通往无处不在的AI之路 (17k tokens/sec)
Source: Hacker News
(请提供需要翻译的正文内容,我将按照要求进行简体中文翻译。)
概述
许多人认为 AI 真的很厉害。在狭窄领域,它已经超越了人类表现。若使用得当,它将成为前所未有的人类创造力和生产力的放大器。其广泛采用受到两个关键障碍的阻碍:高延迟 和 天价成本。
- 延迟 – 与语言模型的交互远远落后于人类认知的速度。编码助手可能会思考数分钟,打断程序员的思路,限制了人机协作的有效性。与此同时,自动化的代理式 AI 应用需要 毫秒级 的延迟,而不是悠闲的人类节奏的响应。
- 成本 – 部署现代模型需要巨大的工程和资本投入:占据房间大小的超级计算机消耗数百千瓦电力,配备液体冷却、先进封装、堆叠存储、复杂 I/O 和数英里的电缆。这些规模扩展到城市级的数据中心园区和卫星网络,导致极高的运营费用。
虽然社会似乎正准备构建一个由数据中心和相邻电厂定义的反乌托邦未来,但历史暗示了另一种方向。过去的技术革命往往始于丑陋的原型,随后被突破性成果所取代,产生更实用的结果。
以 ENIAC 为例:一台占据整个房间的真空管和电缆怪兽。ENIAC 向人类展示了计算的魔力,但它慢、昂贵且难以扩展。晶体管的出现推动了快速演进——从工作站和个人电脑,到智能手机和无处不在的计算——让世界摆脱了 ENIAC 的蔓延。
通用计算通过 易于构建、快速且廉价 进入主流。
AI 也需要走同样的道路。
关于 Taalas
成立于 2.5 年前,Taalas 开发了一个平台,可将任何 AI 模型转化为定制硅芯片。从收到此前未见过的模型起,仅需两个月即可实现硬件化。
由此产生的 Hardcore Models 在速度、成本和功耗上均比基于软件的实现高出一个数量级。
Taalas 的工作遵循以下核心原则:
1. 完全专用化
在计算历史中,深度专用化一直是实现关键工作负载极致效率的最可靠路径。AI 推理是人类迄今面临的最关键计算工作负载,也是最能从专用化中获益的。其计算需求推动了 完全专用化:为每个单独模型生产最优硅芯片。
2. 存储与计算的融合
现代推理硬件受到一种人为划分的限制:一侧是内存,另一侧是计算,二者的运行速度根本不同。
- 悖论 – 与标准芯片工艺兼容的存储类型相比,DRAM 密度更高(因此更便宜)。然而,访问芯片外的 DRAM 的速度比芯片内存慢数千倍。相反,计算芯片无法使用 DRAM 工艺制造。
这种划分是现代推理硬件复杂性的根源,导致需要高级封装、HBM 堆叠、巨大的 I/O 带宽、飙升的单芯片功耗以及液体冷却。
Taalas 消除了这道边界。 通过在单芯片上以 DRAM 级密度统一存储与计算,我们的架构远超以往可能实现的水平。
3. 激进简化
通过去除存储‑计算边界并为每个模型量身定制硅芯片,我们能够从第一原理重新设计整个硬件堆栈。结果是一个 不依赖困难或异构技术 的系统——无需 HBM、高级封装、3‑D 堆叠、液体冷却或高速 I/O。
工程上的简化实现了 数量级的系统整体成本降低。
早期产品
在这一技术理念的指引下,Taalas 打造了全球最快、成本/功耗最低的推理平台。

图 1:Taalas HC1 硬连 Llama 3.1 8B 模型。
今天我们推出首款产品:硬连 Llama 3.1 8B,提供 聊天机器人演示 和 推理 API 服务。
- 性能 – Taalas 的硅基 Llama 实现 每用户 17 K 令牌/秒,几乎 快 10 倍 于当前最先进水平。
- 成本 – 构建成本 低 20 倍。
- 功耗 – 能耗 低 10 倍。
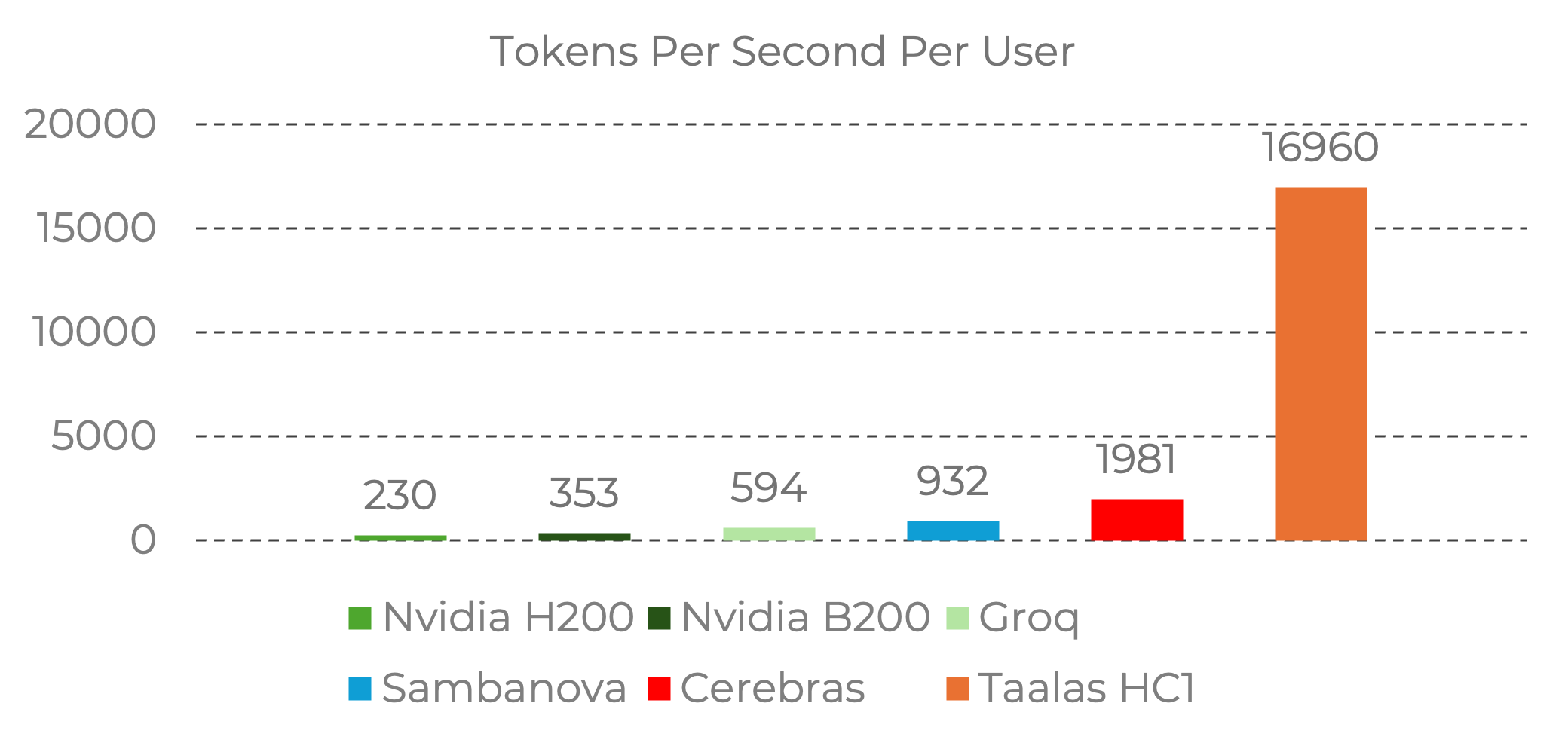
图 2:Taalas HC1 在 Llama 3.1 8B 上实现每用户令牌/秒的领先水平。
Llama 3.1 8B 的性能数据,输入序列长度 1 k/1 k。
来源:Nvidia 基准 (H200) – 由 Taalas 测量;Groq、Sambanova、Cerebras – 来自 Artificial Analysis;Taalas 性能 – 由 Taalas 实验室运行。
我们选择 Llama 3.1 8B 作为首款产品的基础,是因为它实用性强。其体积小且开源,使我们能够以最小的后勤工作对模型进行硬化。
虽然主要为速度而硬连,但 Llama 仍保留以下灵活性:
- 可配置的上下文窗口大小。
- 支持通过低秩适配器(LoRA)进行微调。
在我们开始第一代设计工作时,低精度参数格式尚未标准化。因此,首个硅平台使用了 自定义 3 位基数据类型。硅基 Llama 采用激进量化,结合 3 位和 6 位参数,这相对于 GPU 基准会导致一定的质量下降。
我们的 第二代硅平台 采用标准的 4 位浮点格式,在保持高速和高效的同时,解决了上述限制。
即将发布的模型
我们的第二代模型仍基于 Taalas 的 first‑generation architecture,将面向更大的开源模型(例如 Llama 3.1 70B),并采用全新的 4‑bit 浮点格式。该下一代硬件将进一步提升:
- Throughput – 目标是每位用户 > 30 K token / sec。
- Energy efficiency – 目标是每 token < 0.5 W。
- Scalability – 采用模块化设计,可拼接以支持多模型工作负载。
敬请期待今年晚些时候的公告。
欲了解更多信息,请访问 taalas.com 或通过 info@taalas.com 与我们联系。
t‑generation silicon platform (HC1) 将是一款中等规模的推理 LLM。预计今年春季在实验室出现,并将在随后不久集成到我们的推理服务中。
随后,将使用我们的第二代硅平台 (HC2) 制造前沿 LLM。HC2 提供显著更高的密度和更快的执行速度。部署计划在冬季进行。
即时 AI,今日掌握
我们的首个模型显然不是最前沿的,但我们仍决定将其作为 beta 服务发布——让开发者探索在亚毫秒速度和几乎零成本下进行 LLM 推理时可以实现的可能性。
我们相信我们的服务能够实现许多先前不切实际的应用场景,并希望鼓励开发者进行实验,发现这些能力的实际应用方式。
申请访问 here,并使用一个消除传统 AI 延迟和成本限制的系统。
关于实质、团队与工艺
从本质上讲,Taalas 是一个由长期合作伙伴组成的小团队,其中许多人已经合作超过二十年。为了保持精简和专注,我们依赖于那些同样具备技能并拥有数十年共享经验的外部合作伙伴。
团队的增长是缓慢的,新成员通过卓越的表现、与我们使命的一致性以及对我们既定实践的尊重而加入。在这里,实质重于表象,工艺重于规模,严谨重于冗余。
Taalas 是在一个深度技术创业公司像中世纪军队围攻城墙般——数量众多、风险资本滚滚而来、噪音喧嚣淹没清晰思考——的世界中的精准打击。
我们的第一个产品由 24 人的团队推向市场,总支出仅 3000 万美元,而融资总额超过 2 亿美元。这一成就表明,明确的目标和纪律性的专注能够实现蛮力所不能达成的成果。
展望未来,我们将以开放的方式前进。我们的 Llama 推理平台已经在您手中。未来的系统将在成熟后陆续推出。我们会提前公开,快速迭代,并接受其粗糙之处。
结论
创新始于质疑假设并进入任何解决方案空间中被忽视的角落。这正是我们在 Taalas 所选择的道路。
我们的技术在性能、能效和成本方面实现了阶跃式提升。它体现了一种与主流截然不同的架构哲学——重新定义 AI 系统的构建和部署方式。
颠覆性的进步起初往往并不熟悉,我们致力于帮助行业理解并采纳这一全新的运行范式。
我们的首批产品从硬件集成的 Llama 开始,并迅速扩展到更强大的模型,消除了高延迟和高成本——普及 AI 的核心障碍。
我们已经将即时、超低成本的智能交到开发者手中,期待看到他们用它构建的各种作品。