数据仓库不需要‘House’——这正是它更快的原因
Source: Dev.to
概述
我们知道,早期的数据库 不 区分 TP(事务处理)和 AP(分析处理);所有任务都在单一数据库中处理。
在处理 TP 业务时,确保 数据一致性 非常重要。只有当数据限制在一定范围内时,一致性才有意义,这就产生了 “基准” 的概念。
- 必须满足特定约束的数据才能加载到数据库中;否则,无法加载。
- 数据 内部 与 外部 有明确的区分——这种特性称为 闭合性。
除了保证一致性之外,闭合性在使用数据库管理系统(DBMS)时还能保证 数据安全。
从数据库到数据仓库
数据仓库是基于数据库开发的。当单一数据库无法同时满足 OLTP 和 OLAP 工作负载时,AP 工作负载会被拆分到自己的数据库中,从而产生 数据仓库。
因此,数据仓库继承了许多数据库的特性,包括 闭合性。继承闭合性意味着继承以下规则:
- “数据只有在加载到数据库后才能使用。”
- “待加载的数据必须满足特定条件。”
自然地,形成了数据仓库的 “房子” 概念。
是否需要封闭存储?
- TP业务 – 是的,封闭存储是必要的。
- 数据仓库(AP)业务 – 不一定。
虽然“data warehouse”(数据仓库)一词中包含“house”(房子),但它的主要功能是 计算。即使仓库能够像“房子”一样存储数据,它的价值也来自对这些数据的 计算。
现代数据仓库之间的竞争几乎完全围绕:
- 计算能力(性能、功能完整性、特性丰富度)。
- 存储——仅作为支持计算的手段。
因此,数据仓库的关键点是 计算,而非存储。
我们能否提供一个不绑定存储的强大计算引擎?
对于大多数 基于 SQL(关系代数)的数据仓库,答案是 否。存储与计算的绑定是这些仓库源自数据库的固有特性,无法改变。
然而,已经出现了一类新的 “no‑house” 数据仓库 确实存在——esProc SPL!
什么是 esProc?
- 一个专注于 AP 处理的 开放计算引擎。
- 能连接多种数据源并在其间执行 混合计算。
- 提供自有的高性能文件存储,以保证计算性能。
- 使用 SPL(结构化过程语言) 取代 SQL,提供相对于传统 SQL 的优势。
文中 “no house” 一词指的是 没有像传统数据仓库那样封闭、私有的存储。
Source: …
数据存储在哪里?
下面我们回答这个以及相关的问题,并探讨 “无仓库” 方法的好处(即它克服的问题)。
多源数据的实时计算
数据一旦生成,就会存放在某处——数据库、文件或网络。从广义上讲,数据已经被存储。若能 直接处理这些数据,不论它们位于何处,是不是会非常方便?
如今企业面临 多样化的数据源和类型。能够直接处理它们将带来巨大的便利。
esProc 的能力
- 开放格式、多源处理 – 无论数据位于何处(关系型数据库、NoSQL、文件、Hadoop、RESTful API 等),esProc 都可以 直接读取并计算。
- 混合计算 – esProc 能连接不同来源,并在它们之间进行跨源计算。

当具备支持多样数据源(混合计算)的能力时,“仓库”的限制被打破,带来以下优势:
- 消除 ETL 开销 – 无需在计算前将数据加载到数据库。
- 实时计算 – 保证多个源的结果始终最新。
- 降低存储成本与数据库压力 – 数据库不再被随意的数据加载所负担,这在数据仓库与 esProc 共存的早期阶段尤为有价值。
发挥各来源的优势
| 来源类型 | 优势 | esProc 的使用方式 |
|---|---|---|
| 关系型数据库 (RDBMS) | 强大的计算能力 | 在 RDBMS 中完成部分计算,然后让 esProc 完成其余部分。 |
| NoSQL / 文件 | 高 I/O 传输效率 | 在 esProc 中直接读取并计算。 |
| MongoDB | 多层次数据存储 | SPL 可以直接消费 MongoDB 数据。 |
这些好处源自 开放性。相反,封闭的数据仓库 无法计算其存储之外的数据,必须先 导入(ETL)数据,这会:
- 增加程序员工作量。
- 给数据库带来额外负载。
Summary
- 传统数据库通过 闭合性 来保证一致性和安全性。
- 数据仓库继承了这种闭合性,但对于 AP 工作负载 来说,主要价值在于 计算,而非存储。
- “无库” 架构——以 esProc SPL 为代表——将计算与存储解耦,实现 实时、多源处理,无需 ETL 的额外开销。
通过拥抱开放性,组织可以降低成本、加速开发,并充分利用每个数据源的优势。
实时数据挑战
实时数据的特性常常被忽视。外部数据通常以不规则的格式出现,难以直接加载到具有严格约束的数据库中。即使使用 ETL 过程,原始数据也必须先加载到数据库中才能利用其计算能力。因此,ETL 往往会演变为 ELT,给数据库增加额外负担。
计算可以在数据所在的任何位置进行——这正是 esProc 提供的 “无库” 方法的关键优势之一。
高性能
当 esProc 从各种数据源读取时,逻辑状态可能相同,但读取性能(从而导致整体计算时间)会因各源接口的效率不同而有所差异。某些接口(例如通过 JDBC 访问的关系型数据库)读取性能非常低。
虽然直接访问许多数据源很方便,但可能导致计算性能不佳。为保证高性能,esProc 提供了一种专用的二进制文件存储格式,并配合多种优化机制:
- 压缩
- 列式存储
- 排序
- 并行分段
注意: esProc 的文件存储是 开放 的——文件与普通文本文件、Excel 表格等一起存放在常规文件系统中。esProc 并不拥有这些文件;它仅提供优化策略,使文件访问更高效。
相比之下,传统的数据仓库存储(“闭源”)是封闭且私有的。其性能取决于底层引擎的优化器。一个好的数据库可以为简单的 SQL 选择高效的执行计划,但一旦 SQL 变得中等复杂,优化器可能失效,回退到字面执行路径,导致性能急剧下降。由于存储是封闭的,我们无法介入(例如按主键排序数据)来提升性能。
esProc 的开放文件存储具有极高的灵活性:我们可以基于任何算法设计存储布局,针对数据进行相应调整,从而实现更优的性能。
安全性与可靠性
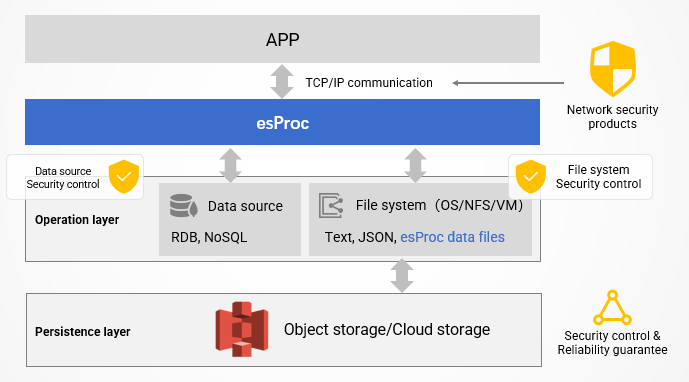
开放计算和基于文件的存储会自然引出一个问题:传统数据仓库通过其封闭特性来确保安全性和可靠性——不绑定存储的 esProc 如何保证同等水平?
答案很简单:esProc 不负责数据安全;它依赖底层数据源的安全机制。
- 数据库 提供身份验证、授权、审计等功能。
- 文件系统 / 虚拟机 提供访问控制、身份校验以及传输加密。
- 对象存储服务(例如 Amazon S3)可在计算前用于获取数据,并利用其内置的安全特性。云存储的安全性和可靠性往往优于许多本地数据库。
在应用访问方面,独立的 esProc 服务通过标准的 TCP/IP 和 HTTP 进行通信。网络安全产品可以对这些流量进行监控和防护,相关的安全措施责任由这些产品本身承担。
为什么 “无自建” 可能更安全
传统的 “自建” 数据库常常采用粗粒度的权限管理,为了便利会为所有应用用户授予高权限访问。这包括诸如编译存储过程等危险权限,削弱了整体安全性。
esProc 只专注于计算:
- 它在其他系统安全存储的数据上运行。
- 它不修改也不干涉存储层。
可靠性与安全性一样,取决于投入。即便采用昂贵的 “两地三中心” 架构,可靠性仍可能不及专业存储技术(如云对象存储)本身已经提供的水平。
实现 HTAP 需求
近年来,HTAP 已成为数据库领域的又一热点。大多数数据库仅通过在 TP 数据库上附加某些 AP 能力,或将两种技术绑定在一起实现 HTAP。无论采用何种方式,数据库迁移都是不可避免的,这会带来高风险以及原始数据仓库的封闭性和性能问题。
HTAP 需求本质上是在数据库分离后能够实时查询数据。如果具备此能力,就可以 在不修改原始 TP 数据库的前提下 实现该需求(没有迁移风险)。
我们可以在原有独立的 TP 与 AP 系统之上引入 esProc,并利用 esProc 的:
- 开放的跨源计算能力
- 高性能的存储与计算能力
- 敏捷的开发能力
来实现此需求。
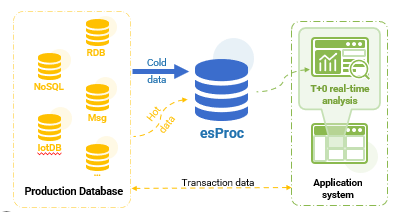
esProc 通过与现有系统协同的方式实现 HTAP。只需对现有架构进行少量修改,几乎不需要改动 TP 数据库。甚至原有的 AP 数据源仍可继续使用,esProc 可以逐步接管 AP 业务。
- 一旦部分或全部接管,历史 冷数据 将存储在 esProc 的高性能文件中。
- 将业务数据库向数据仓库迁移的原始 ETL 过程可以直接迁移到 esProc。
当冷数据量大且不再变化时,存放为 esProc 的高性能文件可获得更高的计算性能。当 热数据 量较少时,保留在原始 TP 数据源中,使 esProc 能直接读取并计算。由于热数据体积有限,对 TP 源的直接查询影响极小,延迟可接受。
通过利用 esProc 的冷热数据混合计算能力,我们实现了 全数据集的实时查询。唯一的运维任务是定期:
- 将冷数据存储为 esProc 的高性能文件。
- 将新产生的热数据保留在原始数据源中。
因此,HTAP 不仅得以实现,而且以高性能、对应用框架影响极小的方式交付。
实现真正的 Lakehouse
封闭的数据仓库无法构建真正的 Lakehouse。数据湖常被当作垃圾场:它存储各种原始数据,因为无法预测未来哪些数据会有用。数据的价值通过计算实现,而这需要数据仓库的计算能力。然而,传统数据仓库是封闭的;数据必须在加载前进行深度组织,湖中的原始“垃圾数据”无法直接计算。组织数据会丢失原始信息,并引入前文提到的多源问题。因此,实时访问无法得到保障,ETL 成本高,时效性差。
相较于在传统数据仓库上构建的伪 Lakehouse,esProc 能实现真正的 Lakehouse,因为它提供:
- 足够的开放性,直接对未组织的数据进行计算。
- 跨多数据源的混合计算能力,并通过其高性能机制保持高性能。
关键优势
- 直接计算原始湖数据——无约束,无需将数据加载到数据库。
- 多源混合计算——无论湖是基于统一文件系统还是异构源(关系型数据库、NoSQL、本地文件、Web 服务),esProc 都能即时跨它们计算。
- 高性能文件存储——esProc 的存储(数据仓库功能)可以在计算的同时有序组织数据。将原始数据转换为 esProc 的存储可获得更高性能。数据仍保留在文件系统中,可与湖一起存储,实现真正的 Lakehouse 架构。
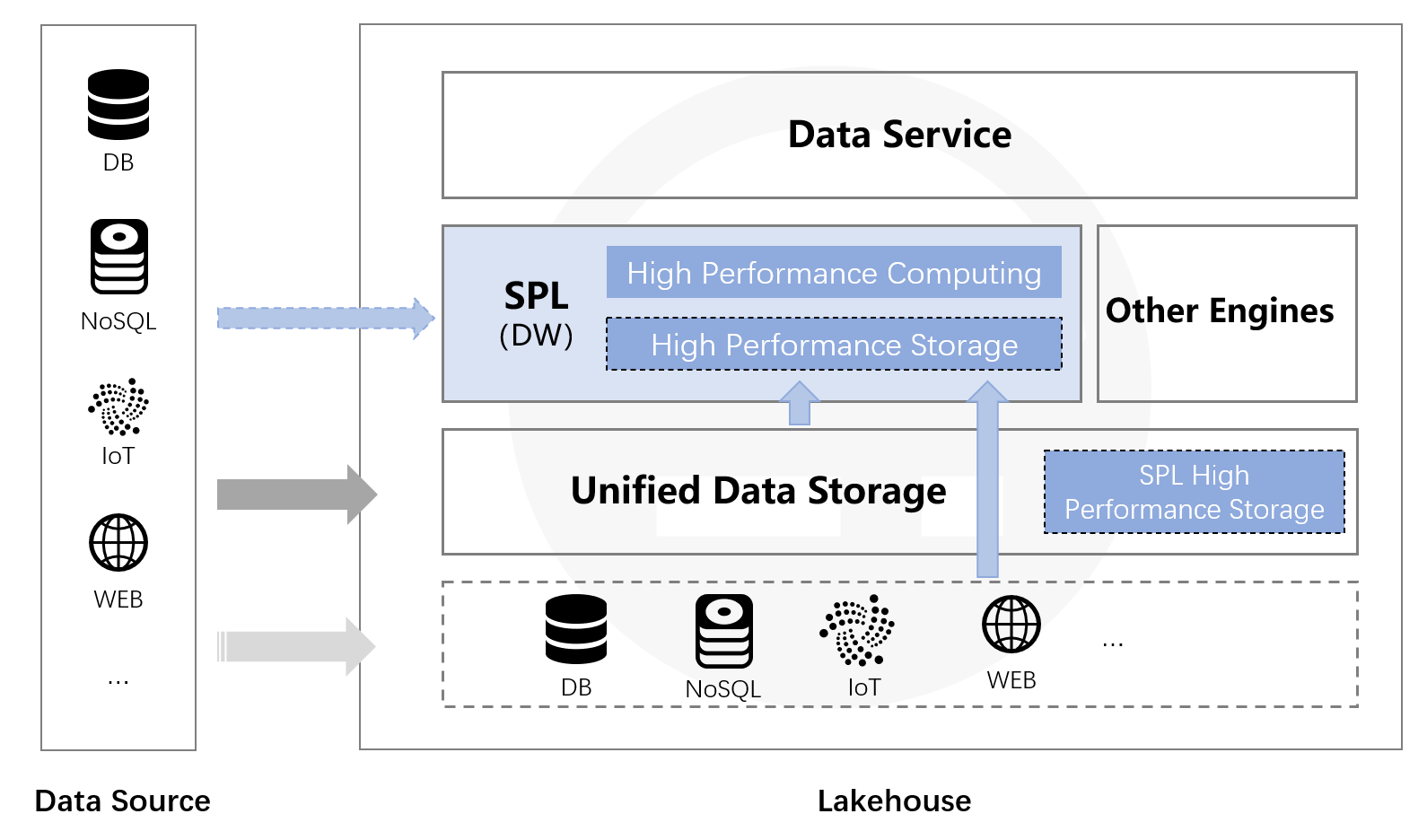
借助 esProc 的计算能力,组织与计算可以同步进行,使数据湖能够一步步有序构建。随着湖的建设,数据仓库得到细化,赋予湖强大的计算能力,从而实现真正的 Lakehouse。
从封闭到开放,这正是持续进步的体现。
esProc 和 “无屋” 数据仓库
技术的进步推动着各行各业向前发展。数据仓库也是如此:从 “有屋”(传统、本地)模型演进到 “无屋”(云原生、无服务器)模型,是现代数据仓库不可避免的阶段。因此,数据仓库即将进入 “无屋” 时代。
虽然 esProc 可能并不完美,但它代表了实现 “无屋” 数据仓库能力的重要一步,绝对值得一试。
开源可用性
SPL 现已开源。您可以从官方仓库获取源码:
免费试用
下载最新版本并开始实验:
Download esProc (free)