停止重新运行所有内容:DuckDB 中的本地增量管道
Source: Dev.to
请提供您希望翻译的具体文本内容(除代码块和 URL 之外),我将为您翻译成简体中文并保持原有的 Markdown 格式。
Source: …
增量模型 + 缓存的 DAG 运行(仅限 DuckDB)
我热爱本地优先的数据工作……直到我发现自己第 12 次这样做时:
“我改了一个模型。最好重新运行整个流水线。”
本文是一个简短的演示,展示如何使用 增量模型 和 缓存的 DAG 运行 来改掉这个习惯——全部在你的笔记本电脑上,使用 DuckDB。示例是现有 incremental_demo 项目的简化、仅限 DuckDB 的版本。
我们将进行三次运行:
- seed v1 → 初始构建
- 再次运行(未改动)→ 大部分被跳过
- seed v2(更新 + 新增行)→ 增量合并/Upsert
就这些。无需云服务。无需繁琐的流程。
用一句话概括整个演示
我们从 CSV 中种子一个小的 raw.events 表,构建一个 staging 模型,然后构建只处理 “足够新” 行(基于 updated_at)的增量事实表,并根据 event_id 应用更新。
小项目包含哪些内容
关键部分有三块:
-
两个种子快照
- v1 – 3 行。
- v2 – 将
event_id = 2的updated_at更新为更晚的时间并更改value,并新增event_id = 4。
-
源映射 – 项目定义了一个源
raw.events,指向名为seed_events的种子表。 -
若干模型(SQL + Python)
| 模型 | 类型 | 描述 |
|---|---|---|
events_base | Staging(SQL) | 将时间戳转换为正确类型,保持列整洁 |
fct_events_sql_inline | Incremental SQL(inline) | 增量逻辑直接写在模型文件中 |
fct_events_sql_yaml | Incremental SQL(YAML) | 增量配置存放在 project.yml 中 |
fct_events_py_incremental | Incremental Python(DuckDB) | 在 pandas 中添加 value_x10 列,并返回增量数据帧 |
上述所有内容都包含在导出的演示中。
仅 DuckDB 设置
演示的 DuckDB 配置文件很简单:它写入本地 DuckDB 文件。
profiles.yml(DuckDB 配置文件)
dev_duckdb:
engine: duckdb
duckdb:
path: "{{ env('FF_DUCKDB_PATH', '.local/incremental_demo.duckdb') }}".env.dev_duckdb(可选的便利设置)
FF_DUCKDB_PATH=.local/incremental_demo.duckdb
FF_DUCKDB_SCHEMA=inc_demo_schema模型(有趣的部分)
Staging: events_base
{{ config(materialized='table') }}
select
event_id,
cast(updated_at as timestamp) as updated_at,
value
from {{ source('raw', 'events') }};Incremental SQL(内联配置):fct_events_sql_inline
{{ config(
materialized='incremental',
unique_key='event_id',
incremental={ 'updated_at_column': 'updated_at' },
) }}
with base as (
select *
from {{ ref('events_base.ff') }}
)
select
event_id,
updated_at,
value
from base
{% if is_incremental() %}
where updated_at > (
select coalesce(max(updated_at), timestamp '1970-01-01 00:00:00')
from {{ this }}
)
{% endif %};它的作用
materialized='incremental'unique_key='event_id'- 水印列:
updated_at
在增量运行时,它只会选择比目标中已存在的最大 updated_at 更新的行。这假设 updated_at 在行变化时递增(仅用于演示;真实管道可能需要处理延迟到达)。
Incremental SQL(YAML‑配置风格):fct_events_sql_yaml
{{ config(materialized='incremental') }}
with base as (
select *
from {{ ref('events_base.ff') }}
)
select
event_id,
updated_at,
value
from base;project.yml 中的增量参数
models:
incremental:
fct_events_sql_yaml.ff:
unique_key: "event_id"
incremental:
enabled: true
updated_at_column: "updated_at"选择更适合你的风格。
Incremental Python(DuckDB):fct_events_py_incremental
from fastflowtransform import engine_model
import pandas as pd
@engine_model(
only="duckdb",
name="fct_events_py_incremental",
deps=["events_base.ff"],
)
def build(events_df: pd.DataFrame) -> pd.DataFrame:
df = events_df.copy()
df["value_x10"] = df["value"] * 10
return df[["event_id", "updated_at", "value", "value_x10"]]该模型的增量行为(合并/更新)在 project.yml 中配置。
Source: …
三次运行演练
我们将严格按照演示的“故事线”进行:首次构建、空操作构建,然后通过种子文件的更改触发增量更新。
步骤 0:选择本地 seeds 文件夹
Makefile 使用本地 seeds 目录,并在 v1 与 v2 之间切换 seed_events.csv。
mkdir -p .local/seeds一个仍能证明“增量”的小数据集
提供了同一 seed 文件的两个版本。v2 更新了一行已有记录并新增了一行——这样你可以看到增量模型同时完成 upsert(更新插入)和 insert(插入)操作。
seeds/seed_events_v1.csv
event_id,updated_at,value
1,2024-01-01 00:00:00,10
2,2024-01-02 00:00:00,20
3,2024-01-03 00:00:00,30seeds/seed_events_v2.csv
event_id,updated_at,value
1,2024-01-01 00:00:00,10
2,2024-01-05 00:00:00,999
3,2024-01-03 00:00:00,30
4,2024-01-06 00:00:00,40当你从 v1 切换到 v2 并再次运行时,最终应得到:
event_id = 2被更新(updated_at更新,value = 999)event_id = 4被插入(全新记录)
1️⃣ 第一次运行(seed v1 → 初始构建)
将 v1 复制到目标位置:
cp seeds/seed_events_v1.csv .local/seeds/seed_events.csv种子并运行:
FFT_SEEDS_DIR=.local/seeds fft seed . --env dev_duckdb
FFT_SEEDS_DIR=.local/seeds fft run . --env dev_duckdb你应该会看到所有模型首次物化。
2️⃣ 第二次运行(种子未变 → 空操作)
再次执行相同命令:
FFT_SEEDS_DIR=.local/seeds fft run . --env dev_duckdb所有模型应 被跳过(已缓存),因为没有任何更改。
3️⃣ 第三次运行(seed v2 → 增量合并/upsert)
换入更新后的种子文件:
cp seeds/seed_events_v2.csv .local/seeds/seed_events.csv重新种子并运行:
FFT_SEEDS_DIR=.local/seeds fft seed . --env dev_duckdb
FFT_SEEDS_DIR=.local/seeds fft run . --env dev_duckdb你会看到:
fct_events_sql_inline和fct_events_sql_yaml只处理updated_at> 已存在的最大updated_at的行。- Python 模型 (
fct_events_py_incremental) 仅接收增量行,给value乘以 10 并将结果合并回去。
检查最终表:
select * from inc_demo_schema.fct_events_sql_inline;结果:
| event_id | updated_at | value |
|---|---|---|
| 1 | 2024‑01‑01 00:00:00 | 10 |
| 2 | 2024‑01‑05 00:00:00 | 999 |
| 3 | 2024‑01‑03 00:00:00 | 30 |
| 4 | 2024‑01‑06 00:00:00 | 40 |
…and the Python model will have an extra column value_x10 with the multiplied values.
回顾
- Incremental models 只处理新行或已更改的行。
- Cached DAG runs(通过 FastFlowTransform)在没有变化时跳过工作。
- 所有这些都在本地使用 DuckDB 运行——无需云服务,也无需额外的繁琐步骤。
试一试,调整 watermark 逻辑,或实验迟到数据的处理。祝你增量建模愉快!
使用缓存选项运行 (v_duckdb)
fft run . --env dev_duckdb --cache=rw预期结果
events_base将变为普通表。- 增量模型首次创建目标表(相当于第一次完整构建)。
空操作运行(相同的 seed v1;大部分应被跳过)
fft run . --env dev_duckdb --cache=rw演示中将其称为 “空操作运行…大部分应被跳过”,这是本地数据开发中最好的体验。
更换 seed(v2 快照)并运行增量模型
# 替换 seed 文件
cp seeds/seed_events_v2.csv .local/seeds/seed_events.csv
# 加载新的 seed
FFT_SEEDS_DIR=.local/seeds fft seed . --env dev_duckdb
# 运行增量模型
fft run . --env dev_duckdb --cache=rw结果
event_id = 2带有 更新的updated_at且value = 999。event_id = 4第一次出现。
你的增量事实表应 更新 event_id = 2 的行,并 插入 event_id = 4,依据 unique_key = event_id。
在 DuckDB 中进行检查
查询增量 SQL 表
duckdb .local/incremental_demo.duckdb \
"SELECT * FROM inc_demo_schema.fct_events_sql_inline ORDER BY event_id;"在 v2 之后你应该看到:
event_id = 2,updated_at = 2024-01-05,value = 999。- 新增的
event_id = 4,updated_at = 2024-01-06,value = 40。
查询 Python 表
duckdb .local/incremental_demo.duckdb \
"SELECT * FROM inc_demo_schema.fct_events_py_incremental ORDER BY event_id;"你还应看到派生列 value_x10(例如,更新行的值为 9990)。
让 DAG 可视化
fft docs serve --env dev_duckdb --open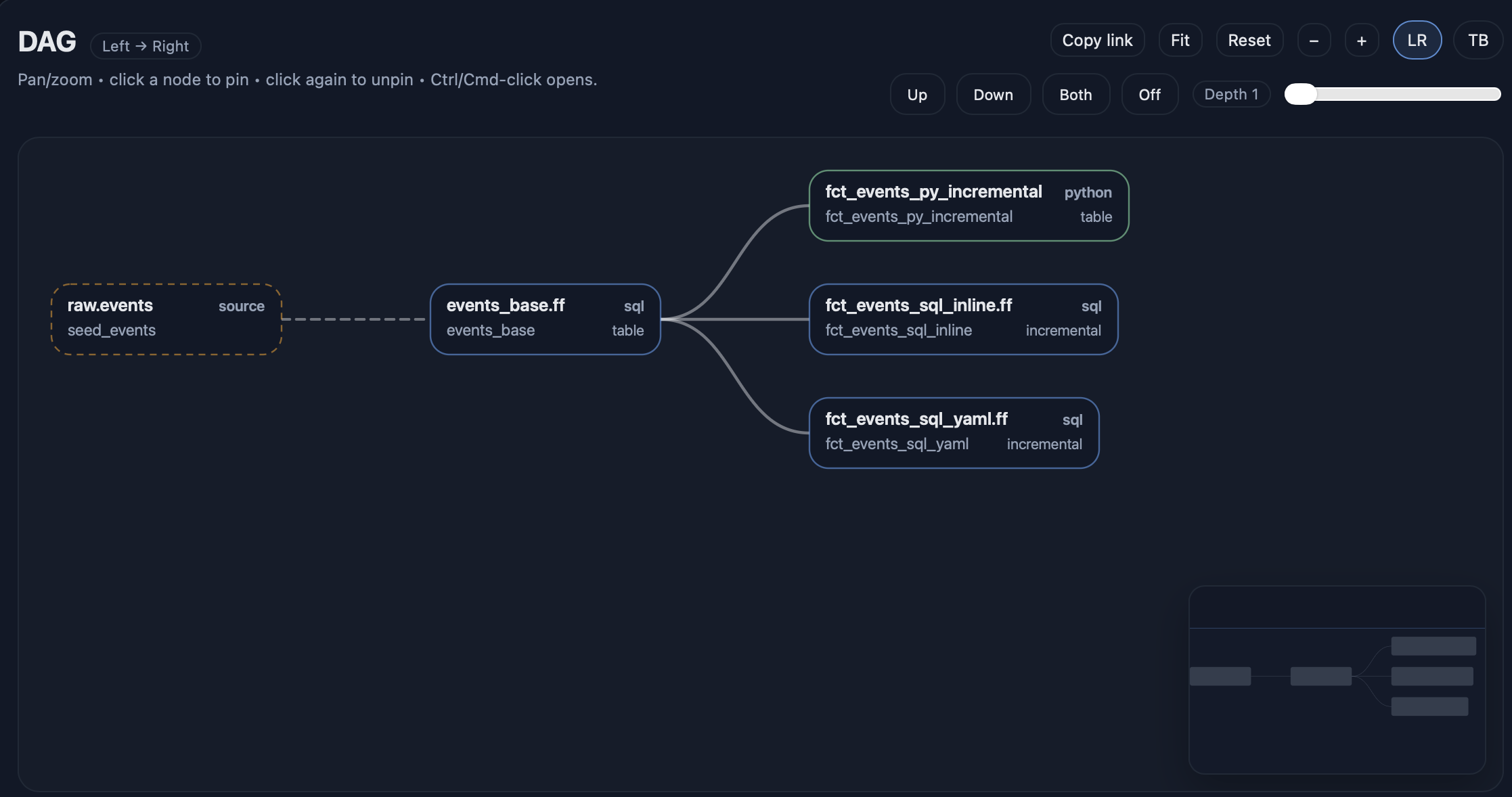
可选的简易“质量检查”
fft test . --env dev_duckdb --select tag:incremental你刚刚买下的东西
使用此设置,你的本地开发循环变为:
- 运行一次 – 构建所有内容。
- 再次运行 – 跳过大部分工作(无操作)。
- 更改输入数据 – 只更新必要的部分。
- 安全地更新已有行(通过
unique_key),而不是“追加并祈祷”。
所有这些都在单个本地 DuckDB 文件中完成,使实验既便宜又快速。