新的 SemiAnalysis InferenceX 数据显示 NVIDIA Blackwell Ultra 在 Agentic AI 上提供高达 50 倍的性能提升和 35 倍的成本降低
Source: NVIDIA AI Blog
NVIDIA Blackwell Ultra:加速自主 AI 与编码助手
NVIDIA Blackwell 平台已经被领先的推理服务提供商广泛采用——包括 Baseten、DeepInfra、Fireworks AI 和 Together AI——将每个 token 的成本降低了最高 10× (source)。
现在,NVIDIA Blackwell Ultra 平台正将这一势头扩展到 自主 AI。
为什么自主 AI 与编码助手重要
- 爆炸性增长 的与软件编程相关的 AI 查询:去年占总 AI 流量的 11 % 到约 50 %(source)。
- 这些工作负载的需求:
- 低延迟,以实现跨多步骤工作流的实时响应。
- 长上下文窗口,以在整个代码库上进行推理。
性能突破
来自 SemiAnalysis InferenceX 的新数据展示了 NVIDIA 端到端优化的影响:
| 指标 | NVIDIA Blackwell Ultra (GB300 NVL72) | NVIDIA Hopper (baseline) |
|---|---|---|
| 每兆瓦吞吐量 | ↑ 50× | — |
| 每个 token 成本 | ↓ 35× (vs. Hopper) | — |
NVIDIA 如何实现这些提升
- 芯片级创新:下一代 Blackwell Ultra 硅片。
- 系统架构:优化的 GB300 NVL72 配置。
- 软件栈:先进的驱动、库和运行时优化。
这些协同设计的努力加速了 AI 工作负载——从自主编码代理到交互式助手——同时在大规模部署时显著降低运营成本。

Source: https://signal65.com/research/ai/from-dense-to-mixture-of-experts-the-new-economics-of-ai-inference/
GB300 NVL72 为低延迟工作负载提供高达 50 倍的性能提升
最近 Signal65 的分析显示,得益于极致的硬件‑软件协同设计,NVIDIA GB200 NVL72 能实现 >10 倍的每瓦特令牌数,即大约是 NVIDIA Hopper 平台 每令牌成本的十分之一。随着底层堆栈的成熟,这些收益仍在持续增长。
来自 TensorRT‑LLM、Dynamo、Mooncake 和 SGLang 团队的持续优化进一步提升了 Blackwell NVL72 在 专家混合(MoE)推理 场景下的吞吐量,覆盖所有延迟目标。例如,近期 TensorRT‑LLM 的改进使 GB200 在低延迟工作负载上的性能相比四个月前提升了 最高 5 倍。
关键软件进展
- 更高性能的 GPU 核心 – 为效率和低延迟调优,充分挖掘 Blackwell 大规模计算能力。
- NVIDIA NVLink 对称内存 – 实现 GPU‑到‑GPU 直接内存访问,降低通信开销。
- 程序化依赖启动 – 在前一个 kernel 完成前就开始下一个 kernel 的准备阶段,最大限度减少空闲时间。
从软件到硬件:GB300 NVL72
在这些软件改进的基础上,搭载 Blackwell Ultra GPU 的 GB300 NVL72 将 每兆瓦吞吐前沿提升至约 50 倍,相较 Hopper 平台实现了显著的经济性提升:
- 低延迟、代理型应用的每百万令牌成本降低最高可达 35 倍。
- 在整个延迟范围内保持一致的成本下降。
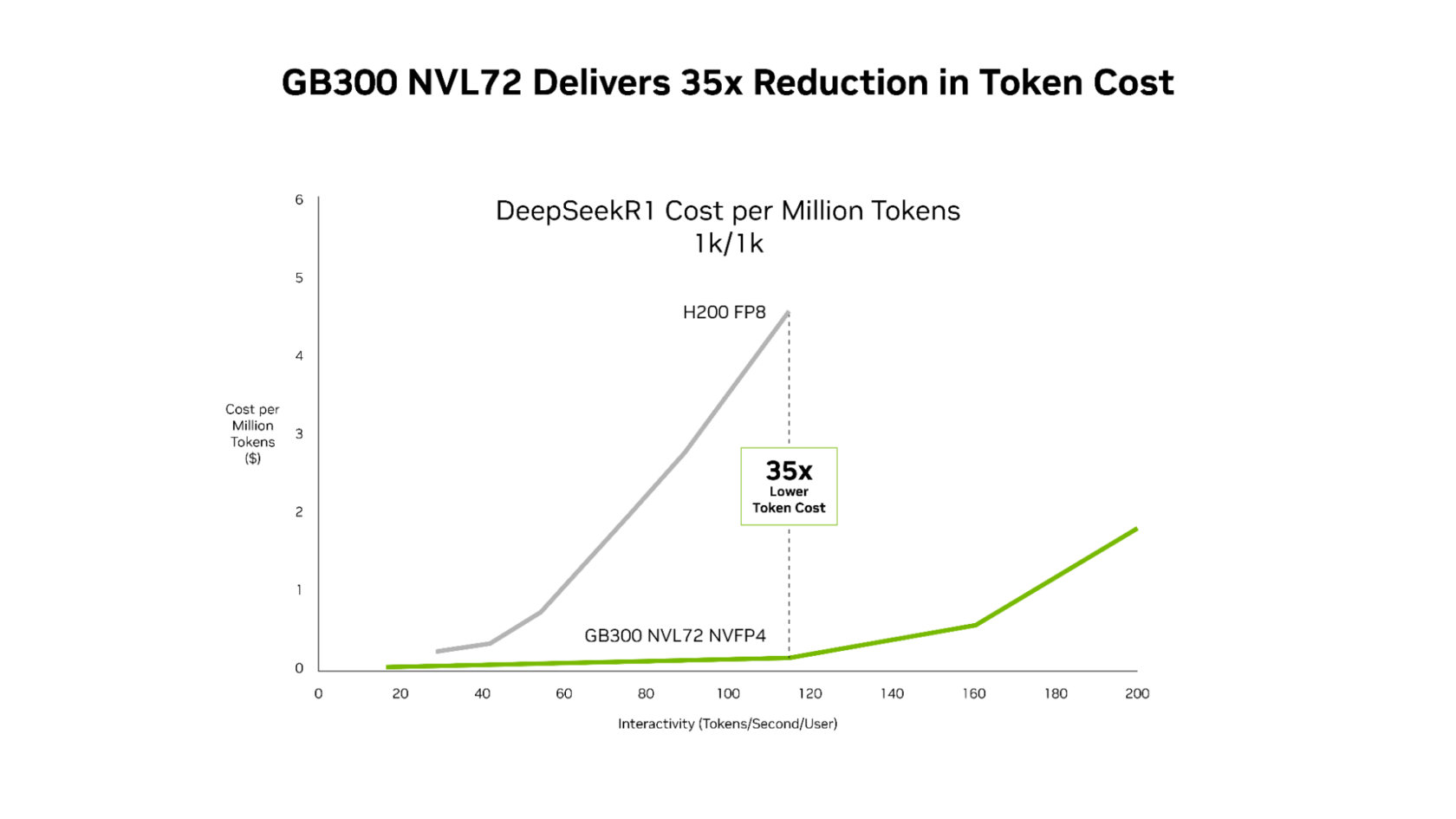
对于代理型编码和交互式助理工作负载——每毫秒的延迟在多步骤工作流中都会累计——这种持续的软件优化与下一代硬件的结合,使 AI 平台能够将实时交互体验 扩展到显著更多的用户。
Source: …
GB300 NVL72 为长上下文工作负载提供卓越的经济性
GB200 NVL72 与 GB300 NVL72 都具备超低延迟,但 GB300 NVL72 的优势在长上下文场景中最为明显。对于 128 k token 输入和 8 k token 输出 的工作负载——例如在整个代码库上进行推理的 AI 编码助手——GB300 NVL72 相比 GB200 NVL72 可实现 最高 1.5 倍的每 token 成本降低。
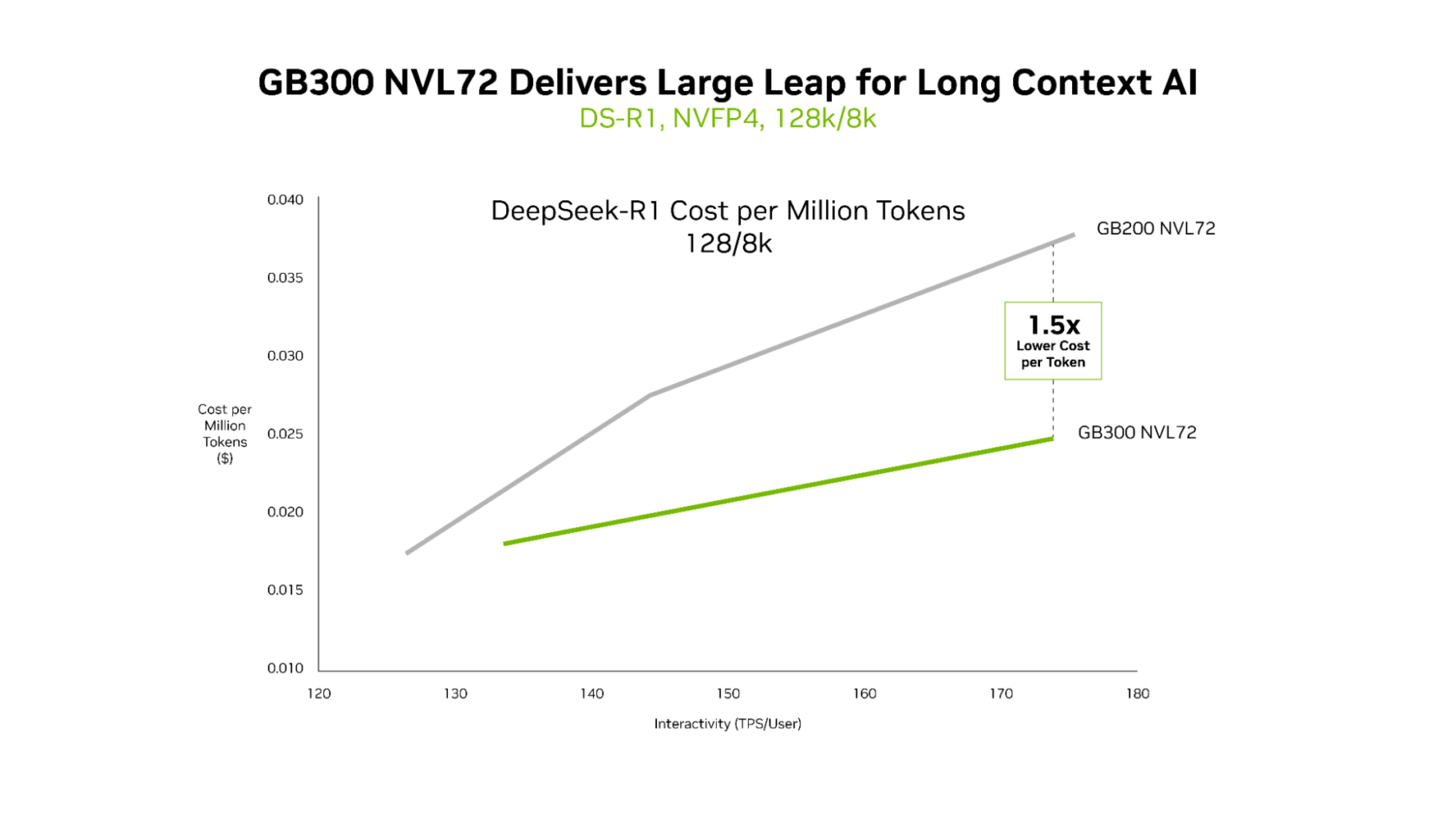
为什么 GB300 NVL72 在长上下文工作负载中表现出色
- 更大的上下文窗口 – 当代理读取更多代码时,它对代码库的理解更深入,但这也需要更多计算资源。
- 更高的计算性能 – Blackwell Ultra 提供 比前代高出 1.5 倍的 NVFP4 计算能力。
- 更快的注意力处理 – 注意力操作 提升 2 倍速度,实现对整个代码库的高效处理。
这些改进使 GB300 NVL72 成为低延迟、长上下文 AI 应用的最佳选择。
面向代理 AI 的基础设施
领先的云服务提供商和 AI 创新者已经在大规模部署了 NVIDIA GB200 NVL72,并且正在生产环境中推出 GB300 NVL72。
- Microsoft – Azure delivers the first large‑scale cluster with NVIDIA GB300 NVL72 for OpenAI workloads
- CoreWeave – Production‑ready GB300 NVL72 instances for enterprise AI (6× performance gain on DeepSeek‑R1)
- Oracle Cloud Infrastructure (OCI) – Supercluster with NVIDIA Blackwell‑dedicated alloy
这些提供商正在使用 GB300 NVL72 处理低延迟、长上下文的工作负载,例如 代理编码 和 编码助手。通过降低 token 成本,GB300 NVL72 使得能够在实时环境中跨大规模代码库进行推理的新型应用成为可能。
“随着推理成为 AI 生产的核心,长上下文性能和 token 效率变得至关重要,” Chen Goldberg,CoreWeave 工程高级副总裁 说。
“Grace Blackwell NVL72 直接解决了这一挑战,CoreWeave 的 AI 云——包括 CKS 和 SUNK——旨在将 GB300 系统的收益转化为可预测的性能和成本效率,基于 GB200 的成功实现更好的 token 经济性,为大规模运行工作负载的客户提供更易用的推理体验。”
NVIDIA Vera Rubin NVL72 带来下一代性能
随着 NVIDIA Blackwell 系统的大规模部署,持续的软件优化将不断在已装机基础上释放额外的性能和成本改进。
展望未来,NVIDIA Rubin 平台——通过组合六款新芯片打造一台 AI 超级计算机——将带来新一轮的大幅性能跃迁:
- MoE 推理: 与 Blackwell 相比,每兆瓦吞吐量提升最高可达 10 倍,相当于每百万令牌成本降低至原来的十分之一。
- 前沿 AI 训练: 大型 MoE 模型的训练所需 GPU 数量仅为 Blackwell 的四分之一。
了解更多:
- Vera Rubin NVL72 系统 – 基于 Rubin 平台构建的下一代 AI 超级计算机。