Show HN: Steerling-8B,一款能够解释它生成的任何 token 的语言模型
Source: Hacker News
Author: Guide Labs Team
Published: February 23, 2026
我们发布 Steerling‑8B,这是首个可解释模型,能够将其生成的任何 token 追溯到输入上下文、可被人类理解的概念以及其训练数据。
- 训练数据: 1.35 trillion tokens
- 性能: Comparable to models trained on 2–7 × more data
关键能力
- Concept steering at inference: 在无需重新训练的情况下抑制或放大特定概念。
- Training‑data provenance: 检索任何生成文本片段的来源数据。
- Inference‑time alignment: 直接控制概念,用明确的概念层级引导取代成千上万的安全训练示例。
模型概述
首次出现的 8 billion parameter(80 亿参数) 规模语言模型能够以三种关键方式解释它生成的每一个 token。具体而言,对于 Steerling 生成的任何一组输出 token,我们都可以追溯这些 token 的来源:
- [Input context] – 提示 token
- [Concepts] – 模型表征中人类可理解的话题
- [Training data] – 驱动输出的训练数据
产出物
我们发布了在 1.35 T token(1.35 万亿 token) 上训练的基础模型权重,以及用于交互和探索模型的配套代码。
Steerling‑8B 实际演示
下面我们展示 Steerling‑8B 在不同类别的提示下生成文本的过程。您可以选择一个示例,然后点击输出中任意高亮的片段。下方面板将更新显示:
- 输入特征归因: 哪些输入提示中的词元对该片段产生了强烈影响。
- 概念归因: 排序后的概念列表——包括语气(例如 分析型、临床型)和内容(例如 基因改造方法)——模型在生成该片段时所经过的概念。
- 训练数据归因: 该片段中的概念在训练来源(ArXiv、Wikipedia、FLAN 等)中的分布情况,展示模型知识的来源。
Loading explorer…
Source: https://www.guidelabs.ai/post/block-causal-diffusion-language-model/
模型架构
Steerling 基于一个 因果离散扩散模型 骨干构建,使我们能够在 多标记(multi‑token)跨度上引导生成,而不仅仅是下一个标记。
关键的设计选择是将模型的嵌入分解为三条显式通路:
- 约 33 K 个受监督的“已知”概念 – 在训练期间提供的策划概念。
- 约 100 K 个“发现”概念 – 模型自主学习的模式。
- 残差 – 捕获前两条通路未覆盖的其余信息。
随后我们通过训练损失函数约束模型,确保模型在 不牺牲性能 的前提下通过概念传递信号。概念通过线性路径进入 logits,因此每一次预测都恰好分解为各概念的贡献,我们可以在推理时编辑这些贡献,而无需重新训练。
有关完整的架构、训练目标以及规模分析,请参阅 Scaling Interpretable Models to 8B。
Performance
Despite being trained on significantly fewer compute resources than comparable models, Steerling‑8B achieves competitive results across standard benchmarks.
Average performance vs. training FLOPs
The scatter plot below shows the average performance (across seven benchmarks) plotted against approximate training FLOPs on a log scale. Vertical lines indicate multiples of Steerling’s compute budget.
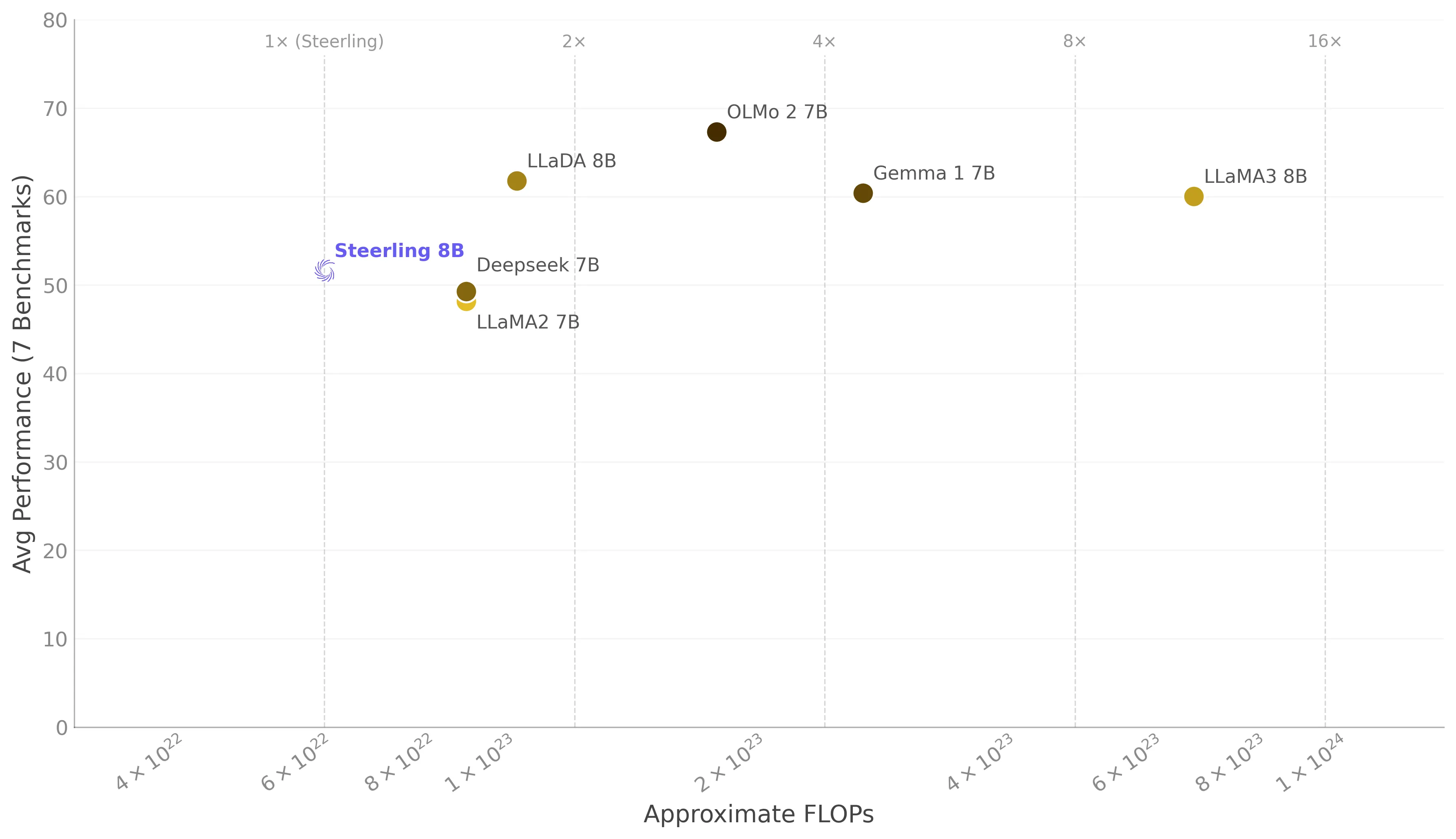
Steerling outperforms both LLaMA2‑7B and DeepSeek‑7B on overall average despite using fewer FLOPs, and remains within the range of models trained with 2–10× more compute.
Group‑average performance across task categories
The bar chart below compares group‑average scores for General and Math task categories.

Steerling’s performance spans a variety of benchmarks, from general‑purpose question answering to tasks that emphasize reasoning and mathematics.
可解释性
在上一篇更新中,我们分享了评估模型表征可解释性的几种方法。这里我们再添加一种度量,帮助了解模型对概念的使用情况。
概念模块贡献
- 在一个留出的验证集上,> 84 % 的 token 级别贡献来自概念模块。
- 这表明模型并非仅仅依赖残差路径来进行预测。
为什么重要:
如果预测真正通过概念流动,那么在推理时编辑这些概念就会实际改变模型行为,而不是仅仅在“真实工作”发生的其他通道上做微调。

在留出的验证集上,Steerling‑8B 的 token 级别 logits 分布。
残差路径消融
一个有用的合理性检查是完全移除残差路径:
- 在多个 LM‑Harness 任务上,去除残差仅对性能产生轻微影响。
- 这暗示模型的预测信号主要通过概念而非通用的“其他一切”通道传递。

在不同基准测试中,模型有无残差部分时的性能变化。
概念检测
- Steerling 能在留出的验证数据集上以 96.2 % AUC 检测文本中的已知概念。
所有数据均来源于 Steerling‑8B 模型的实验。
What this unlocks
在接下来的几周里,我们将发布对每项能力的深入探讨:
- 概念引导 – 通过干预实现精确控制。
- 概念发现 – Steerling 学到了我们没有教它的东西吗?我们将打开已发现的概念空间,展示其中令人惊讶的结构。
- 无需微调的对齐 – 用少量概念层面的干预取代成千上万的安全训练示例。
- 记忆与训练数据估值 – 将任何生成追溯到产生它的训练数据,并为单个数据源分配价值。
- 固有可解释性的案例 – 当可解释性从一开始就被设计进去时你能获得什么,以及事后再加上它时会错失什么。
我们将在后续文章中详细阐述每一点,提供量化评估和面向部署的案例研究。