第3部分:使用 Databricks 示例数据集模拟实时流式数据
发布: (2026年1月2日 GMT+8 18:48)
2 分钟阅读
原文: Dev.to
Source: Dev.to
数据集概览
我们使用 Databricks NYC Taxi 示例数据集,该数据集在 Databricks 中默认可用。
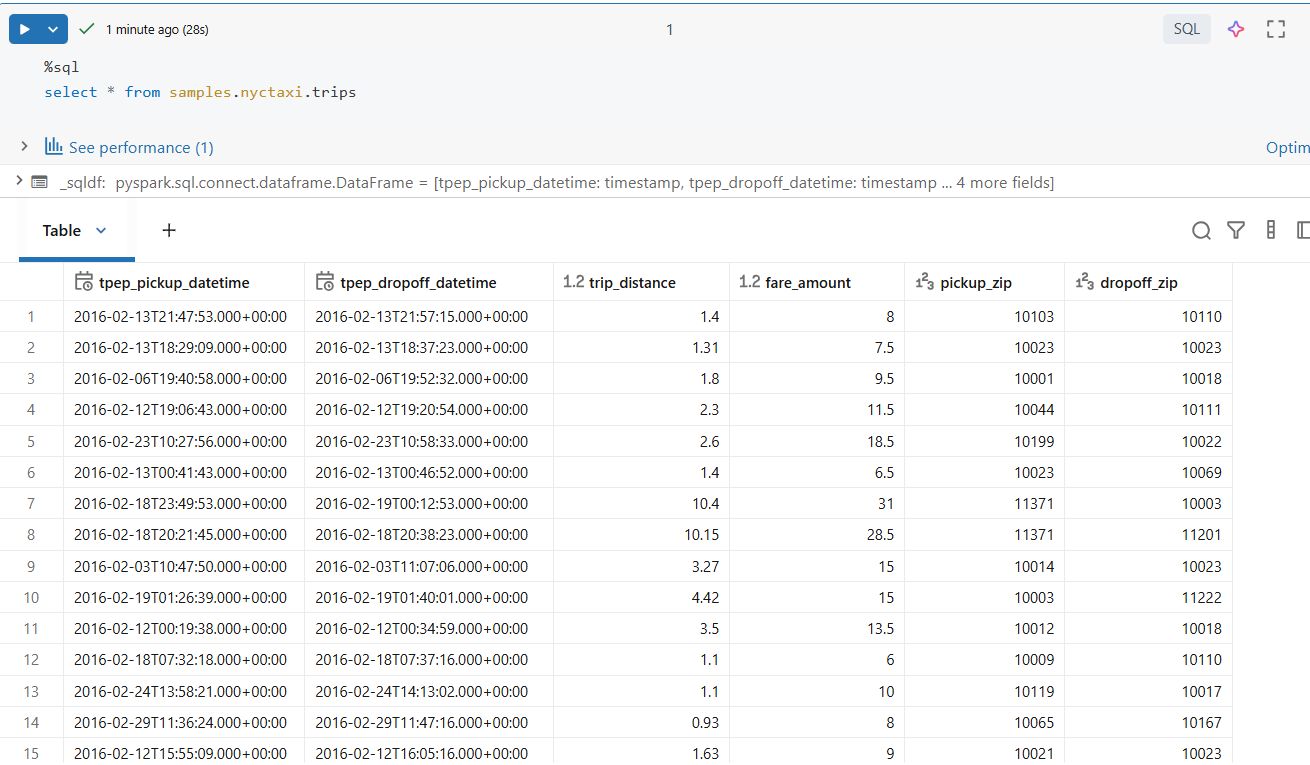
该数据集非常适合,因为它包含:
- 事件时间戳(
tpep_pickup_datetime) - 数值度量(
fare_amount、trip_distance) - 位置属性(
pickup_zip、dropoff_zip) - 足够的数据量,可以观察性能和 shuffle 行为
虽然数据集是静态的,但我们将其转换为流式来源。
将静态数据转换为流式来源
步骤 1:读取示例数据集
df = spark.table("samples.nyctaxi.trips")此时,数据是普通的批处理 DataFrame。
步骤 2:将数据写入 JSON 文件
为了模拟流式输入,我们将数据集写入 JSON 文件到一个目录:
(
df.write
.mode("overwrite")
.format("json")
.save("/tmp/taxi_stream_input")
)这会将文件写入 DBFS(Databricks 文件系统),覆盖 /tmp/taxi_stream_input 中先前存在的任何文件。该操作会创建多个 JSON 文件,每个文件代表一批即将到来的事件。
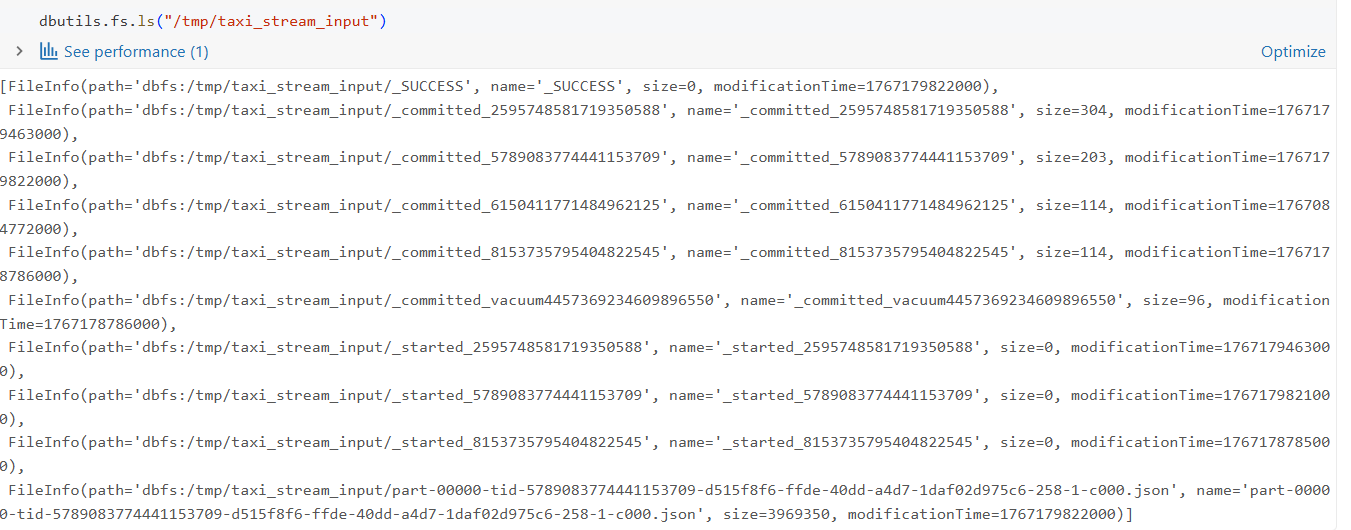
现在数据已经以文件存储的形式可供我们读取并启动流式处理!