Mixture of Experts 为最智能的 Frontier AI 模型提供动力,在 NVIDIA Blackwell NVL72 上运行速度提升 10 倍
Source: NVIDIA AI Blog
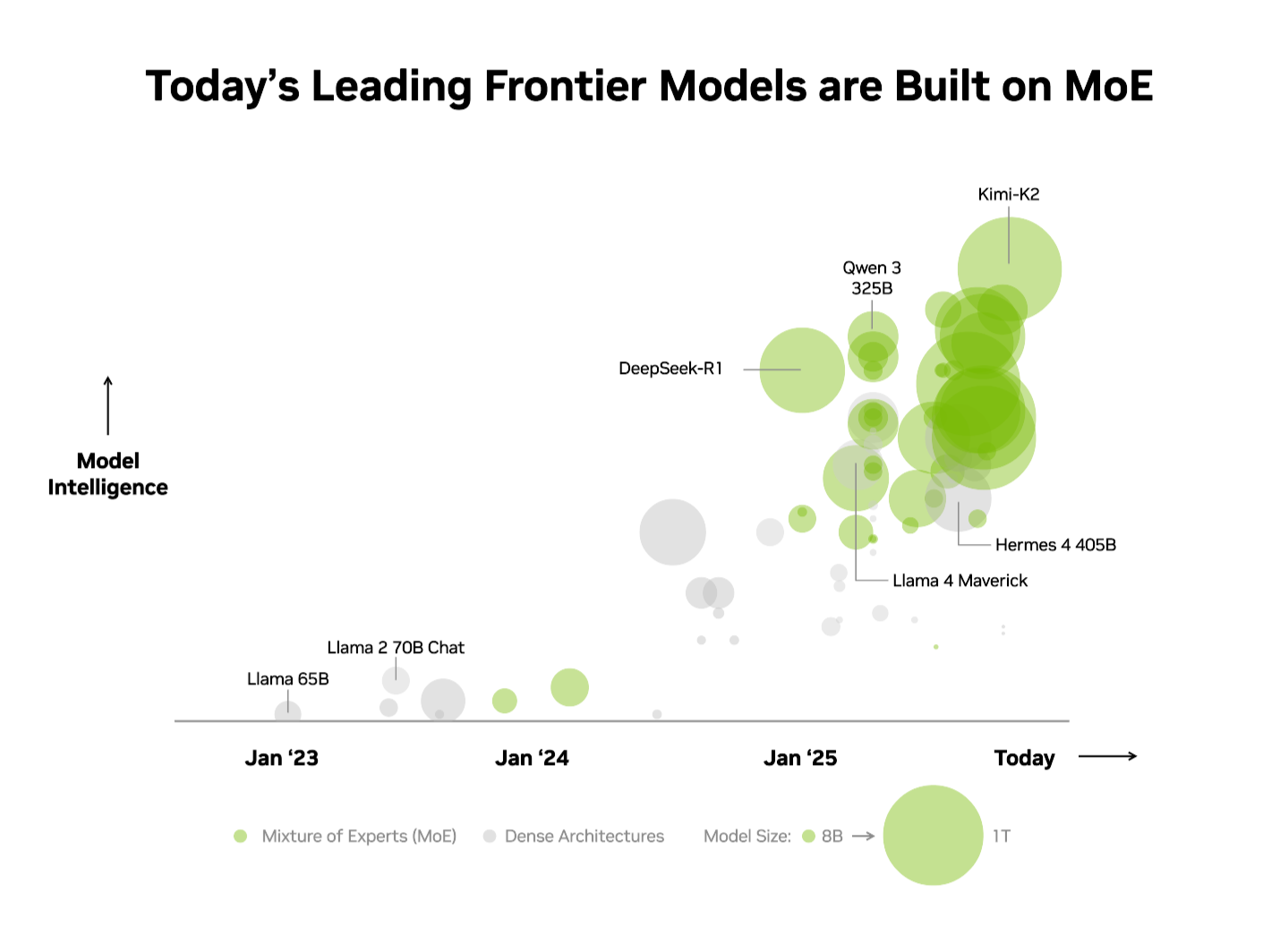
- 前十名最智能的开源模型全部采用混合专家(Mixture‑of‑Experts)架构。
- Kimi K2 Thinking、DeepSeek‑R1、Mistral Large 3 等在 NVIDIA GB200 NVL72 上的运行速度提升了 10 倍。
对当今几乎所有前沿模型进行内部观察,都会发现它们采用了混合专家(Mixture‑of‑Experts)(MoE)架构,这种架构模仿了人脑的效率。正如大脑会根据任务激活特定区域,MoE 模型将工作划分给专门的“专家”,并仅为每个AI token激活相关的专家。这使得在不成比例增加计算量的情况下,实现更快、更高效的 token 生成。
业界已经认识到这一优势。在独立的Artificial Analysis (AA) 排行榜上,前十名最智能的开源模型都使用 MoE 架构,包括 DeepSeek AI 的 DeepSeek‑R1、Moonshot AI 的 Kimi K2 Thinking、OpenAI 的 gpt‑oss‑120B 以及 Mistral AI 的 Mistral Large 3。
在生产环境中扩展 MoE 模型并保持高性能一直是极具挑战的任务。NVIDIA GB200 NVL72 系统的极致协同设计将硬件与软件优化深度结合,提供最大化的性能与效率,使得 MoE 模型的扩展既实用又简便。
Kimi K2 Thinking MoE 模型——在 AA 排行榜上被评为最智能的开源模型——在 NVIDIA GB200 NVL72 机架级系统上相较于 NVIDIA HGX H200 实现了 10 倍的性能提升。在为DeepSeek‑R1和 Mistral Large 3 MoE 模型提供的性能基础上,这一突破进一步凸显了 MoE 正成为前沿模型的首选架构——而 NVIDIA 的全栈推理平台则是释放其全部潜能的关键。
什么是 MoE,为什么它已成为前沿模型的标准?
直到最近,构建更智能 AI 的行业标准仍是构建更大、更密集的模型,这类模型会使用全部参数(如今最强大的模型往往拥有数千亿参数)来生成每个 token。虽然强大,但这种方法需要巨大的计算能力和能源,导致扩展困难。
正如人脑依赖特定区域处理不同的认知任务——无论是语言处理、物体识别还是数学求解——MoE 模型由若干专门的“专家”组成。对于任意 token,只有路由器选出的最相关专家会被激活。这种设计意味着,即使整体模型可能包含数千亿参数,生成一个 token 时只会使用其中一小部分——通常只有数百亿。
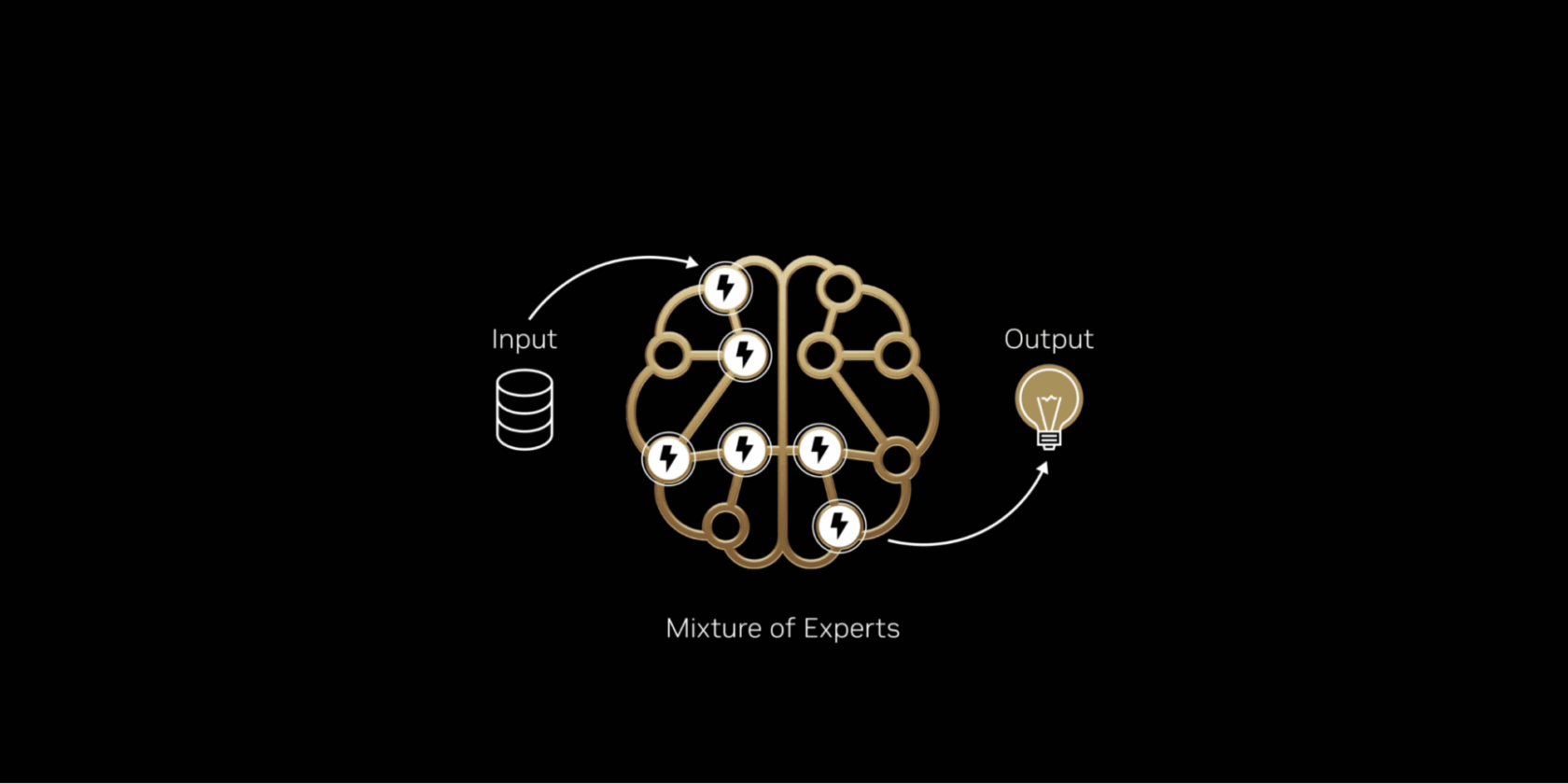
通过仅选择最关键的专家进行激活,MoE 模型在不成比例提升计算成本的前提下,实现了更高的智能性和适应性。这使得它们成为在每美元和每瓦特性能上都极具效率的 AI 系统的基石——在每单位能源和资本投入上产生显著更多的智能。
鉴于这些优势,MoE 快速成为前沿模型的首选架构也就不足为奇了。今年已有超过 60 % 的开源 AI 模型发布采用了 MoE。自 2023 年初以来,MoE 已推动模型智能提升近 70 倍——不断突破 AI 能力的极限。
“我们两年前从 Mixtral 8x7B 开始的 OSS 混合专家架构的开创性工作,确保了先进智能既可访问又可持续,适用于广泛的应用场景,”Mistral AI 联合创始人兼首席科学家 Guillaume Lample 说。“Mistral Large 3 的 MoE 架构让我们能够在提升性能和效率的同时,大幅降低能源和计算需求,实现 AI 系统的规模化。”
通过极致协同设计克服 MoE 扩展瓶颈
前沿 MoE 模型规模庞大、复杂度高,单个 GPU 无法部署。要运行它们,需要将专家分布在多 GPU 上,这一技术称为 expert parallelism(专家并行)。即便在 NVIDIA H200 这样强大的平台上,部署 MoE 模型仍会遇到以下瓶颈:
- 内存限制——对每个 token,GPU 必须从高带宽内存中动态加载被选中专家的参数,导致内存带宽压力巨大。
- 延迟——专家之间需要进行近乎瞬时的全互联(all‑to‑all)通信以交换信息并形成最终答案。在 H200 上,若专家分布在超过八块 GPU 上,就必须通过更高延迟的规模化网络进行通信,限制了专家并行的收益。
解决方案:极致协同设计
NVIDIA GB200 NVL72 是一款机架级系统,配备 72 块 NVIDIA Blackwell GPU,协同工作如同一块巨大的 GPU,提供 1.4 exaflops 的 AI 性能和 30 TB 的高速共享内存。GPU 通过 NVLink Switch 互连,形成单一的大型 NVLink 互连结构,提供 130 TB/s 的 NVLink 带宽。
MoE 模型可以利用这一设计,将专家并行的规模远远超出以往限制——最多可在 72 块 GPU 上分布专家。
这种架构直接解决了 MoE 扩展瓶颈:
- 降低每块 GPU 上的专家数量——将专家分布在多达 72 块 GPU 上,可最大程度减轻每块 GPU 高带宽内存的参数加载压力,并为更多并发用户和更长的输入序列释放内存。
- 加速专家间通信——分布在 GPU 上的专家可以通过 NVLink 实时通信。NVLink Switch 还提供计算能力,将来自不同专家的信息合并,加快最终答案的生成。
