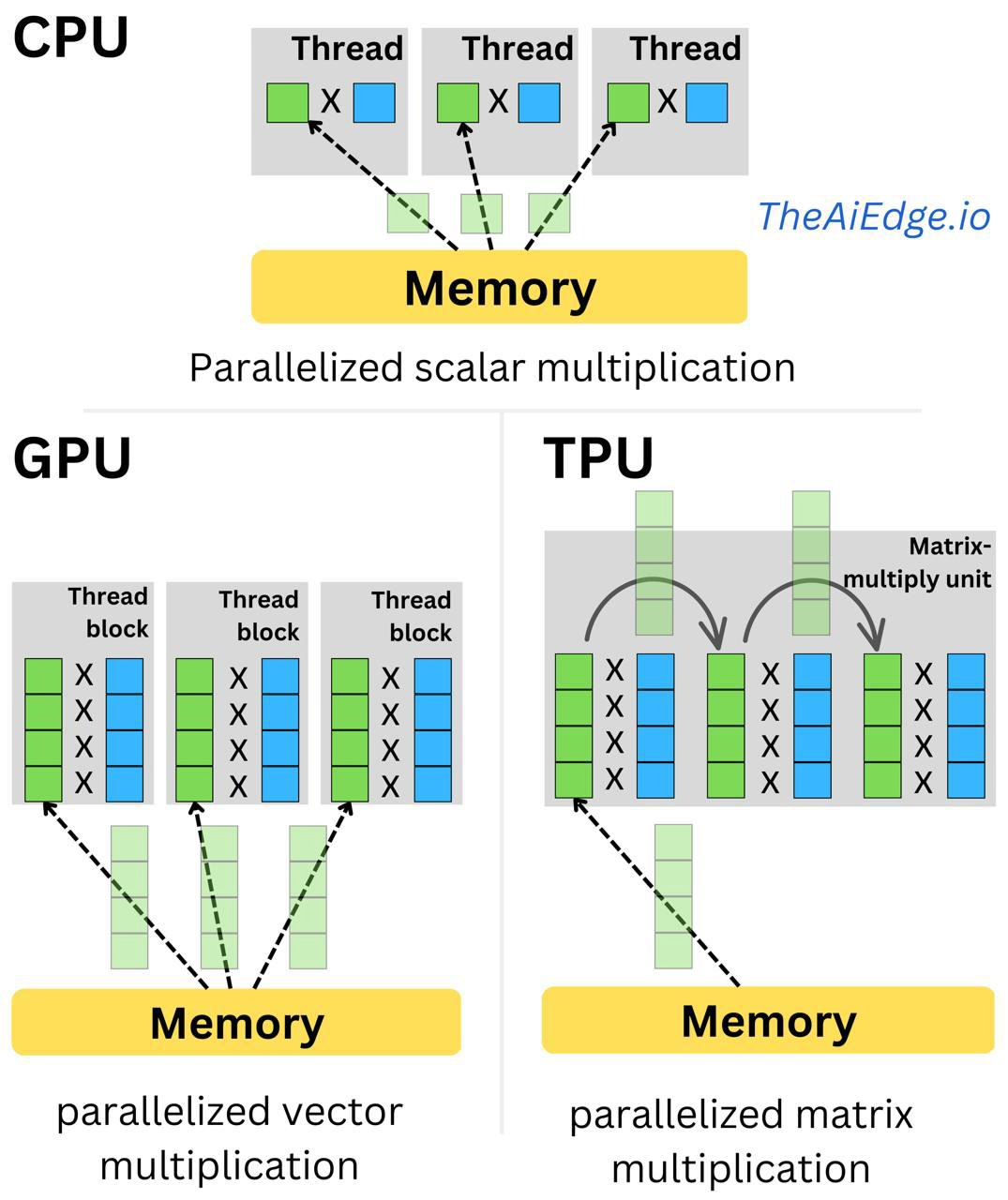
TPU vs GPU
AI 计算的主要瓶颈是 内存访问。移动数据既昂贵又慢。
经典方法(GPU/CPU)
- 从内存读取数字 A 到寄存器。
- 从内存读取数字 B 到寄存器。
- ALU 计算 A × B。
- 将结果写回内存。
芯片花在移动数据的时间比做数学运算的时间更多。
TPU 方法(Systolic Array)
- 数据只从内存 加载一次。
- 数据 流入 第一道 ALU 行。
- 每个 ALU 完成计算后直接把结果传递给下一周期的相邻单元,不 将中间结果写回内存。
- 数据以 有节奏的波动(类似心脏收缩)在整个阵列中传播。
这为矩阵乘法(AI 的核心)提供了极高的吞吐量,并显著降低功耗。
Impact
如果你想在今天创建一家 AI 初创公司,通常需要 付费 给 NVIDIA——你可以购买他们的芯片,或者几乎从任何供应商那里租用。
Google 的模型是 基于云 的。你无法购买 TPU 并自行安装 … (原文中已截断)。
# Background
Google keeps its TPUs in its own data centers and rents access exclusively through [Google Cloud TPU](https://cloud.google.com/tpu).
This allows Google to control the entire stack and avoid the “NVIDIA Tax.”
- In 2024, **Apple** released a [technical paper](https://arxiv.org/pdf/2407.21075) revealing that *Apple Intelligence* was trained on TPUs, bypassing NVIDIA entirely.
- Top AI models like **Claude** (Anthropic), **Midjourney**, and **Character.ai** rely heavily on Google because they offer better performance‑per‑dollar for massive Transformer models.背景
Google 将其 TPU 保存在自有数据中心,并仅通过 Google Cloud TPU 出租访问权限。
这使 Google 能够控制整个堆栈,避免 “NVIDIA 税”。
- 在 2024 年,Apple 发布了一篇技术论文,披露 Apple Intelligence 是在 TPU 上训练的,完全绕过了 NVIDIA。
- 顶级 AI 模型如 Claude(Anthropic)、Midjourney 和 Character.ai 在很大程度上依赖 Google,因为它们在大规模 Transformer 模型上提供了更好的 性价比。
未来
Google 在 Gemini、Nano Banana 和 Veo 上的成功不言自明。业界已经意识到,通用硬件无法在 AGI 规模 上持续使用,因此现在所有人都在尝试复制 Google 的作业:
- Microsoft 正在构建 Maia。
- Amazon 正在构建 Trainium。
- Meta 正在构建 MTIA。
然而,TPU 生态系统 并不 保证 Google 垄断或 NVIDIA 的衰落:
- Google 是竞争对手。 对于许多科技巨头来说,使用 Google Cloud 意味着帮助竞争对手完善其 AI 模型。
- NVIDIA 是通用的,且在行业基础设施中根深蒂固,难以轻易取代。
苹果
我在 Gemini 3 发布后不久写了本文的前一部分。现在 Apple 与 Google 合作其 AI,这印证了我的论点。Apple 认识到自己无法及时弥合这一差距,于是让 Google 负责 AI 运营,而自己专注于硬件销售。
许多人说这是 Apple 的一次失败,但我认为这是一种双赢局面:
- Apple 将当前最好的 AI 集成到其设备中,Google 获得收入。
- 这笔交易价值 10亿美元,暗示它可能是临时方案或在 Apple 继续训练自有模型期间的桥梁。
- 值得注意的是,Apple 并未终止与 OpenAI 的合作,但谁也说不准……
来源
- Apple‑Google AI 合作公告: CNBC
- Google 与 Apple 的联合声明: Google Blog
- Apple‑OpenAI 合作: OpenAI
