Bedrock 知识库的多租户设计:通过元数据过滤解决账户限制
Source: Dev.to
介绍
最近,在日常工作中使用 Bedrock KnowledgeBase 时,我遇到了一些与其规格相关的挑战,想在此分享。
背景
当前,我正在使用 Bedrock KnowledgeBase (KB) 开发一个多租户应用。KB 是一个用于实现 LLM RAG 的编排器,负责将文件向量化存入向量存储,并在与 Bedrock Agent 结合时生成上下文感知的对话。
我们使用 OpenSearch 作为向量存储,并且我们的设计为每个租户创建单独的 KB 和索引。这种做法确保了租户之间的数据隔离,当时看起来是一个自然的设计选择。
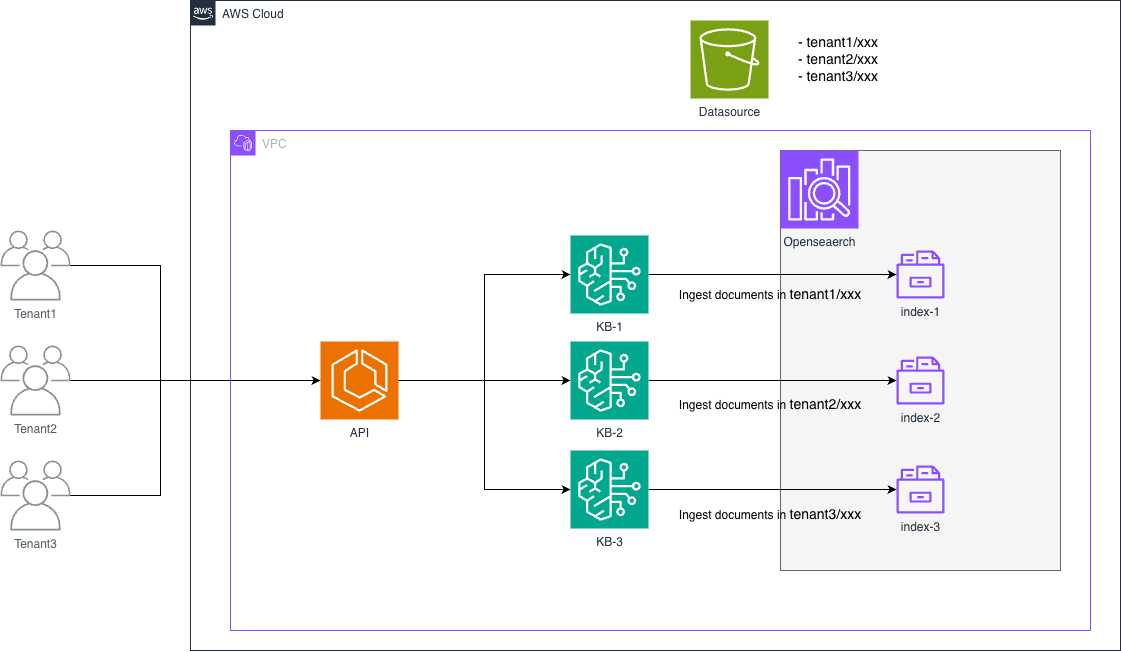
问题
在检查 Bedrock 的配额时,我发现 每个账户的知识库 配额硬性限制为 100。按照我们最初的设计,这意味着应用程序最多只能支持 100 个租户,因此我们需要重新考虑架构。
解决方案
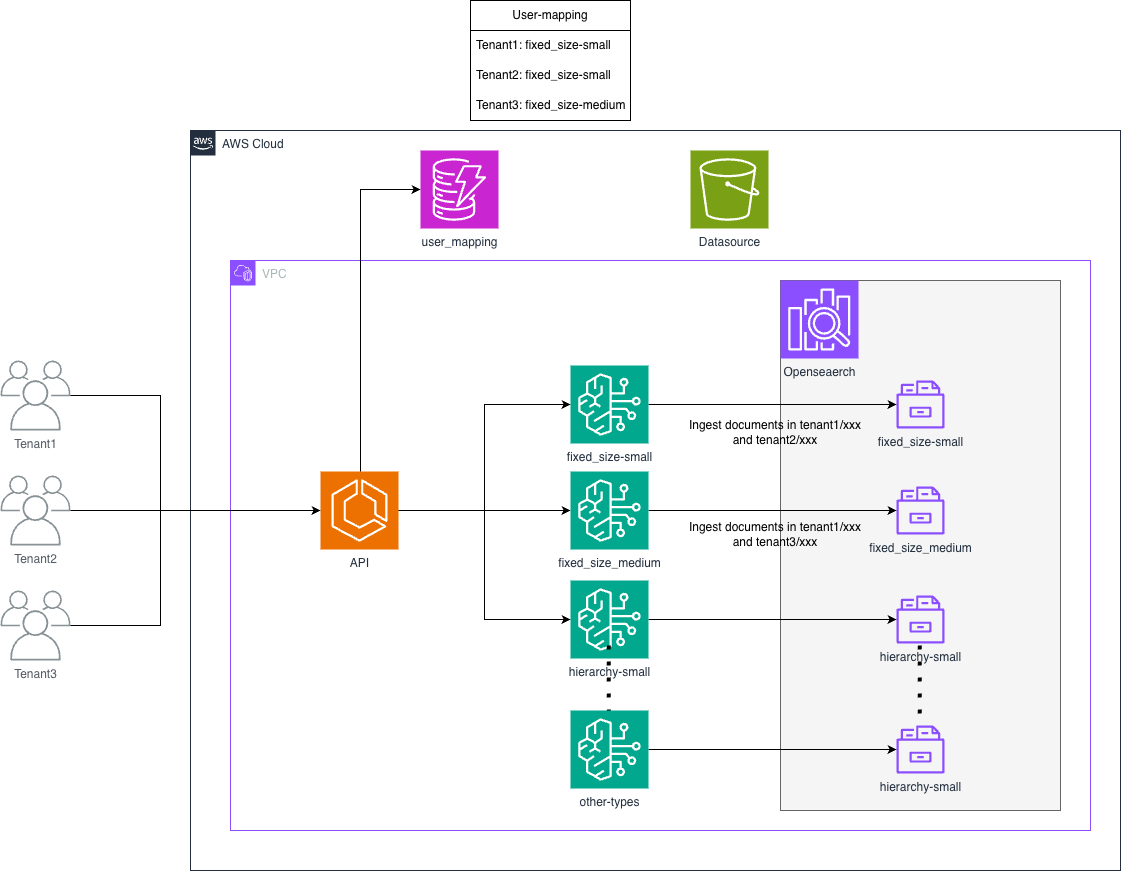
我们修改了设计,使 KB 和索引能够在多个租户之间共享。由于 KB 包含多个与向量化相关的参数(例如 ChunkStrategy),我们创建了若干 ChunkStrategy 与 MaxToken 的组合,让用户从这些选项中进行选择以实现共享。
一个重要的考虑是确保在与其他租户的对话中不会引用租户数据。KB 允许在向量化过程中附加自定义元数据,因此我们附加了类似 tenant_id 的元数据字段,并在检索时根据该 ID 过滤文档。
架构概览
- 跨多个租户的共享知识库
- 为每个文档附加自定义元数据(
tenant_id) - 检索时进行元数据过滤,以确保数据隔离
为文档附加元数据
# ingest_documents
response = client.ingest_knowledge_base_documents(
knowledgeBaseId='string',
dataSourceId='string',
clientToken='string',
documents=[
{
'metadata': {
'type': "IN_LINE_ATTRIBUTE",
'inlineAttributes': [
{
'key': 'tenant_id',
'value': {
'type': "STRING",
'stringValue': "$tenant_id",
}
},
]
},
'content': {
# document content here
}
},
]
)在调用代理时按元数据过滤文档
# invoke_agent
response = boto3.client('bedrock-agent').invoke_agent(
knowledgeBaseConfigurations=[
{
"knowledgeBaseId": "$vector_store_id",
"description": "Knowledge base for document retrieval",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"equals": {
"key": "tenant_id",
"value": "$tenant_id"
}
}
}
},
}
]
)未来计划
通过上述实现,我们现在可以在成功规避 100 KB 限制的情况下构建应用。
在多租户应用中,关键是要验证一个租户不能访问另一个租户的数据。我的计划是创建一个监控机制,具体如下:
- 创建多个测试租户。
- 为每个租户在共享向量存储中插入不同的文档。
- 使用关于其他租户文档的问题查询代理。
- 确保不返回任何答案。
在预发布环境中定期运行此脚本,可帮助检测任何意外的数据泄漏。监控系统资源(CPU、内存)固然重要,但监控数据隔离同样关键。
结论
这些是与 KB 规范相关的问题以及我们的对策。这次经历凸显了在决定系统设计之前检查云服务规范的重要性。希望本文对您有所帮助。